 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplified Minimal Gated Unit Variations for Recurrent Neural Networks
Paper and Code
Jan 12, 2017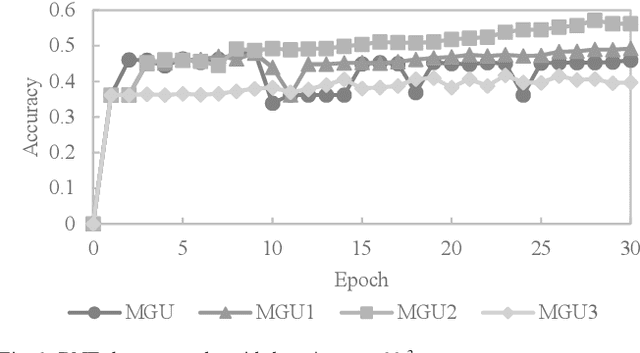

Recurrent neural networks with various types of hidden units have been used to solve a diverse range of problems involving sequence data. Two of the most recent proposals, gated recurrent units (GRU) and minimal gated units (MGU), have shown comparable promising results on example public datasets. In this paper, we introduce three model variants of the minimal gated unit (MGU) which further simplify that design by reducing the number of parameters in the forget-gate dynamic equation. These three model variants, referred to simply as MGU1, MGU2, and MGU3, were tested on sequences generated from the MNIST dataset and from the Reuters Newswire Topics (RNT) dataset. The new models have shown similar accuracy to the MGU model while using fewer parameters and thus lowering training expense. One model variant, namely MGU2, performed better than MGU on the datasets considered, and thus may be used as an alternate to MGU or GRU in recurrent neural networks.