 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoki: Representation over Architecture for Diffusion-Based Portrait Animation
May 22, 2026Portrait animation transfers a driver clip's facial expression and head pose onto a single reference image while preserving the reference's identity. State-of-the-art diffusion systems address this by stacking trained modules for expression, pose, and identity in turn, paying for it in trainable parameters, proprietary corpora, and residual entanglement between the very axes the system is meant to control independently. This complexity compensates for an upstream choice -- learning facial expression and head pose from RGB, a representation in which identity, pose, and expression are inseparable without being learned apart. Loki steps out of RGB on the conditioning path. Driver expression and head pose are encoded by a face model whose parameter axes are identity-orthogonal by construction, then rasterised into a spatial map that the diffusion backbone consumes natively. Identity is routed separately through the diffusion backbone's own pretrained features via lightweight key-value injection. Because the parametric representation factorises identity from expression and pose, cross ID reenactment reduces to a coefficient substitution at inference, requiring no cross ID training data. Loki requires ~43% fewer inference parameters than leading diffusion baselines and trained on 1496x less video samples. We define two metrics that directly measure whether the generated head pose trajectory and facial expression followed the driver's -- the questions portrait animation actually asks; Loki leads or co-leads on both.
Superpipeline: A Universal Approach for Reducing GPU Memory Usage in Large Models
Oct 11, 2024



The rapid growth in machine learning models, especially in natural language processing and computer vision, has led to challenges when running these models on hardware with limited resources. This paper introduces Superpipeline, a new framework designed to optimize the execution of large AI models on constrained hardware during both training and inference. Our approach involves dynamically managing model execution by dividing models into individual layers and efficiently transferring these layers between GPU and CPU memory. Superpipeline reduces GPU memory usage by up to 60% in our experiments while maintaining model accuracy and acceptable processing speeds. This allows models that would otherwise exceed available GPU memory to run effectively. Unlike existing solutions that focus mainly on inference or specific model types, Superpipeline can be applied to large language models (LLMs), vision-language models (VLMs), and vision-based models. We tested Superpipeline's performance across various models and hardware setups. The method includes two key parameters that allow fine-tuning the balance between GPU memory use and processing speed. Importantly, Superpipeline does not require retraining or changing model parameters, ensuring that the original model's output remains unchanged. Superpipeline's simplicity and flexibility make it useful for researchers and professionals working with advanced AI models on limited hardware. It enables the use of larger models or bigger batch sizes on existing hardware, potentially speeding up innovation across many machine learning applications. This work marks an important step toward making advanced AI models more accessible and optimizing their deployment in resource-limited environments. The code for Superpipeline is available at https://github.com/abbasiReza/super-pipeline.
Action Reimagined: Text-to-Pose Video Editing for Dynamic Human Actions
Mar 11, 2024We introduce a novel text-to-pose video editing method, ReimaginedAct. While existing video editing tasks are limited to changes in attributes, backgrounds, and styles, our method aims to predict open-ended human action changes in video. Moreover, our method can accept not only direct instructional text prompts but also `what if' questions to predict possible action changes. ReimaginedAct comprises video understanding, reasoning, and editing modules. First, an LLM is utilized initially to obtain a plausible answer for the instruction or question, which is then used for (1) prompting Grounded-SAM to produce bounding boxes of relevant individuals and (2) retrieving a set of pose videos that we have collected for editing human actions. The retrieved pose videos and the detected individuals are then utilized to alter the poses extracted from the original video. We also employ a timestep blending module to ensure the edited video retains its original content except where necessary modifications are needed. To facilitate research in text-to-pose video editing, we introduce a new evaluation dataset, WhatifVideo-1.0. This dataset includes videos of different scenarios spanning a range of difficulty levels, along with questions and text prompts. Experimental results demonstrate that existing video editing methods struggle with human action editing, while our approach can achieve effective action editing and even imaginary editing from counterfactual questions.
Revisiting Kernel Temporal Segmentation as an Adaptive Tokenizer for Long-form Video Understanding
Sep 20, 2023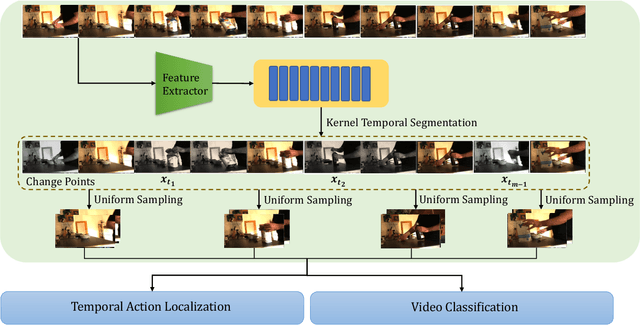
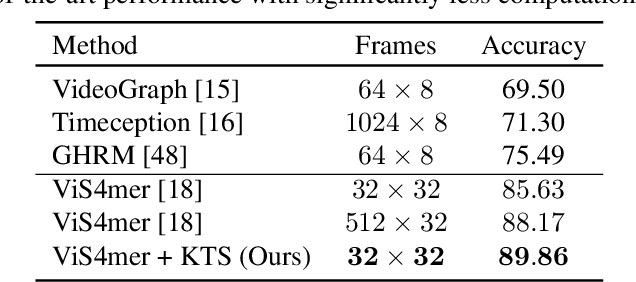
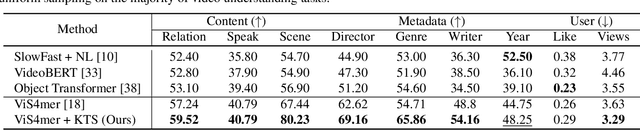
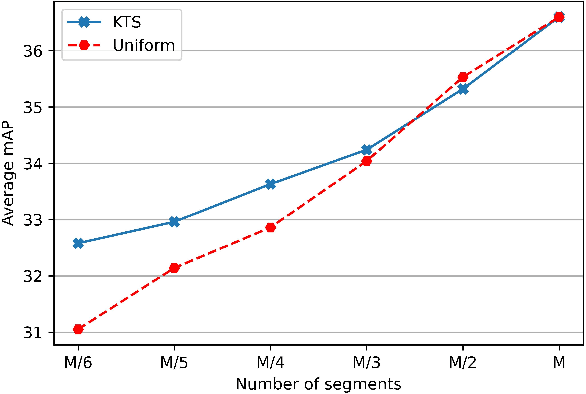
While most modern video understanding models operate on short-range clips, real-world videos are often several minutes long with semantically consistent segments of variable length. A common approach to process long videos is applying a short-form video model over uniformly sampled clips of fixed temporal length and aggregating the outputs. This approach neglects the underlying nature of long videos since fixed-length clips are often redundant or uninformative. In this paper, we aim to provide a generic and adaptive sampling approach for long-form videos in lieu of the de facto uniform sampling. Viewing videos as semantically consistent segments, we formulate a task-agnostic, unsupervised, and scalable approach based on Kernel Temporal Segmentation (KTS) for sampling and tokenizing long videos. We evaluate our method on long-form video understanding tasks such as video classification and temporal action localization, showing consistent gains over existing approaches and achieving state-of-the-art performance on long-form video modeling.