 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINOTAUR: Multi-task Video Grounding From Multimodal Queries
Paper and Code
Feb 16, 2023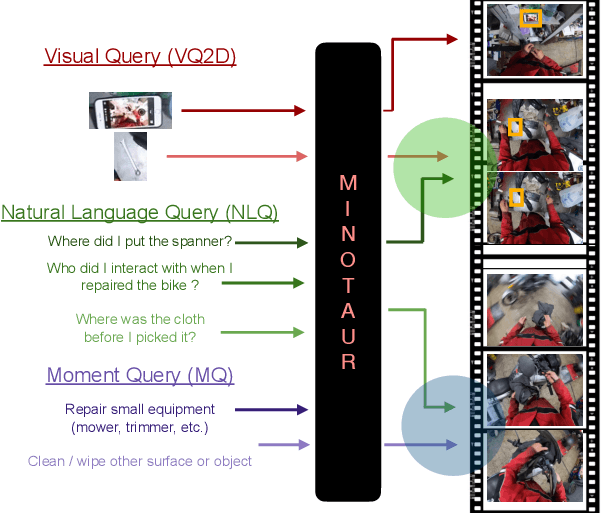

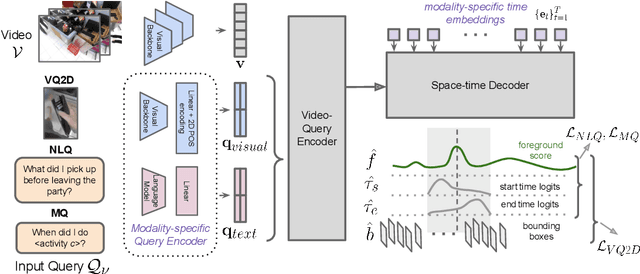
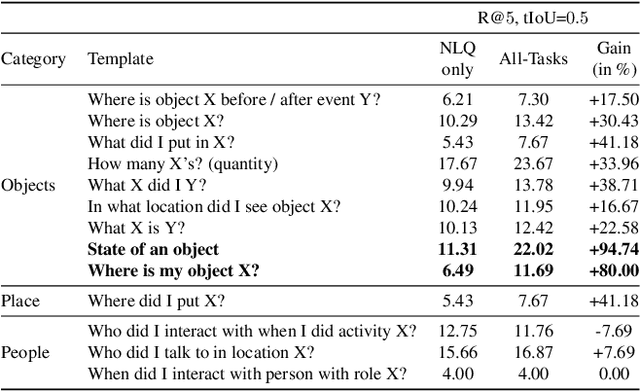
Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.