 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Spatiotemporal Convolutions for Action Recognition
Apr 12, 2018
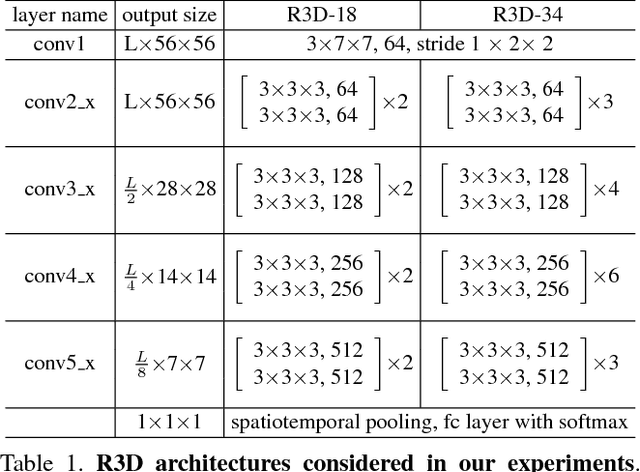
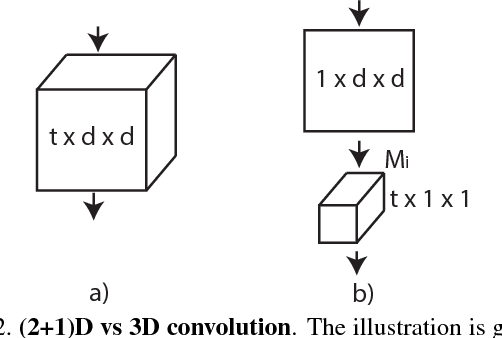

In this paper we discuss several forms of spatiotemporal convolutions for video analysis and study their effects on action recognition. Our motivation stems from the observation that 2D CNNs applied to individual frames of the video have remained solid performers in action recognition. In this work we empirically demonstrate the accuracy advantages of 3D CNNs over 2D CNNs within the framework of residual learning. Furthermore, we show that factorizing the 3D convolutional filters into separate spatial and temporal components yields significantly advantages in accuracy. Our empirical study leads to the design of a new spatiotemporal convolutional block "R(2+1)D" which gives rise to CNNs that achieve results comparable or superior to the state-of-the-art on Sports-1M, Kinetics, UCF101 and HMDB51.
ConvNet Architecture Search for Spatiotemporal Feature Learning
Aug 16, 2017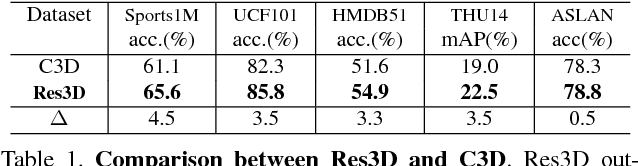



Learning image representations with ConvNets by pre-training on ImageNet has proven useful across many visual understanding tasks including object detection, semantic segmentation, and image captioning. Although any image representation can be applied to video frames, a dedicated spatiotemporal representation is still vital in order to incorporate motion patterns that cannot be captured by appearance based models alone. This paper presents an empirical ConvNet architecture search for spatiotemporal feature learning, culminating in a deep 3-dimensional (3D) Residual ConvNet. Our proposed architecture outperforms C3D by a good margin on Sports-1M, UCF101, HMDB51, THUMOS14, and ASLAN while being 2 times faster at inference time, 2 times smaller in model size, and having a more compact representation.