 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTissue Aware Nuclei Detection and Classification Model for Histopathology Images
Nov 17, 2025Accurate nuclei detection and classification are fundamental to computational pathology, yet existing approaches are hindered by reliance on detailed expert annotations and insufficient use of tissue context. We present Tissue-Aware Nuclei Detection (TAND), a novel framework achieving joint nuclei detection and classification using point-level supervision enhanced by tissue mask conditioning. TAND couples a ConvNeXt-based encoder-decoder with a frozen Virchow-2 tissue segmentation branch, where semantic tissue probabilities selectively modulate the classification stream through a novel multi-scale Spatial Feature-wise Linear Modulation (Spatial-FiLM). On the PUMA benchmark, TAND achieves state-of-the-art performance, surpassing both tissue-agnostic baselines and mask-supervised methods. Notably, our approach demonstrates remarkable improvements in tissue-dependent cell types such as epithelium, endothelium, and stroma. To the best of our knowledge, this is the first method to condition per-cell classification on learned tissue masks, offering a practical pathway to reduce annotation burden.
Self-Supervised Ranking for Representation Learning
Oct 14, 2020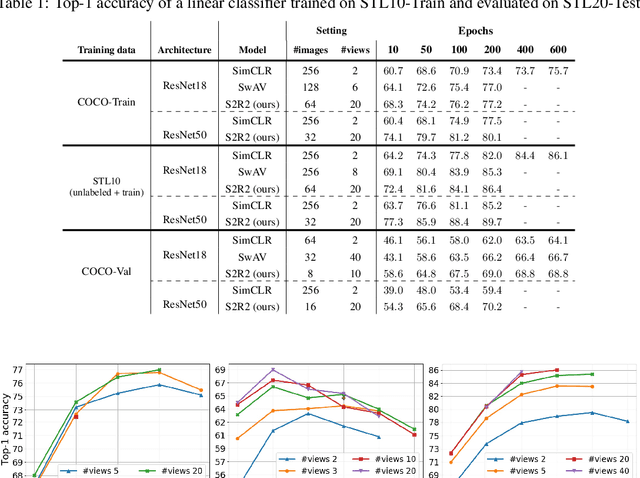
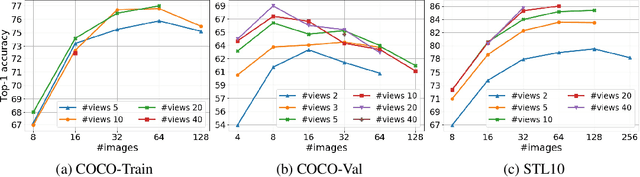
We present a new framework for self-supervised representation learning by positing it as a ranking problem in an image retrieval context on a large number of random views from random sets of images. Our work is based on two intuitive observations: first, a good representation of images must yield a high-quality image ranking in a retrieval task; second, we would expect random views of an image to be ranked closer to a reference view of that image than random views of other images. Hence, we model representation learning as a learning-to-rank problem in an image retrieval context, and train it by maximizing average precision (AP) for ranking. Specifically, given a mini-batch of images, we generate a large number of positive/negative samples and calculate a ranking loss term by separately treating each image view as a retrieval query. The new framework, dubbed S2R2, enables computing a global objective compared to the local objective in the popular contrastive learning framework calculated on pairs of views. A global objective leads S2R2 to faster convergence in terms of the number of epochs. In principle, by using a ranking criterion, we eliminate reliance on object-centered curated datasets (e.g., ImageNet). When trained on STL10 and MS-COCO, S2R2 outperforms SimCLR and performs on par with the state-of-the-art clustering-based contrastive learning model, SwAV, while being much simpler both conceptually and implementation-wise. Furthermore, when trained on a small subset of MS-COCO with fewer similar scenes, S2R2 significantly outperforms both SwAV and SimCLR. This indicates that S2R2 is potentially more effective on diverse scenes and decreases the need for a large training dataset for self-supervised learning.
MIX'EM: Unsupervised Image Classification using a Mixture of Embeddings
Jul 18, 2020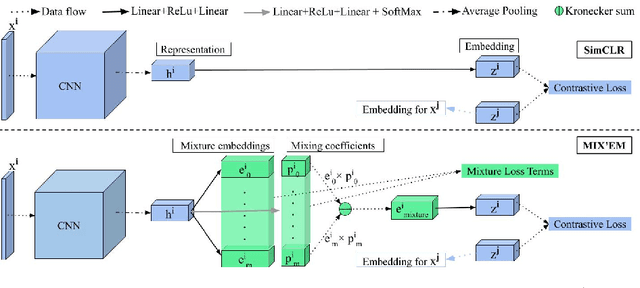
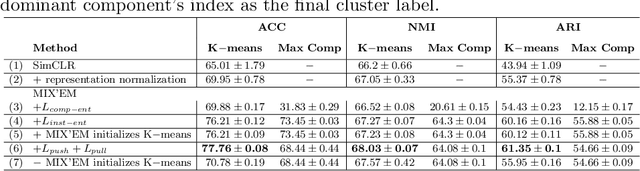
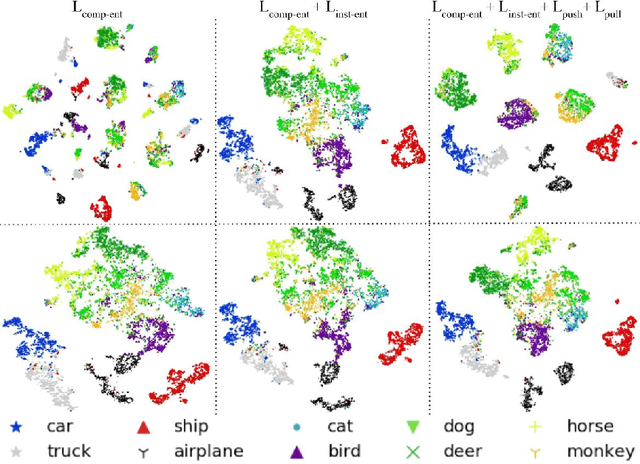
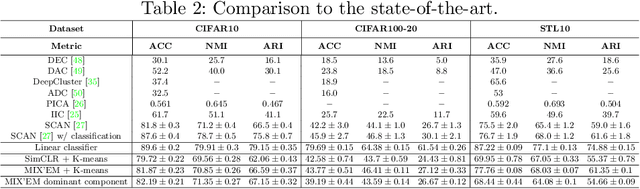
We present MIX'EM, a novel solution for unsupervised image classification. Our model generates representations that by themselves are sufficient to drive a general-purpose clustering method to deliver high-quality classification without supervision. MIX'EM integrates an internal mixture of embeddings module into the contrastive visual representation learning framework to disentangle the representation space at the category level. It generates a set of embeddings from a visual representation and mixes them to construct the contrastive loss input. Parallel to the contrastive loss, we introduce three techniques to train MIX'EM and avoid a degenerate solution; (i) we maximize entropy across mixture components to diversify them, and (ii) minimize component entropy conditioned on instances to enforce a clustered embedding space. Applying (i) and (ii) lead to the emergence of semantic categories through the mixture coefficients, making it possible to (iii) apply an associative embedding loss to enforce semantic separability directly. Subsequently, we run K-means on the representations to acquire semantic classification, which outperforms the state-of-the-art by a large margin. We conduct extensive experiments and analyses on STL10, CIFAR10, and CIFAR100-20 datasets, achieving 78\%, 82\%, and 44\% accuracy, respectively. Essential to robust high accuracy is using MIX'EM to initialize K-means. Finally, we report impressively high accuracy baselines (70\% on STL10) achieved solely by applying K-means to the "normalized" representations learned using the contrastive loss.
Mixture Dense Regression for Object Detection and Human Pose Estimation
Dec 02, 2019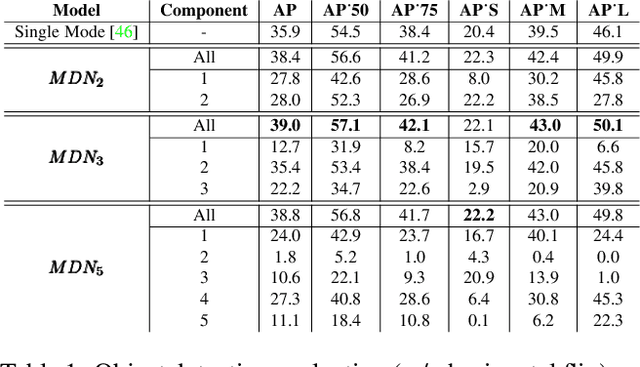
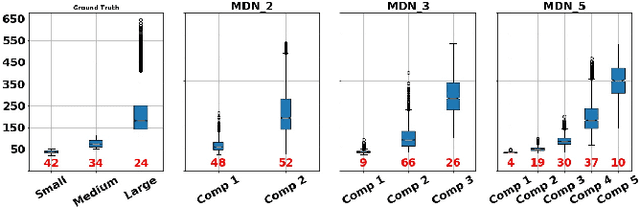
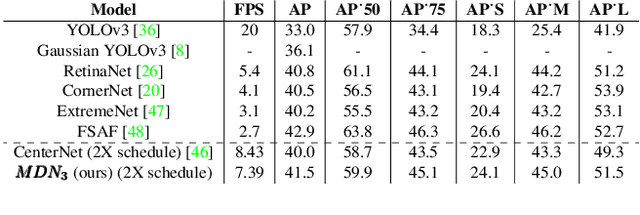
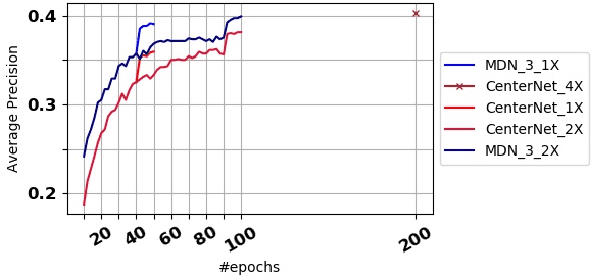
Mixture models are well-established machine learning approaches that, in computer vision, have mostly been applied to inverse or ill-defined problems. However, they are general-purpose divide-and-conquer techniques, splitting the input space into relatively homogeneous subsets, in a data-driven manner. Therefore, not only ill-defined but also well-defined complex problems should benefit from them. To this end, we devise a multi-modal solution for spatial regression using mixture density networks for dense object detection and human pose estimation. For both tasks, we show that a mixture model converges faster, yields higher accuracy, and divides the input space into interpretable modes. For object detection, mixture components learn to focus on object scale with the distribution of components closely following the distribution of ground truth object scale. For human pose estimation, a mixture model divides the data based on viewpoint and uncertainty -- namely, front and back views, with back view imposing higher uncertainty. We conduct our experiments on the MS COCO dataset and do not face any mode collapse. However, to avoid numerical instabilities, we had to modify the activation function for the mixture variance terms slightly.