 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture Dense Regression for Object Detection and Human Pose Estimation
Paper and Code
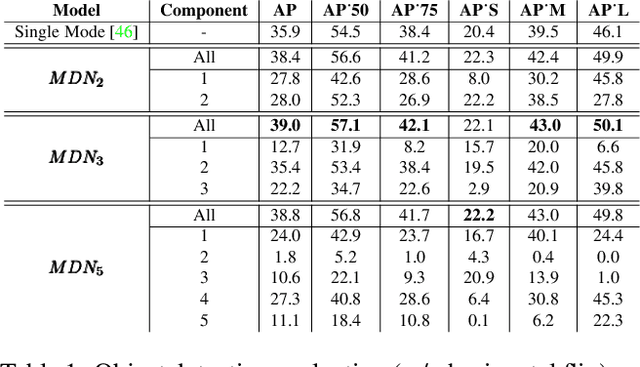
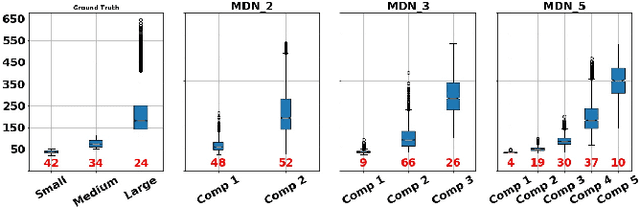
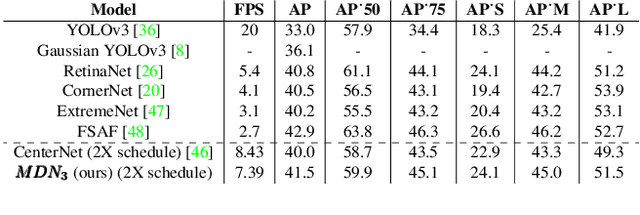
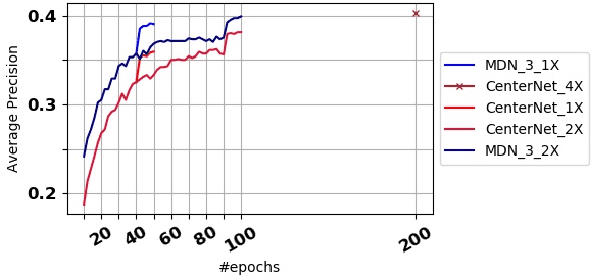
Mixture models are well-established machine learning approaches that, in computer vision, have mostly been applied to inverse or ill-defined problems. However, they are general-purpose divide-and-conquer techniques, splitting the input space into relatively homogeneous subsets, in a data-driven manner. Therefore, not only ill-defined but also well-defined complex problems should benefit from them. To this end, we devise a multi-modal solution for spatial regression using mixture density networks for dense object detection and human pose estimation. For both tasks, we show that a mixture model converges faster, yields higher accuracy, and divides the input space into interpretable modes. For object detection, mixture components learn to focus on object scale with the distribution of components closely following the distribution of ground truth object scale. For human pose estimation, a mixture model divides the data based on viewpoint and uncertainty -- namely, front and back views, with back view imposing higher uncertainty. We conduct our experiments on the MS COCO dataset and do not face any mode collapse. However, to avoid numerical instabilities, we had to modify the activation function for the mixture variance terms slightly.