 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Ranking for Representation Learning
Paper and Code
Oct 14, 2020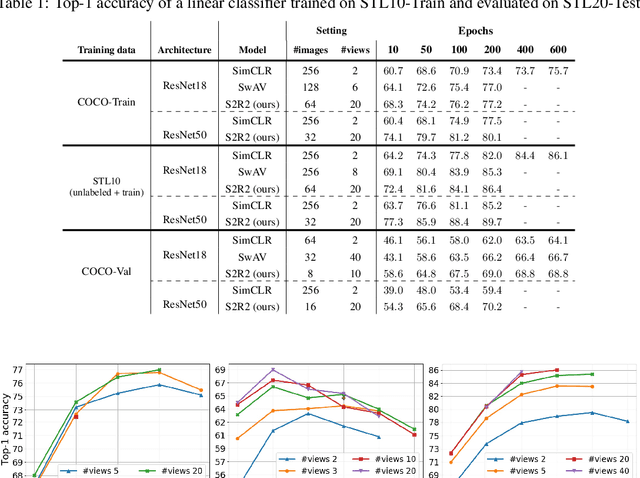
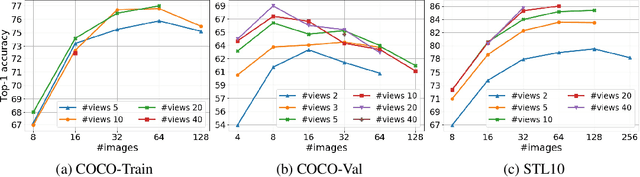
We present a new framework for self-supervised representation learning by positing it as a ranking problem in an image retrieval context on a large number of random views from random sets of images. Our work is based on two intuitive observations: first, a good representation of images must yield a high-quality image ranking in a retrieval task; second, we would expect random views of an image to be ranked closer to a reference view of that image than random views of other images. Hence, we model representation learning as a learning-to-rank problem in an image retrieval context, and train it by maximizing average precision (AP) for ranking. Specifically, given a mini-batch of images, we generate a large number of positive/negative samples and calculate a ranking loss term by separately treating each image view as a retrieval query. The new framework, dubbed S2R2, enables computing a global objective compared to the local objective in the popular contrastive learning framework calculated on pairs of views. A global objective leads S2R2 to faster convergence in terms of the number of epochs. In principle, by using a ranking criterion, we eliminate reliance on object-centered curated datasets (e.g., ImageNet). When trained on STL10 and MS-COCO, S2R2 outperforms SimCLR and performs on par with the state-of-the-art clustering-based contrastive learning model, SwAV, while being much simpler both conceptually and implementation-wise. Furthermore, when trained on a small subset of MS-COCO with fewer similar scenes, S2R2 significantly outperforms both SwAV and SimCLR. This indicates that S2R2 is potentially more effective on diverse scenes and decreases the need for a large training dataset for self-supervised learning.