 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness May Be at Odds with Fairness: An Empirical Study on Class-wise Accuracy
Paper and Code
Oct 26, 2020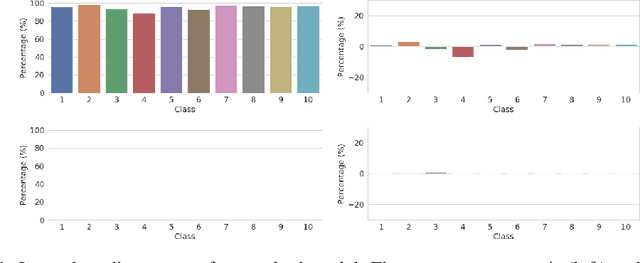

Recently, convolutional neural networks (CNNs) have made significant advancement, however, they are widely known to be vulnerable to adversarial attacks. Adversarial training is the most widely used technique for improving adversarial robustness to strong white-box attacks. Prior works have been evaluating and improving the model average robustness without per-class evaluation. The average evaluation alone might provide a false sense of robustness. For example, the attacker can focus on attacking the vulnerable class, which can be dangerous, especially, when the vulnerable class is a critical one, such as "human" in autonomous driving. In this preregistration submission, we propose an empirical study on the class-wise accuracy and robustness of adversarially trained models. Given that the CIFAR10 training dataset has an equal number of samples for each class, interestingly, preliminary results on it with Resnet18 show that there exists inter-class discrepancy for accuracy and robustness on standard models, for instance, "cat" is more vulnerable than other classes. Moreover, adversarial training increases inter-class discrepancy. Our work aims to investigate the following questions: (a) is the phenomenon of inter-class discrepancy universal for other classification benchmark datasets on other seminal model architectures with various optimization hyper-parameters? (b) If so, what can be possible explanations for the inter-class discrepancy? (c) Can the techniques proposed in the long tail classification be readily extended to adversarial training for addressing the inter-class discrepancy?