 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-Aware Location Modeling for Data Augmentation in Automotive Object Detection
Apr 23, 2025



Generative image models are increasingly being used for training data augmentation in vision tasks. In the context of automotive object detection, methods usually focus on producing augmented frames that look as realistic as possible, for example by replacing real objects with generated ones. Others try to maximize the diversity of augmented frames, for example by pasting lots of generated objects onto existing backgrounds. Both perspectives pay little attention to the locations of objects in the scene. Frame layouts are either reused with little or no modification, or they are random and disregard realism entirely. In this work, we argue that optimal data augmentation should also include realistic augmentation of layouts. We introduce a scene-aware probabilistic location model that predicts where new objects can realistically be placed in an existing scene. By then inpainting objects in these locations with a generative model, we obtain much stronger augmentation performance than existing approaches. We set a new state of the art for generative data augmentation on two automotive object detection tasks, achieving up to $2.8\times$ higher gains than the best competing approach ($+1.4$ vs. $+0.5$ mAP boost). We also demonstrate significant improvements for instance segmentation.
Gaussian Splatting is an Effective Data Generator for 3D Object Detection
Apr 23, 2025



We investigate data augmentation for 3D object detection in autonomous driving. We utilize recent advancements in 3D reconstruction based on Gaussian Splatting for 3D object placement in driving scenes. Unlike existing diffusion-based methods that synthesize images conditioned on BEV layouts, our approach places 3D objects directly in the reconstructed 3D space with explicitly imposed geometric transformations. This ensures both the physical plausibility of object placement and highly accurate 3D pose and position annotations. Our experiments demonstrate that even by integrating a limited number of external 3D objects into real scenes, the augmented data significantly enhances 3D object detection performance and outperforms existing diffusion-based 3D augmentation for object detection. Extensive testing on the nuScenes dataset reveals that imposing high geometric diversity in object placement has a greater impact compared to the appearance diversity of objects. Additionally, we show that generating hard examples, either by maximizing detection loss or imposing high visual occlusion in camera images, does not lead to more efficient 3D data augmentation for camera-based 3D object detection in autonomous driving.
Generative Location Modeling for Spatially Aware Object Insertion
Oct 17, 2024



Generative models have become a powerful tool for image editing tasks, including object insertion. However, these methods often lack spatial awareness, generating objects with unrealistic locations and scales, or unintentionally altering the scene background. A key challenge lies in maintaining visual coherence, which requires both a geometrically suitable object location and a high-quality image edit. In this paper, we focus on the former, creating a location model dedicated to identifying realistic object locations. Specifically, we train an autoregressive model that generates bounding box coordinates, conditioned on the background image and the desired object class. This formulation allows to effectively handle sparse placement annotations and to incorporate implausible locations into a preference dataset by performing direct preference optimization. Our extensive experiments demonstrate that our generative location model, when paired with an inpainting method, substantially outperforms state-of-the-art instruction-tuned models and location modeling baselines in object insertion tasks, delivering accurate and visually coherent results.
Object-Centric Diffusion for Efficient Video Editing
Jan 11, 2024



Diffusion-based video editing have reached impressive quality and can transform either the global style, local structure, and attributes of given video inputs, following textual edit prompts. However, such solutions typically incur heavy memory and computational costs to generate temporally-coherent frames, either in the form of diffusion inversion and/or cross-frame attention. In this paper, we conduct an analysis of such inefficiencies, and suggest simple yet effective modifications that allow significant speed-ups whilst maintaining quality. Moreover, we introduce Object-Centric Diffusion, coined as OCD, to further reduce latency by allocating computations more towards foreground edited regions that are arguably more important for perceptual quality. We achieve this by two novel proposals: i) Object-Centric Sampling, decoupling the diffusion steps spent on salient regions or background, allocating most of the model capacity to the former, and ii) Object-Centric 3D Token Merging, which reduces cost of cross-frame attention by fusing redundant tokens in unimportant background regions. Both techniques are readily applicable to a given video editing model \textit{without} retraining, and can drastically reduce its memory and computational cost. We evaluate our proposals on inversion-based and control-signal-based editing pipelines, and show a latency reduction up to 10x for a comparable synthesis quality.
ResQ: Residual Quantization for Video Perception
Aug 18, 2023



This paper accelerates video perception, such as semantic segmentation and human pose estimation, by levering cross-frame redundancies. Unlike the existing approaches, which avoid redundant computations by warping the past features using optical-flow or by performing sparse convolutions on frame differences, we approach the problem from a new perspective: low-bit quantization. We observe that residuals, as the difference in network activations between two neighboring frames, exhibit properties that make them highly quantizable. Based on this observation, we propose a novel quantization scheme for video networks coined as Residual Quantization. ResQ extends the standard, frame-by-frame, quantization scheme by incorporating temporal dependencies that lead to better performance in terms of accuracy vs. bit-width. Furthermore, we extend our model to dynamically adjust the bit-width proportional to the amount of changes in the video. We demonstrate the superiority of our model, against the standard quantization and existing efficient video perception models, using various architectures on semantic segmentation and human pose estimation benchmarks.
Delta Distillation for Efficient Video Processing
Mar 17, 2022
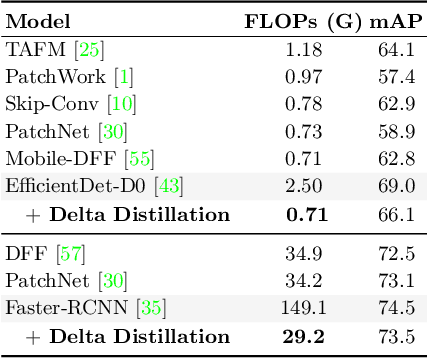

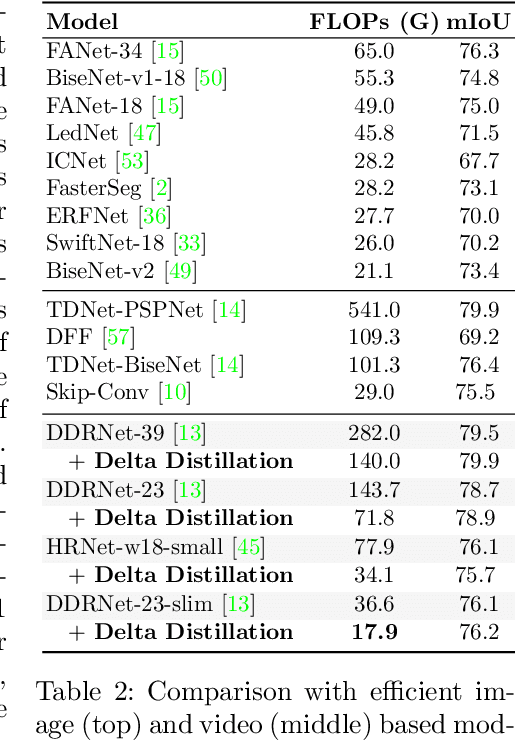
This paper aims to accelerate video stream processing, such as object detection and semantic segmentation, by leveraging the temporal redundancies that exist between video frames. Instead of propagating and warping features using motion alignment, such as optical flow, we propose a novel knowledge distillation schema coined as Delta Distillation. In our proposal, the student learns the variations in the teacher's intermediate features over time. We demonstrate that these temporal variations can be effectively distilled due to the temporal redundancies within video frames. During inference, both teacher and student cooperate for providing predictions: the former by providing initial representations extracted only on the key-frame, and the latter by iteratively estimating and applying deltas for the successive frames. Moreover, we consider various design choices to learn optimal student architectures including an end-to-end learnable architecture search. By extensive experiments on a wide range of architectures, including the most efficient ones, we demonstrate that delta distillation sets a new state of the art in terms of accuracy vs. efficiency trade-off for semantic segmentation and object detection in videos. Finally, we show that, as a by-product, delta distillation improves the temporal consistency of the teacher model.
Region-of-Interest Based Neural Video Compression
Mar 03, 2022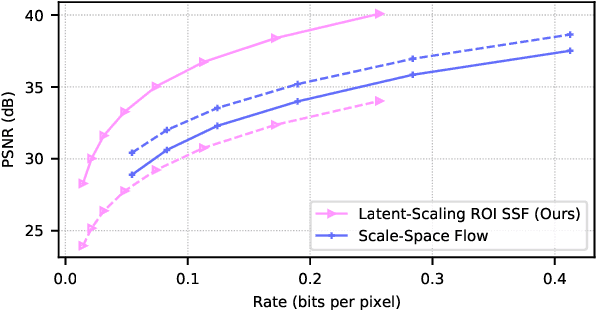

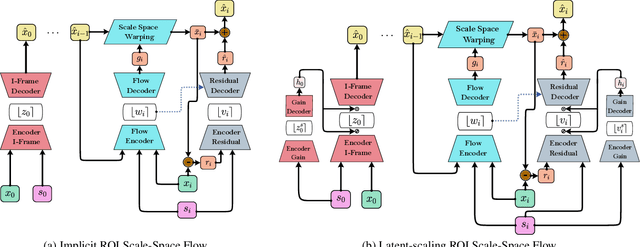
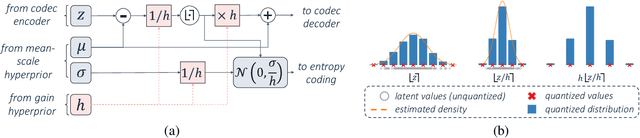
Humans do not perceive all parts of a scene with the same resolution, but rather focus on few regions of interest (ROIs). Traditional Object-Based codecs take advantage of this biological intuition, and are capable of non-uniform allocation of bits in favor of salient regions, at the expense of increased distortion the remaining areas: such a strategy allows a boost in perceptual quality under low rate constraints. Recently, several neural codecs have been introduced for video compression, yet they operate uniformly over all spatial locations, lacking the capability of ROI-based processing. In this paper, we introduce two models for ROI-based neural video coding. First, we propose an implicit model that is fed with a binary ROI mask and it is trained by de-emphasizing the distortion of the background. Secondly, we design an explicit latent scaling method, that allows control over the quantization binwidth for different spatial regions of latent variables, conditioned on the ROI mask. By extensive experiments, we show that our methods outperform all our baselines in terms of Rate-Distortion (R-D) performance in the ROI. Moreover, they can generalize to different datasets and to any arbitrary ROI at inference time. Finally, they do not require expensive pixel-level annotations during training, as synthetic ROI masks can be used with little to no degradation in performance. To the best of our knowledge, our proposals are the first solutions that integrate ROI-based capabilities into neural video compression models.
Skip-Convolutions for Efficient Video Processing
Apr 23, 2021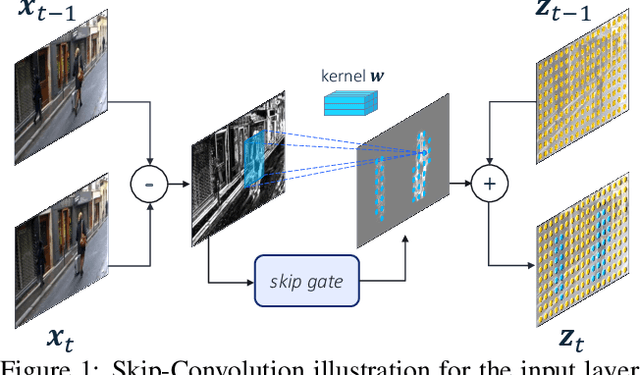
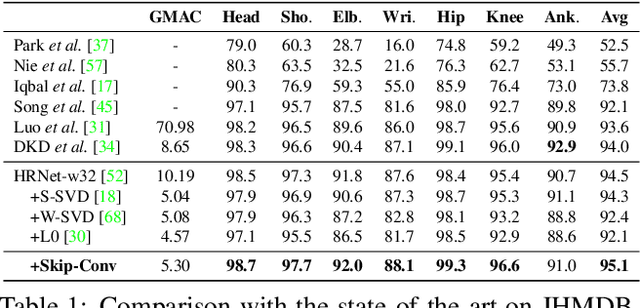
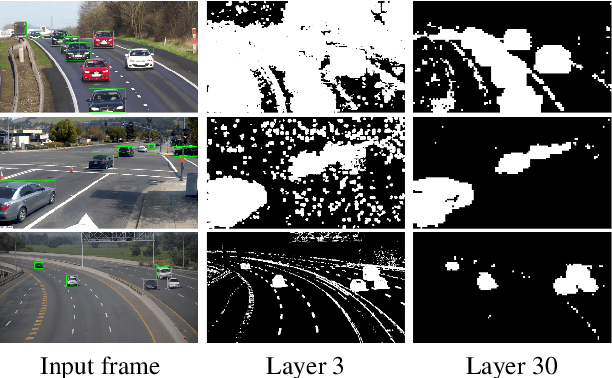
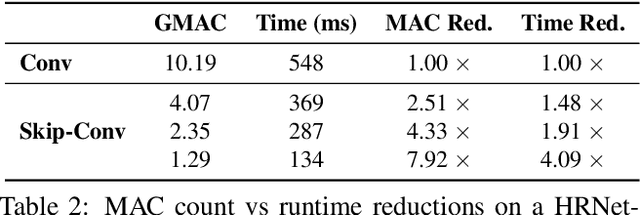
We propose Skip-Convolutions to leverage the large amount of redundancies in video streams and save computations. Each video is represented as a series of changes across frames and network activations, denoted as residuals. We reformulate standard convolution to be efficiently computed on residual frames: each layer is coupled with a binary gate deciding whether a residual is important to the model prediction,~\eg foreground regions, or it can be safely skipped, e.g. background regions. These gates can either be implemented as an efficient network trained jointly with convolution kernels, or can simply skip the residuals based on their magnitude. Gating functions can also incorporate block-wise sparsity structures, as required for efficient implementation on hardware platforms. By replacing all convolutions with Skip-Convolutions in two state-of-the-art architectures, namely EfficientDet and HRNet, we reduce their computational cost consistently by a factor of 3~4x for two different tasks, without any accuracy drop. Extensive comparisons with existing model compression, as well as image and video efficiency methods demonstrate that Skip-Convolutions set a new state-of-the-art by effectively exploiting the temporal redundancies in videos.
Dark Experience for General Continual Learning: a Strong, Simple Baseline
Apr 15, 2020

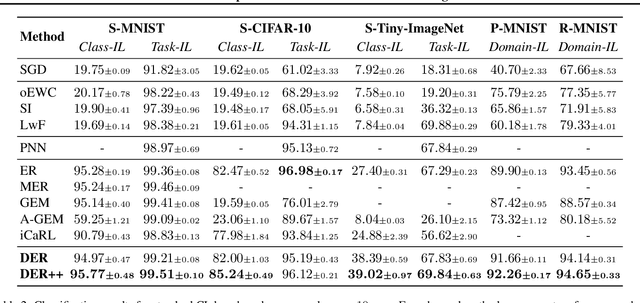

Neural networks struggle to learn continuously, as they forget the old knowledge catastrophically whenever the data distribution changes over time. Recently, Continual Learning has inspired a plethora of approaches and evaluation settings; however, the majority of them overlooks the properties of a practical scenario, where the data stream cannot be shaped as a sequence of tasks and offline training is not viable. We work towards General Continual Learning (GCL), where task boundaries blur and the domain and class distributions shift either gradually or suddenly. We address it through Dark Experience Replay, namely matching the network's logits sampled throughout the optimization trajectory, thus promoting consistency with its past. By conducting an extensive analysis on top of standard benchmarks, we show that such a seemingly simple baseline outperforms consolidated approaches and leverages limited resources. To provide a better understanding, we further introduce MNIST-360, a novel GCL evaluation setting.
Conditional Channel Gated Networks for Task-Aware Continual Learning
Mar 31, 2020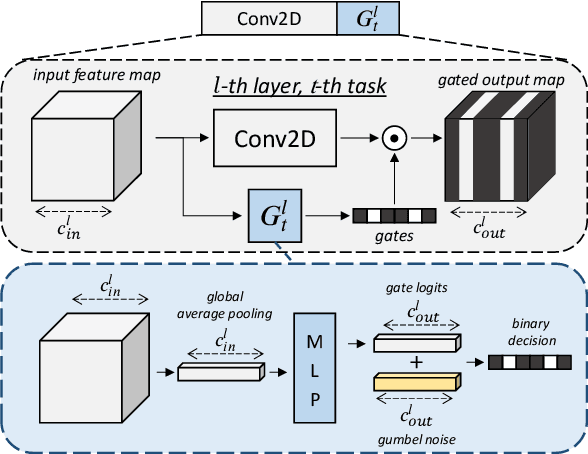

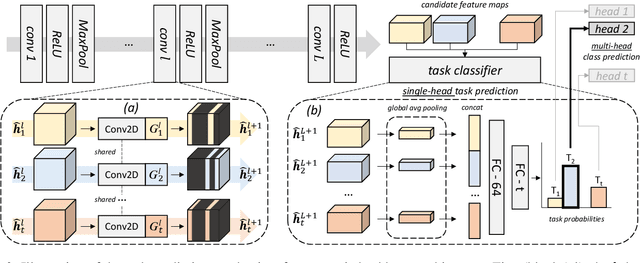
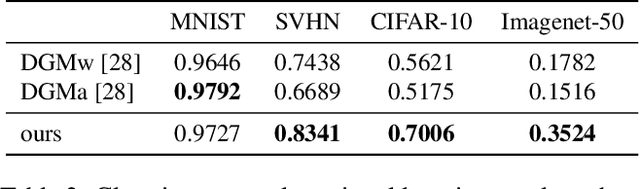
Convolutional Neural Networks experience catastrophic forgetting when optimized on a sequence of learning problems: as they meet the objective of the current training examples, their performance on previous tasks drops drastically. In this work, we introduce a novel framework to tackle this problem with conditional computation. We equip each convolutional layer with task-specific gating modules, selecting which filters to apply on the given input. This way, we achieve two appealing properties. Firstly, the execution patterns of the gates allow to identify and protect important filters, ensuring no loss in the performance of the model for previously learned tasks. Secondly, by using a sparsity objective, we can promote the selection of a limited set of kernels, allowing to retain sufficient model capacity to digest new tasks.Existing solutions require, at test time, awareness of the task to which each example belongs to. This knowledge, however, may not be available in many practical scenarios. Therefore, we additionally introduce a task classifier that predicts the task label of each example, to deal with settings in which a task oracle is not available. We validate our proposal on four continual learning datasets. Results show that our model consistently outperforms existing methods both in the presence and the absence of a task oracle. Notably, on Split SVHN and Imagenet-50 datasets, our model yields up to 23.98% and 17.42% improvement in accuracy w.r.t. competing methods.