 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip-Convolutions for Efficient Video Processing
Paper and Code
Apr 23, 2021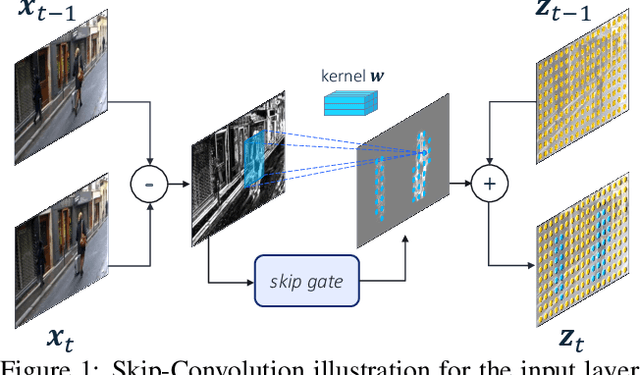
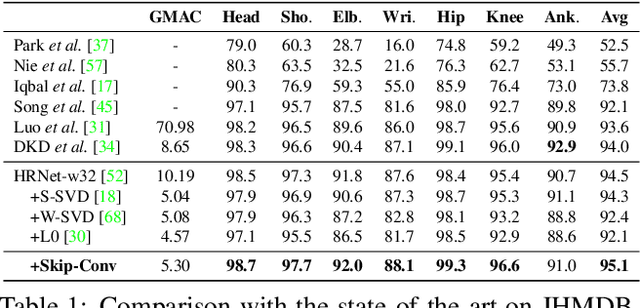
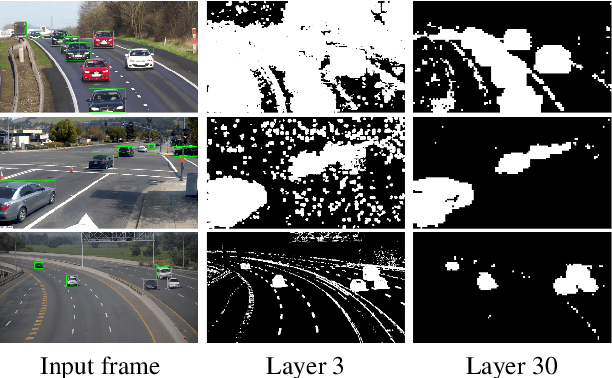
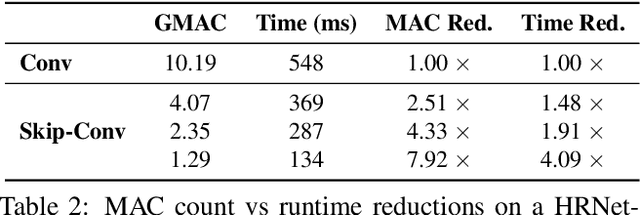
We propose Skip-Convolutions to leverage the large amount of redundancies in video streams and save computations. Each video is represented as a series of changes across frames and network activations, denoted as residuals. We reformulate standard convolution to be efficiently computed on residual frames: each layer is coupled with a binary gate deciding whether a residual is important to the model prediction,~\eg foreground regions, or it can be safely skipped, e.g. background regions. These gates can either be implemented as an efficient network trained jointly with convolution kernels, or can simply skip the residuals based on their magnitude. Gating functions can also incorporate block-wise sparsity structures, as required for efficient implementation on hardware platforms. By replacing all convolutions with Skip-Convolutions in two state-of-the-art architectures, namely EfficientDet and HRNet, we reduce their computational cost consistently by a factor of 3~4x for two different tasks, without any accuracy drop. Extensive comparisons with existing model compression, as well as image and video efficiency methods demonstrate that Skip-Convolutions set a new state-of-the-art by effectively exploiting the temporal redundancies in videos.