 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Adaptive Video Compression: Improving Neural Codecs by Training on the Test Set
Nov 19, 2021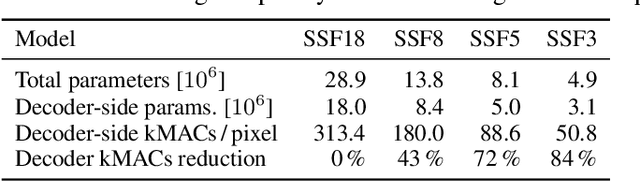
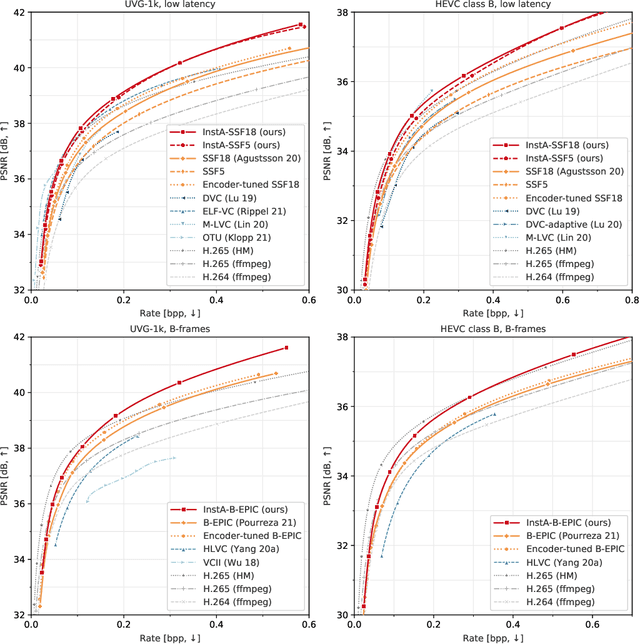
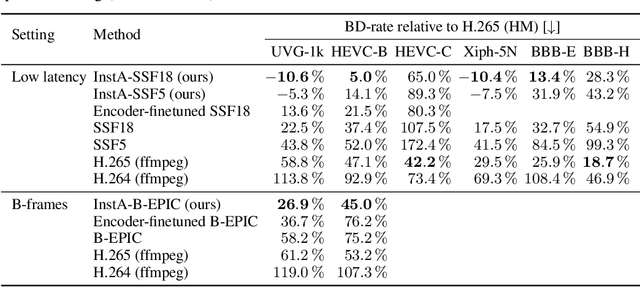
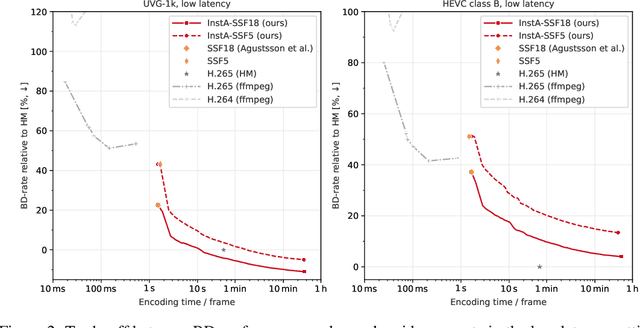
We introduce a video compression algorithm based on instance-adaptive learning. On each video sequence to be transmitted, we finetune a pretrained compression model. The optimal parameters are transmitted to the receiver along with the latent code. By entropy-coding the parameter updates under a suitable mixture model prior, we ensure that the network parameters can be encoded efficiently. This instance-adaptive compression algorithm is agnostic about the choice of base model and has the potential to improve any neural video codec. On UVG, HEVC, and Xiph datasets, our codec improves the performance of a low-latency scale-space flow model by between 21% and 26% BD-rate savings, and that of a state-of-the-art B-frame model by 17 to 20% BD-rate savings. We also demonstrate that instance-adaptive finetuning improves the robustness to domain shift. Finally, our approach reduces the capacity requirements on compression models. We show that it enables a state-of-the-art performance even after reducing the network size by 72%.
Skip-Convolutions for Efficient Video Processing
Apr 23, 2021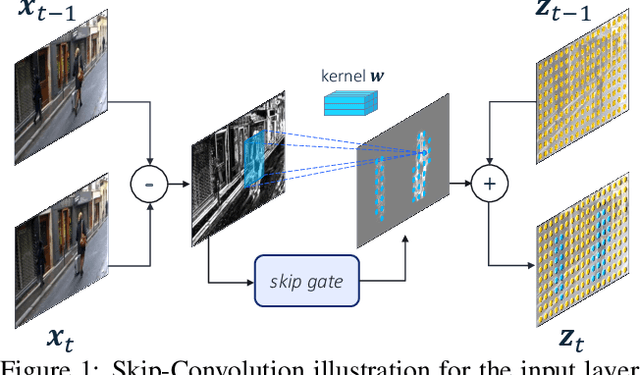
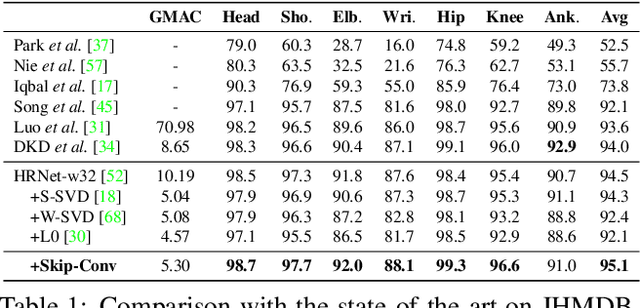
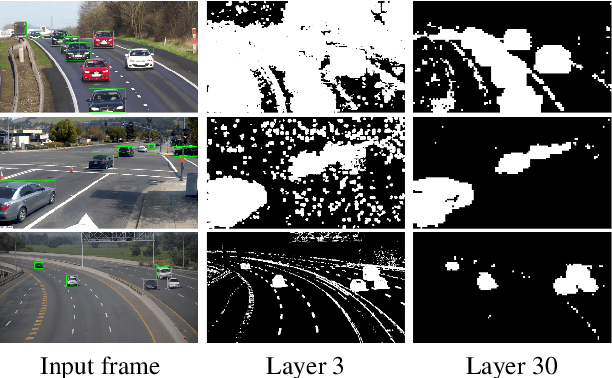
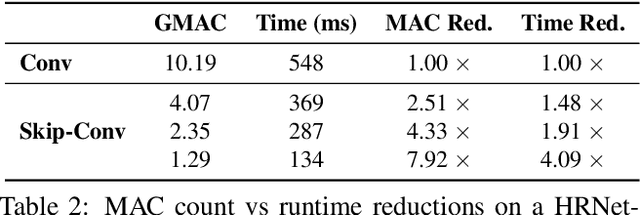
We propose Skip-Convolutions to leverage the large amount of redundancies in video streams and save computations. Each video is represented as a series of changes across frames and network activations, denoted as residuals. We reformulate standard convolution to be efficiently computed on residual frames: each layer is coupled with a binary gate deciding whether a residual is important to the model prediction,~\eg foreground regions, or it can be safely skipped, e.g. background regions. These gates can either be implemented as an efficient network trained jointly with convolution kernels, or can simply skip the residuals based on their magnitude. Gating functions can also incorporate block-wise sparsity structures, as required for efficient implementation on hardware platforms. By replacing all convolutions with Skip-Convolutions in two state-of-the-art architectures, namely EfficientDet and HRNet, we reduce their computational cost consistently by a factor of 3~4x for two different tasks, without any accuracy drop. Extensive comparisons with existing model compression, as well as image and video efficiency methods demonstrate that Skip-Convolutions set a new state-of-the-art by effectively exploiting the temporal redundancies in videos.
A Combined Deep Learning based End-to-End Video Coding Architecture for YUV Color Space
Apr 01, 2021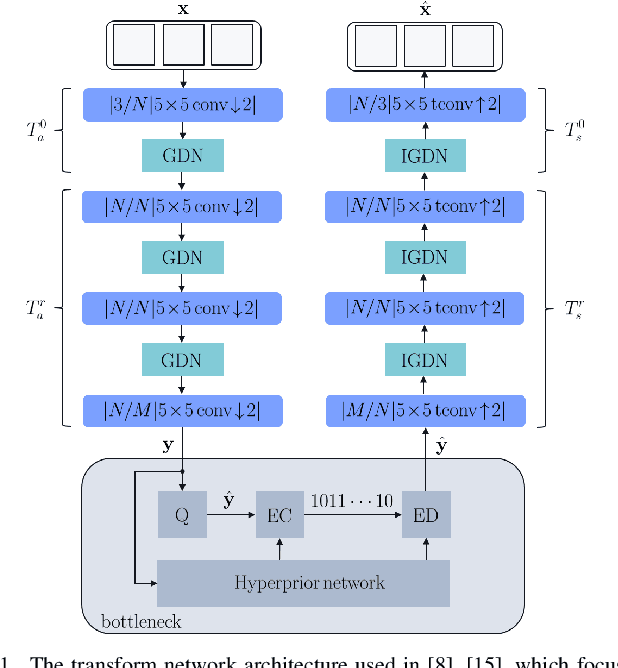
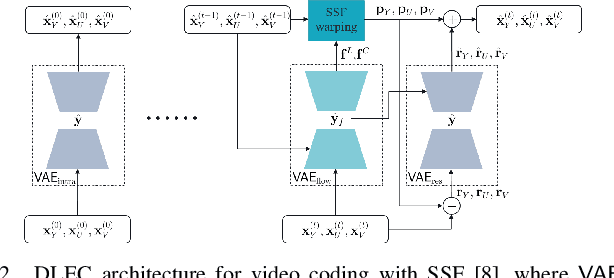
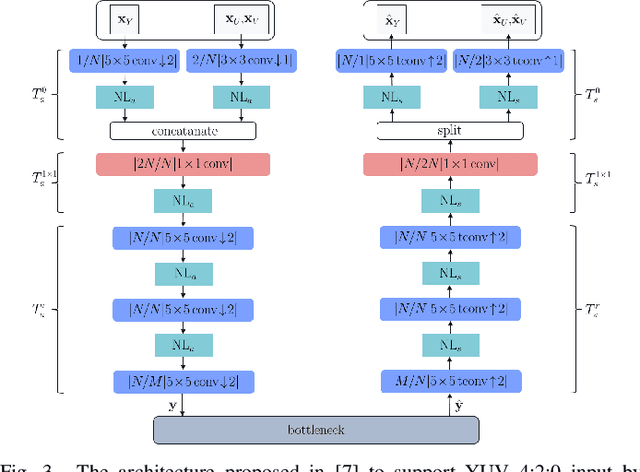

Most of the existing deep learning based end-to-end video coding (DLEC) architectures are designed specifically for RGB color format, yet the video coding standards, including H.264/AVC, H.265/HEVC and H.266/VVC developed over past few decades, have been designed primarily for YUV 4:2:0 format, where the chrominance (U and V) components are subsampled to achieve superior compression performances considering the human visual system. While a broad number of papers on DLEC compare these two distinct coding schemes in RGB domain, it is ideal to have a common evaluation framework in YUV 4:2:0 domain for a more fair comparison. This paper introduces a new DLEC architecture for video coding to effectively support YUV 4:2:0 and compares its performance against the HEVC standard under a common evaluation framework. The experimental results on YUV 4:2:0 video sequences show that the proposed architecture can outperform HEVC in intra-frame coding, however inter-frame coding is not as efficient on contrary to the RGB coding results reported in recent papers.
Transform Network Architectures for Deep Learning based End-to-End Image/Video Coding in Subsampled Color Spaces
Feb 27, 2021



Most of the existing deep learning based end-to-end image/video coding (DLEC) architectures are designed for non-subsampled RGB color format. However, in order to achieve a superior coding performance, many state-of-the-art block-based compression standards such as High Efficiency Video Coding (HEVC/H.265) and Versatile Video Coding (VVC/H.266) are designed primarily for YUV 4:2:0 format, where U and V components are subsampled by considering the human visual system. This paper investigates various DLEC designs to support YUV 4:2:0 format by comparing their performance against the main profiles of HEVC and VVC standards under a common evaluation framework. Moreover, a new transform network architecture is proposed to improve the efficiency of coding YUV 4:2:0 data. The experimental results on YUV 4:2:0 datasets show that the proposed architecture significantly outperforms naive extensions of existing architectures designed for RGB format and achieves about 10% average BD-rate improvement over the intra-frame coding in HEVC.
Overfitting for Fun and Profit: Instance-Adaptive Data Compression
Jan 21, 2021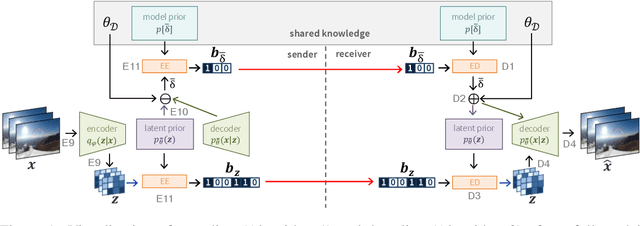


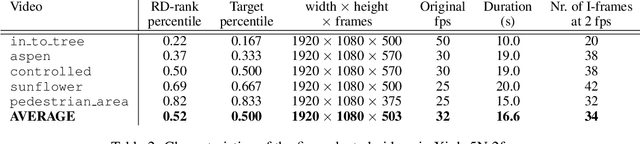
Neural data compression has been shown to outperform classical methods in terms of $RD$ performance, with results still improving rapidly. At a high level, neural compression is based on an autoencoder that tries to reconstruct the input instance from a (quantized) latent representation, coupled with a prior that is used to losslessly compress these latents. Due to limitations on model capacity and imperfect optimization and generalization, such models will suboptimally compress test data in general. However, one of the great strengths of learned compression is that if the test-time data distribution is known and relatively low-entropy (e.g. a camera watching a static scene, a dash cam in an autonomous car, etc.), the model can easily be finetuned or adapted to this distribution, leading to improved $RD$ performance. In this paper we take this concept to the extreme, adapting the full model to a single video, and sending model updates (quantized and compressed using a parameter-space prior) along with the latent representation. Unlike previous work, we finetune not only the encoder/latents but the entire model, and - during finetuning - take into account both the effect of model quantization and the additional costs incurred by sending the model updates. We evaluate an image compression model on I-frames (sampled at 2 fps) from videos of the Xiph dataset, and demonstrate that full-model adaptation improves $RD$ performance by ~1 dB, with respect to encoder-only finetuning.
Lossy Compression with Distortion Constrained Optimization
May 08, 2020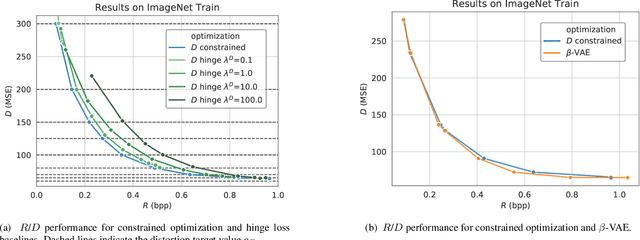
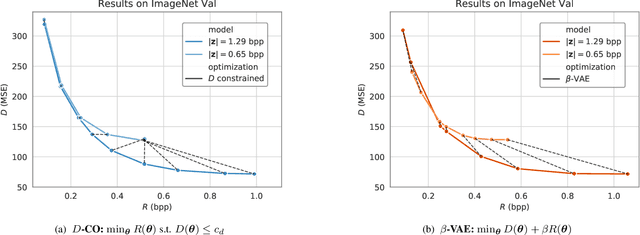
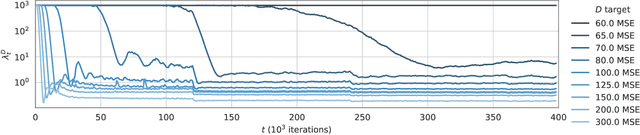
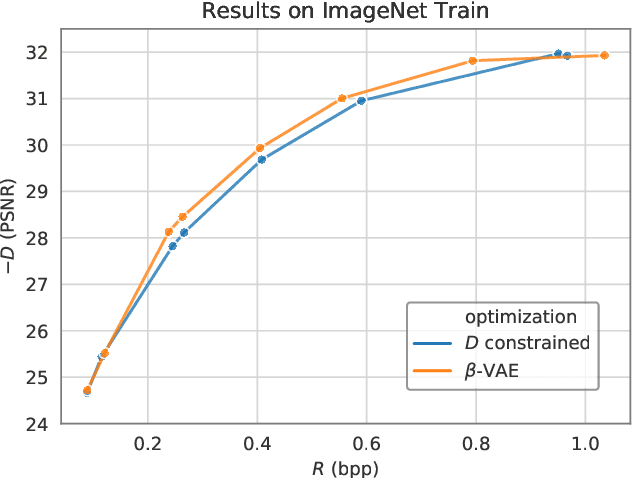
When training end-to-end learned models for lossy compression, one has to balance the rate and distortion losses. This is typically done by manually setting a tradeoff parameter $\beta$, an approach called $\beta$-VAE. Using this approach it is difficult to target a specific rate or distortion value, because the result can be very sensitive to $\beta$, and the appropriate value for $\beta$ depends on the model and problem setup. As a result, model comparison requires extensive per-model $\beta$-tuning, and producing a whole rate-distortion curve (by varying $\beta$) for each model to be compared. We argue that the constrained optimization method of Rezende and Viola, 2018 is a lot more appropriate for training lossy compression models because it allows us to obtain the best possible rate subject to a distortion constraint. This enables pointwise model comparisons, by training two models with the same distortion target and comparing their rate. We show that the method does manage to satisfy the constraint on a realistic image compression task, outperforms a constrained optimization method based on a hinge-loss, and is more practical to use for model selection than a $\beta$-VAE.
A Data and Compute Efficient Design for Limited-Resources Deep Learning
Apr 21, 2020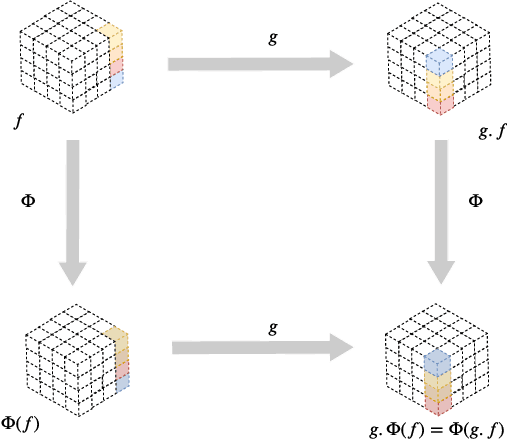

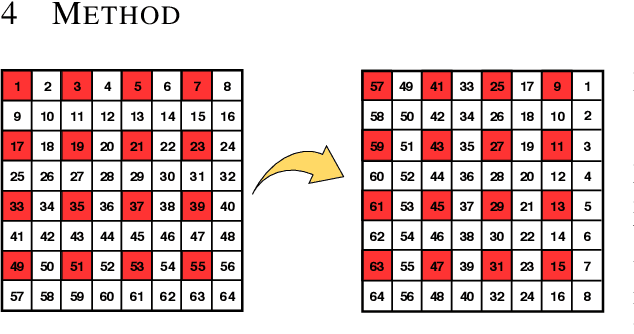
Thanks to their improved data efficiency, equivariant neural networks have gained increased interest in the deep learning community. They have been successfully applied in the medical domain where symmetries in the data can be effectively exploited to build more accurate and robust models. To be able to reach a much larger body of patients, mobile, on-device implementations of deep learning solutions have been developed for medical applications. However, equivariant models are commonly implemented using large and computationally expensive architectures, not suitable to run on mobile devices. In this work, we design and test an equivariant version of MobileNetV2 and further optimize it with model quantization to enable more efficient inference. We achieve close-to state of the art performance on the Patch Camelyon (PCam) medical dataset while being more computationally efficient.
Learning Discrete Distributions by Dequantization
Jan 30, 2020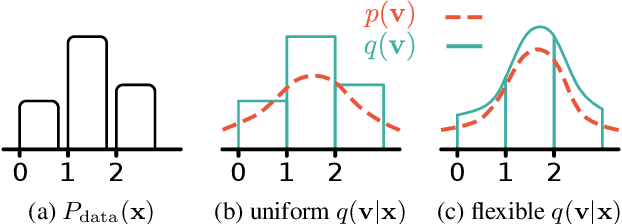
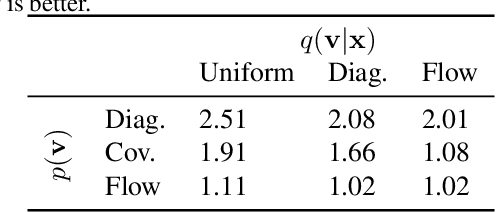


Media is generally stored digitally and is therefore discrete. Many successful deep distribution models in deep learning learn a density, i.e., the distribution of a continuous random variable. Na\"ive optimization on discrete data leads to arbitrarily high likelihoods, and instead, it has become standard practice to add noise to datapoints. In this paper, we present a general framework for dequantization that captures existing methods as a special case. We derive two new dequantization objectives: importance-weighted (iw) dequantization and R\'enyi dequantization. In addition, we introduce autoregressive dequantization (ARD) for more flexible dequantization distributions. Empirically we find that iw and R\'enyi dequantization considerably improve performance for uniform dequantization distributions. ARD achieves a negative log-likelihood of 3.06 bits per dimension on CIFAR10, which to the best of our knowledge is state-of-the-art among distribution models that do not require autoregressive inverses for sampling.
Video Compression With Rate-Distortion Autoencoders
Aug 14, 2019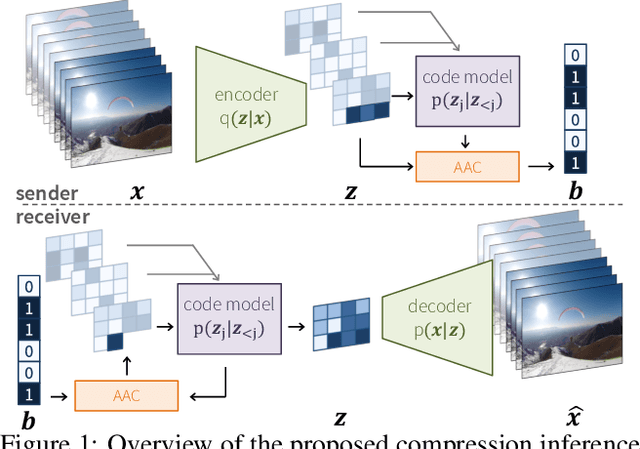
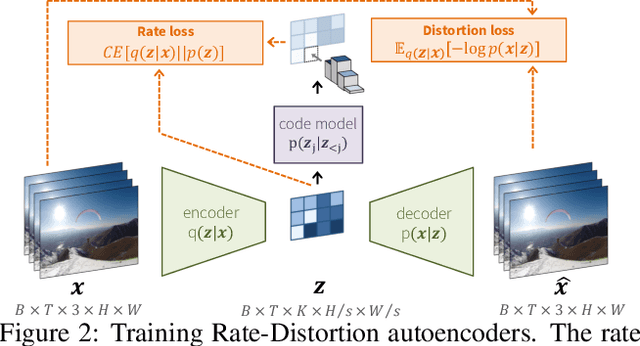
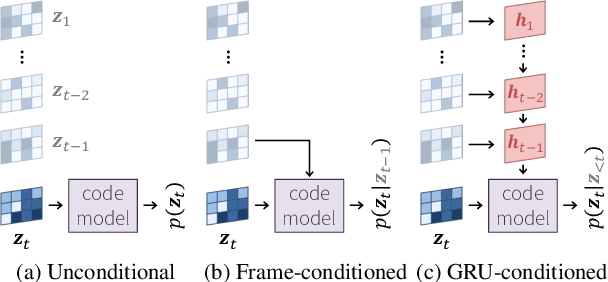

In this paper we present a a deep generative model for lossy video compression. We employ a model that consists of a 3D autoencoder with a discrete latent space and an autoregressive prior used for entropy coding. Both autoencoder and prior are trained jointly to minimize a rate-distortion loss, which is closely related to the ELBO used in variational autoencoders. Despite its simplicity, we find that our method outperforms the state-of-the-art learned video compression networks based on motion compensation or interpolation. We systematically evaluate various design choices, such as the use of frame-based or spatio-temporal autoencoders, and the type of autoregressive prior. In addition, we present three extensions of the basic method that demonstrate the benefits over classical approaches to compression. First, we introduce semantic compression, where the model is trained to allocate more bits to objects of interest. Second, we study adaptive compression, where the model is adapted to a domain with limited variability, e.g., videos taken from an autonomous car, to achieve superior compression on that domain. Finally, we introduce multimodal compression, where we demonstrate the effectiveness of our model in joint compression of multiple modalities captured by non-standard imaging sensors, such as quad cameras. We believe that this opens up novel video compression applications, which have not been feasible with classical codecs.
Covariance in Physics and Convolutional Neural Networks
Jun 06, 2019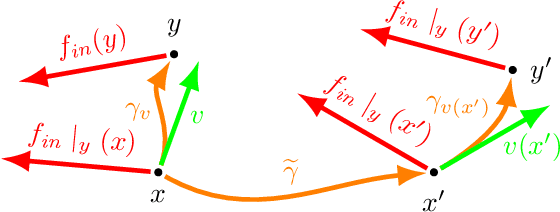
In this proceeding we give an overview of the idea of covariance (or equivariance) featured in the recent development of convolutional neural networks (CNNs). We study the similarities and differences between the use of covariance in theoretical physics and in the CNN context. Additionally, we demonstrate that the simple assumption of covariance, together with the required properties of locality, linearity and weight sharing, is sufficient to uniquely determine the form of the convolution.