 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Bijections for Smooth and Interpretable Normalizing Flows
Jan 15, 2026A key challenge in designing normalizing flows is finding expressive scalar bijections that remain invertible with tractable Jacobians. Existing approaches face trade-offs: affine transformations are smooth and analytically invertible but lack expressivity; monotonic splines offer local control but are only piecewise smooth and act on bounded domains; residual flows achieve smoothness but need numerical inversion. We introduce three families of analytic bijections -- cubic rational, sinh, and cubic polynomial -- that are globally smooth ($C^\infty$), defined on all of $\mathbb{R}$, and analytically invertible in closed form, combining the favorable properties of all prior approaches. These bijections serve as drop-in replacements in coupling flows, matching or exceeding spline performance. Beyond coupling layers, we develop radial flows: a novel architecture using direct parametrization that transforms the radial coordinate while preserving angular direction. Radial flows exhibit exceptional training stability, produce geometrically interpretable transformations, and on targets with radial structure can achieve comparable quality to coupling flows with $1000\times$ fewer parameters. We provide comprehensive evaluation on 1D and 2D benchmarks, and demonstrate applicability to higher-dimensional physics problems through experiments on $φ^4$ lattice field theory, where our bijections outperform affine baselines and enable problem-specific designs that address mode collapse.
Lecture Notes on Normalizing Flows for Lattice Quantum Field Theories
Apr 25, 2025



Numerical simulations of quantum field theories on lattices serve as a fundamental tool for studying the non-perturbative regime of the theories, where analytic tools often fall short. Challenges arise when one takes the continuum limit or as the system approaches a critical point, especially in the presence of non-trivial topological structures in the theory. Rapid recent advances in machine learning provide a promising avenue for progress in this area. These lecture notes aim to give a brief account of lattice field theories, normalizing flows, and how the latter can be applied to study the former. The notes are based on the lectures given by the first author in various recent research schools.
Continuous normalizing flows for lattice gauge theories
Oct 17, 2024Continuous normalizing flows are known to be highly expressive and flexible, which allows for easier incorporation of large symmetries and makes them a powerful tool for sampling in lattice field theories. Building on previous work, we present a general continuous normalizing flow architecture for matrix Lie groups that is equivariant under group transformations. We apply this to lattice gauge theories in two dimensions as a proof-of-principle and demonstrate competitive performance, showing its potential as a tool for future lattice sampling tasks.
GUD: Generation with Unified Diffusion
Oct 03, 2024Diffusion generative models transform noise into data by inverting a process that progressively adds noise to data samples. Inspired by concepts from the renormalization group in physics, which analyzes systems across different scales, we revisit diffusion models by exploring three key design aspects: 1) the choice of representation in which the diffusion process operates (e.g. pixel-, PCA-, Fourier-, or wavelet-basis), 2) the prior distribution that data is transformed into during diffusion (e.g. Gaussian with covariance $\Sigma$), and 3) the scheduling of noise levels applied separately to different parts of the data, captured by a component-wise noise schedule. Incorporating the flexibility in these choices, we develop a unified framework for diffusion generative models with greatly enhanced design freedom. In particular, we introduce soft-conditioning models that smoothly interpolate between standard diffusion models and autoregressive models (in any basis), conceptually bridging these two approaches. Our framework opens up a wide design space which may lead to more efficient training and data generation, and paves the way to novel architectures integrating different generative approaches and generation tasks.
Learning Lattice Quantum Field Theories with Equivariant Continuous Flows
Jul 01, 2022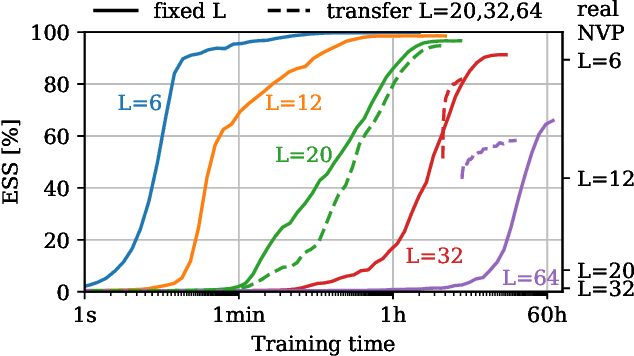

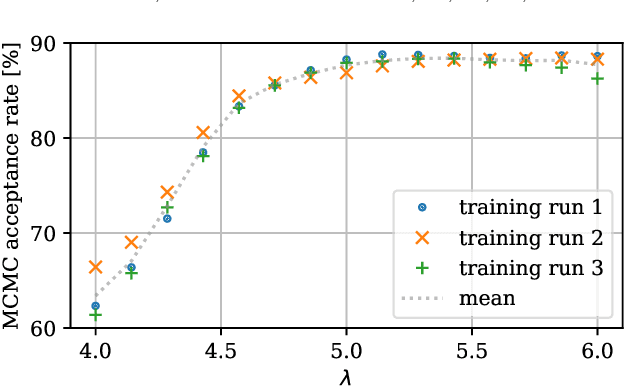
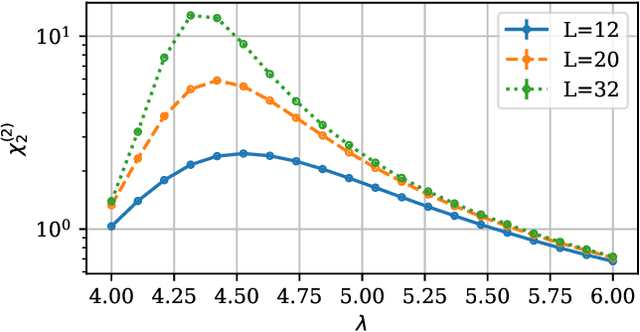
We propose a novel machine learning method for sampling from the high-dimensional probability distributions of Lattice Quantum Field Theories. Instead of the deep architectures used so far for this task, our proposal is based on a single neural ODE layer and incorporates the full symmetries of the problem. We test our model on the $\phi^4$ theory, showing that it systematically outperforms previously proposed flow-based methods in sampling efficiency, and the improvement is especially pronounced for larger lattices. Compared to the previous baseline model, we improve a key metric, the effective sample size, from 1% to 91% on a lattice of size $32\times 32$. We also demonstrate that our model can successfully learn a continuous family of theories at once, and the results of learning can be transferred to larger lattices. Such generalization capacities further accentuate the potential advantages of machine learning methods compared to traditional MCMC-based methods.
Entangled q-Convolutional Neural Nets
Mar 06, 2021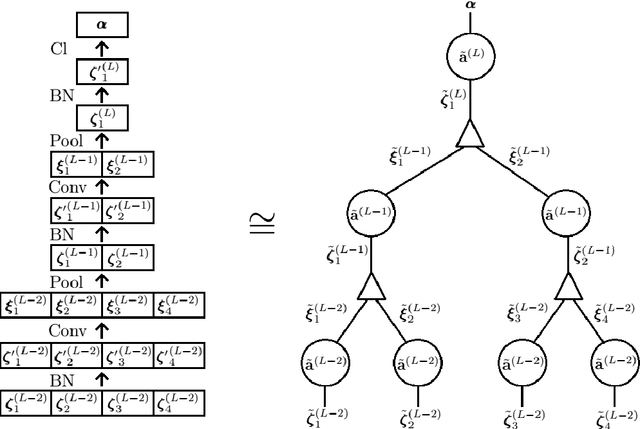
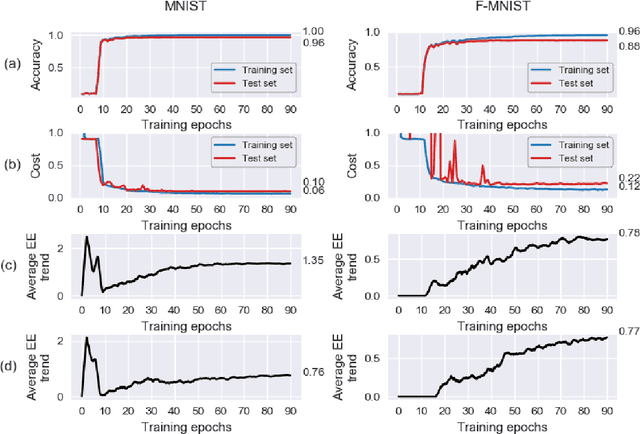
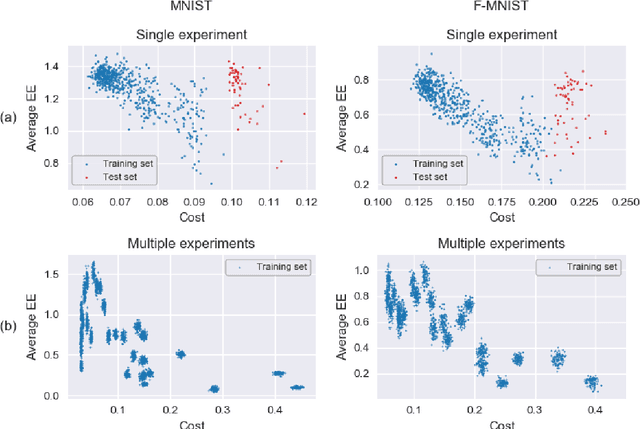
We introduce a machine learning model, the q-CNN model, sharing key features with convolutional neural networks and admitting a tensor network description. As examples, we apply q-CNN to the MNIST and Fashion MNIST classification tasks. We explain how the network associates a quantum state to each classification label, and study the entanglement structure of these network states. In both our experiments on the MNIST and Fashion-MNIST datasets, we observe a distinct increase in both the left/right as well as the up/down bipartition entanglement entropy during training as the network learns the fine features of the data. More generally, we observe a universal negative correlation between the value of the entanglement entropy and the value of the cost function, suggesting that the network needs to learn the entanglement structure in order the perform the task accurately. This supports the possibility of exploiting the entanglement structure as a guide to design the machine learning algorithm suitable for given tasks.
Covariance in Physics and Convolutional Neural Networks
Jun 06, 2019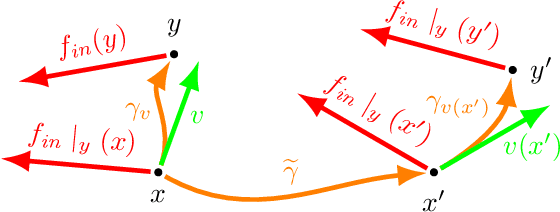
In this proceeding we give an overview of the idea of covariance (or equivariance) featured in the recent development of convolutional neural networks (CNNs). We study the similarities and differences between the use of covariance in theoretical physics and in the CNN context. Additionally, we demonstrate that the simple assumption of covariance, together with the required properties of locality, linearity and weight sharing, is sufficient to uniquely determine the form of the convolution.