 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Local Speculative Decoding for Image Generation
Jan 08, 2026Autoregressive (AR) models have achieved remarkable success in image synthesis, yet their sequential nature imposes significant latency constraints. Speculative Decoding offers a promising avenue for acceleration, but existing approaches are limited by token-level ambiguity and lack of spatial awareness. In this work, we introduce Multi-Scale Local Speculative Decoding (MuLo-SD), a novel framework that combines multi-resolution drafting with spatially informed verification to accelerate AR image generation. Our method leverages a low-resolution drafter paired with learned up-samplers to propose candidate image tokens, which are then verified in parallel by a high-resolution target model. Crucially, we incorporate a local rejection and resampling mechanism, enabling efficient correction of draft errors by focusing on spatial neighborhoods rather than raster-scan resampling after the first rejection. We demonstrate that MuLo-SD achieves substantial speedups - up to $\mathbf{1.7\times}$ - outperforming strong speculative decoding baselines such as EAGLE-2 and LANTERN in terms of acceleration, while maintaining comparable semantic alignment and perceptual quality. These results are validated using GenEval, DPG-Bench, and FID/HPSv2 on the MS-COCO 5k validation split. Extensive ablations highlight the impact of up-sampling design, probability pooling, and local rejection and resampling with neighborhood expansion. Our approach sets a new state-of-the-art in speculative decoding for image synthesis, bridging the gap between efficiency and fidelity.
Neural Image Compression with a Diffusion-Based Decoder
Jan 23, 2023



Diffusion probabilistic models have recently achieved remarkable success in generating high quality image and video data. In this work, we build on this class of generative models and introduce a method for lossy compression of high resolution images. The resulting codec, which we call DIffuson-based Residual Augmentation Codec (DIRAC),is the first neural codec to allow smooth traversal of the rate-distortion-perception tradeoff at test time, while obtaining competitive performance with GAN-based methods in perceptual quality. Furthermore, while sampling from diffusion probabilistic models is notoriously expensive, we show that in the compression setting the number of steps can be drastically reduced.
Region-of-Interest Based Neural Video Compression
Mar 03, 2022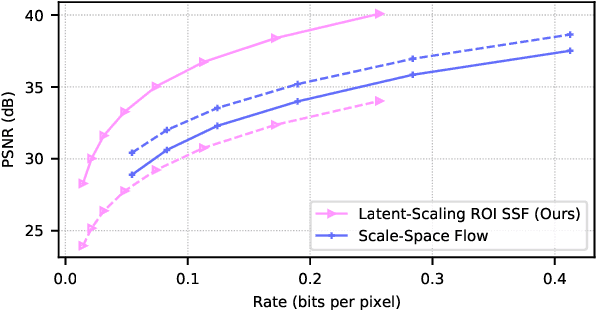

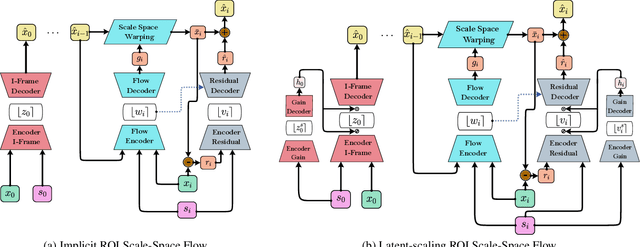
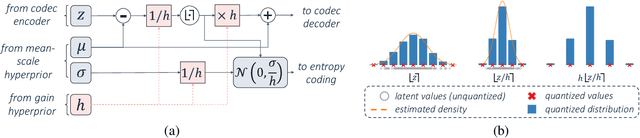
Humans do not perceive all parts of a scene with the same resolution, but rather focus on few regions of interest (ROIs). Traditional Object-Based codecs take advantage of this biological intuition, and are capable of non-uniform allocation of bits in favor of salient regions, at the expense of increased distortion the remaining areas: such a strategy allows a boost in perceptual quality under low rate constraints. Recently, several neural codecs have been introduced for video compression, yet they operate uniformly over all spatial locations, lacking the capability of ROI-based processing. In this paper, we introduce two models for ROI-based neural video coding. First, we propose an implicit model that is fed with a binary ROI mask and it is trained by de-emphasizing the distortion of the background. Secondly, we design an explicit latent scaling method, that allows control over the quantization binwidth for different spatial regions of latent variables, conditioned on the ROI mask. By extensive experiments, we show that our methods outperform all our baselines in terms of Rate-Distortion (R-D) performance in the ROI. Moreover, they can generalize to different datasets and to any arbitrary ROI at inference time. Finally, they do not require expensive pixel-level annotations during training, as synthetic ROI masks can be used with little to no degradation in performance. To the best of our knowledge, our proposals are the first solutions that integrate ROI-based capabilities into neural video compression models.
Lossy Compression with Distortion Constrained Optimization
May 08, 2020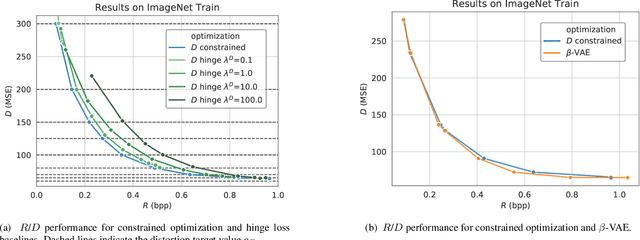
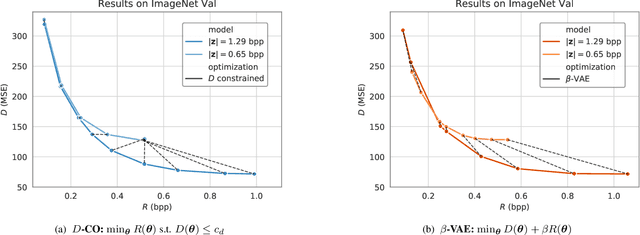
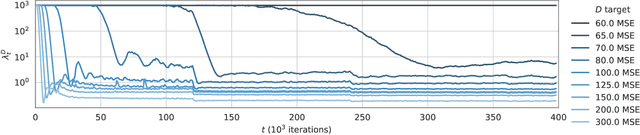
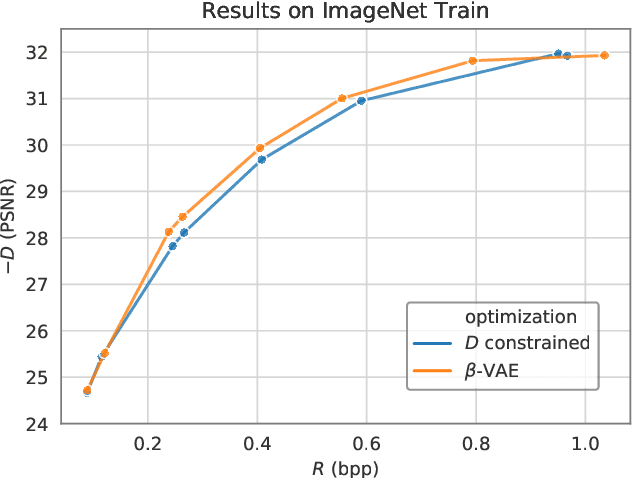
When training end-to-end learned models for lossy compression, one has to balance the rate and distortion losses. This is typically done by manually setting a tradeoff parameter $\beta$, an approach called $\beta$-VAE. Using this approach it is difficult to target a specific rate or distortion value, because the result can be very sensitive to $\beta$, and the appropriate value for $\beta$ depends on the model and problem setup. As a result, model comparison requires extensive per-model $\beta$-tuning, and producing a whole rate-distortion curve (by varying $\beta$) for each model to be compared. We argue that the constrained optimization method of Rezende and Viola, 2018 is a lot more appropriate for training lossy compression models because it allows us to obtain the best possible rate subject to a distortion constraint. This enables pointwise model comparisons, by training two models with the same distortion target and comparing their rate. We show that the method does manage to satisfy the constraint on a realistic image compression task, outperforms a constrained optimization method based on a hinge-loss, and is more practical to use for model selection than a $\beta$-VAE.
Feedback Recurrent AutoEncoder
Nov 11, 2019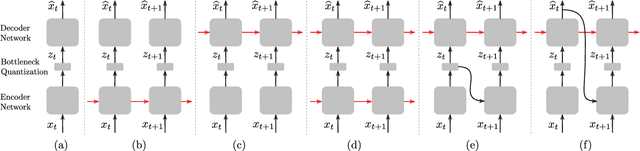
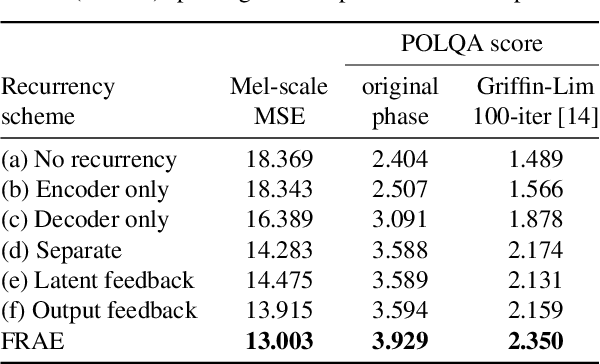
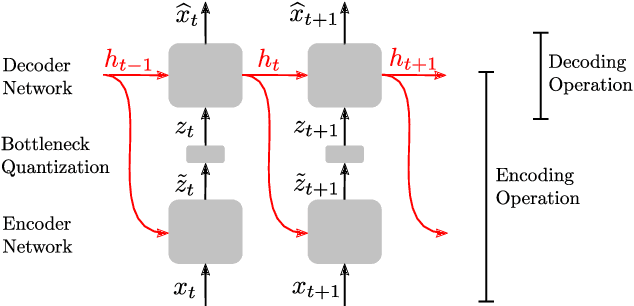
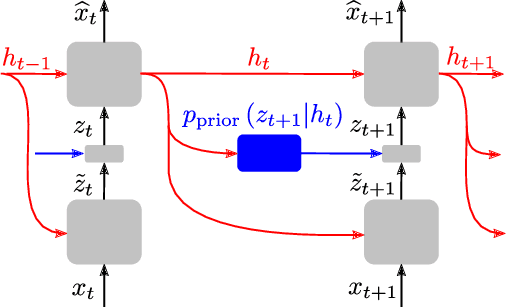
In this work, we propose a new recurrent autoencoder architecture, termed Feedback Recurrent AutoEncoder (FRAE), for online compression of sequential data with temporal dependency. The recurrent structure of FRAE is designed to efficiently extract the redundancy along the time dimension and allows a compact discrete representation of the data to be learned. We demonstrate its effectiveness in speech spectrogram compression. Specifically, we show that the FRAE, paired with a powerful neural vocoder, can produce high-quality speech waveforms at a low, fixed bitrate. We further show that by adding a learned prior for the latent space and using an entropy coder, we can achieve an even lower variable bitrate.