 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-of-Interest Based Neural Video Compression
Paper and Code
Mar 03, 2022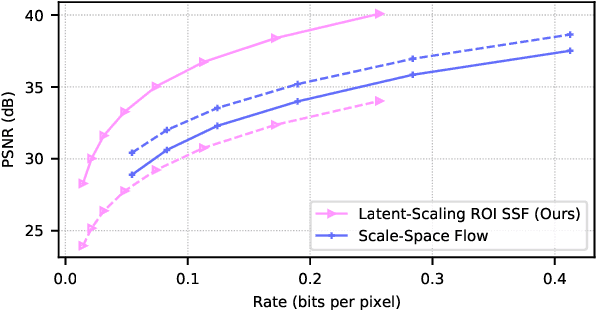

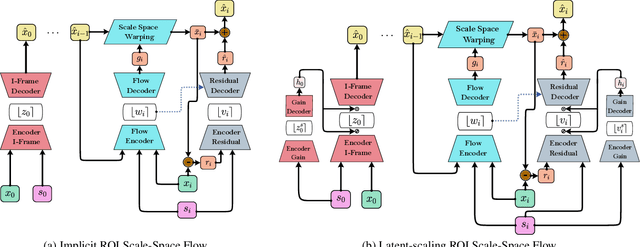
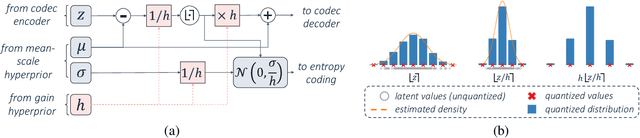
Humans do not perceive all parts of a scene with the same resolution, but rather focus on few regions of interest (ROIs). Traditional Object-Based codecs take advantage of this biological intuition, and are capable of non-uniform allocation of bits in favor of salient regions, at the expense of increased distortion the remaining areas: such a strategy allows a boost in perceptual quality under low rate constraints. Recently, several neural codecs have been introduced for video compression, yet they operate uniformly over all spatial locations, lacking the capability of ROI-based processing. In this paper, we introduce two models for ROI-based neural video coding. First, we propose an implicit model that is fed with a binary ROI mask and it is trained by de-emphasizing the distortion of the background. Secondly, we design an explicit latent scaling method, that allows control over the quantization binwidth for different spatial regions of latent variables, conditioned on the ROI mask. By extensive experiments, we show that our methods outperform all our baselines in terms of Rate-Distortion (R-D) performance in the ROI. Moreover, they can generalize to different datasets and to any arbitrary ROI at inference time. Finally, they do not require expensive pixel-level annotations during training, as synthetic ROI masks can be used with little to no degradation in performance. To the best of our knowledge, our proposals are the first solutions that integrate ROI-based capabilities into neural video compression models.