 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustly overfitting latents for flexible neural image compression
Jan 31, 2024Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models. We extend this idea by introducing SGA+, which contains three different methods that build upon SGA. Further, we give a detailed analysis of our proposed methods, show how they improve performance, and show that they are less sensitive to hyperparameter choices. Besides, we show how each method can be extended to three- instead of two-class rounding. Finally, we show how refinement of the latents with our best-performing method improves the compression performance on the Tecnick dataset and how it can be deployed to partly move along the rate-distortion curve.
Region-of-Interest Based Neural Video Compression
Mar 03, 2022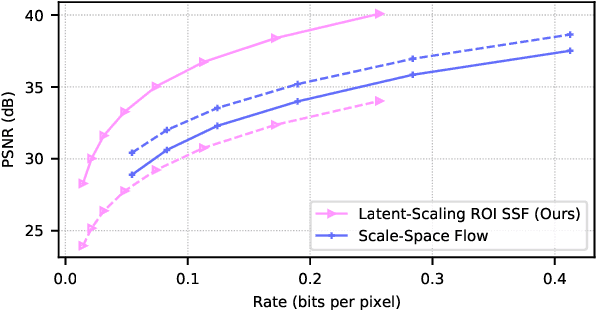

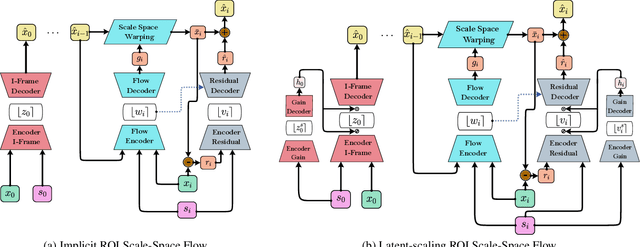
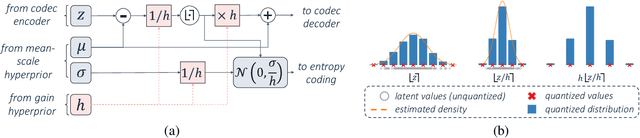
Humans do not perceive all parts of a scene with the same resolution, but rather focus on few regions of interest (ROIs). Traditional Object-Based codecs take advantage of this biological intuition, and are capable of non-uniform allocation of bits in favor of salient regions, at the expense of increased distortion the remaining areas: such a strategy allows a boost in perceptual quality under low rate constraints. Recently, several neural codecs have been introduced for video compression, yet they operate uniformly over all spatial locations, lacking the capability of ROI-based processing. In this paper, we introduce two models for ROI-based neural video coding. First, we propose an implicit model that is fed with a binary ROI mask and it is trained by de-emphasizing the distortion of the background. Secondly, we design an explicit latent scaling method, that allows control over the quantization binwidth for different spatial regions of latent variables, conditioned on the ROI mask. By extensive experiments, we show that our methods outperform all our baselines in terms of Rate-Distortion (R-D) performance in the ROI. Moreover, they can generalize to different datasets and to any arbitrary ROI at inference time. Finally, they do not require expensive pixel-level annotations during training, as synthetic ROI masks can be used with little to no degradation in performance. To the best of our knowledge, our proposals are the first solutions that integrate ROI-based capabilities into neural video compression models.
Invertible DenseNets with Concatenated LipSwish
Feb 04, 2021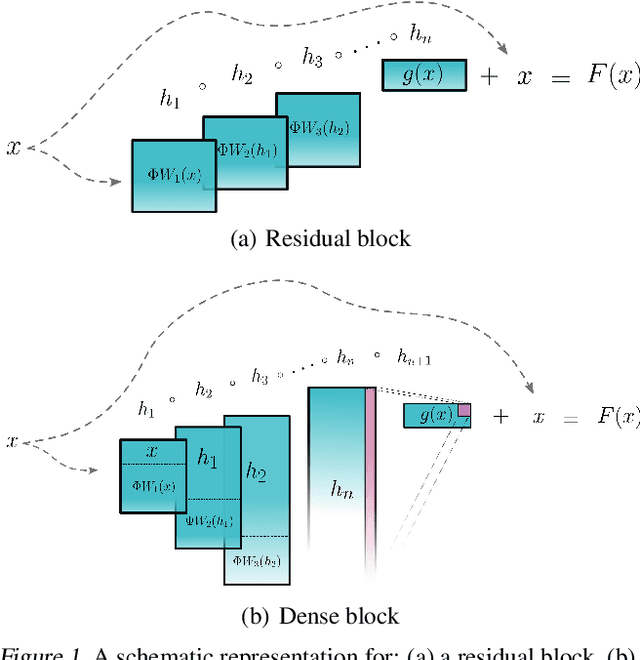


We introduce Invertible Dense Networks (i-DenseNets), a more parameter efficient alternative to Residual Flows. The method relies on an analysis of the Lipschitz continuity of the concatenation in DenseNets, where we enforce invertibility of the network by satisfying the Lipschitz constant. We extend this method by proposing a learnable concatenation, which not only improves the model performance but also indicates the importance of the concatenated representation. Additionally, we introduce the Concatenated LipSwish as activation function, for which we show how to enforce the Lipschitz condition and which boosts performance. The new architecture, i-DenseNet, out-performs Residual Flow and other flow-based models on density estimation evaluated in bits per dimension, where we utilize an equal parameter budget. Moreover, we show that the proposed model out-performs Residual Flows when trained as a hybrid model where the model is both a generative and a discriminative model.
i-DenseNets
Oct 23, 2020



We introduce Invertible Dense Networks (i-DenseNets), a more parameter efficient alternative to Residual Flows. The method relies on an analysis of the Lipschitz continuity of the concatenation in DenseNets, where we enforce the invertibility of the network by satisfying the Lipschitz constraint. Additionally, we extend this method by proposing a learnable concatenation, which not only improves the model performance but also indicates the importance of the concatenated representation. We demonstrate the performance of i-DenseNets and Residual Flows on toy, MNIST, and CIFAR10 data. Both i-DenseNets outperform Residual Flows evaluated in negative log-likelihood, on all considered datasets under an equal parameter budget.