 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Computation of Generalized Embeddings for Underwater Acoustic Target Recognition using Contrastive Learning
May 19, 2025



The increasing level of sound pollution in marine environments poses an increased threat to ocean health, making it crucial to monitor underwater noise. By monitoring this noise, the sources responsible for this pollution can be mapped. Monitoring is performed by passively listening to these sounds. This generates a large amount of data records, capturing a mix of sound sources such as ship activities and marine mammal vocalizations. Although machine learning offers a promising solution for automatic sound classification, current state-of-the-art methods implement supervised learning. This requires a large amount of high-quality labeled data that is not publicly available. In contrast, a massive amount of lower-quality unlabeled data is publicly available, offering the opportunity to explore unsupervised learning techniques. This research explores this possibility by implementing an unsupervised Contrastive Learning approach. Here, a Conformer-based encoder is optimized by the so-called Variance-Invariance-Covariance Regularization loss function on these lower-quality unlabeled data and the translation to the labeled data is made. Through classification tasks involving recognizing ship types and marine mammal vocalizations, our method demonstrates to produce robust and generalized embeddings. This shows to potential of unsupervised methods for various automatic underwater acoustic analysis tasks.
Unveiling the Potential: Harnessing Deep Metric Learning to Circumvent Video Streaming Encryption
May 16, 2024Encryption on the internet with the shift to HTTPS has been an important step to improve the privacy of internet users. However, there is an increasing body of work about extracting information from encrypted internet traffic without having to decrypt it. Such attacks bypass security guarantees assumed to be given by HTTPS and thus need to be understood. Prior works showed that the variable bitrates of video streams are sufficient to identify which video someone is watching. These works generally have to make trade-offs in aspects such as accuracy, scalability, robustness, etc. These trade-offs complicate the practical use of these attacks. To that end, we propose a deep metric learning framework based on the triplet loss method. Through this framework, we achieve robust, generalisable, scalable and transferable encrypted video stream detection. First, the triplet loss is better able to deal with video streams not seen during training. Second, our approach can accurately classify videos not seen during training. Third, we show that our method scales well to a dataset of over 1000 videos. Finally, we show that a model trained on video streams over Chrome can also classify streams over Firefox. Our results suggest that this side-channel attack is more broadly applicable than originally thought. We provide our code alongside a diverse and up-to-date dataset for future research.
A Machine Learning Approach for Simultaneous Demapping of QAM and APSK Constellations
May 16, 2024



As telecommunication systems evolve to meet increasing demands, integrating deep neural networks (DNNs) has shown promise in enhancing performance. However, the trade-off between accuracy and flexibility remains challenging when replacing traditional receivers with DNNs. This paper introduces a novel probabilistic framework that allows a single DNN demapper to demap multiple QAM and APSK constellations simultaneously. We also demonstrate that our framework allows exploiting hierarchical relationships in families of constellations. The consequence is that we need fewer neural network outputs to encode the same function without an increase in Bit Error Rate (BER). Our simulation results confirm that our approach approaches the optimal demodulation error bound under an Additive White Gaussian Noise (AWGN) channel for multiple constellations. Thereby, we address multiple important issues in making DNNs flexible enough for practical use as receivers.
Robustly overfitting latents for flexible neural image compression
Jan 31, 2024Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models. We extend this idea by introducing SGA+, which contains three different methods that build upon SGA. Further, we give a detailed analysis of our proposed methods, show how they improve performance, and show that they are less sensitive to hyperparameter choices. Besides, we show how each method can be extended to three- instead of two-class rounding. Finally, we show how refinement of the latents with our best-performing method improves the compression performance on the Tecnick dataset and how it can be deployed to partly move along the rate-distortion curve.
Learning to Request Guidance in Emergent Communication
Dec 11, 2019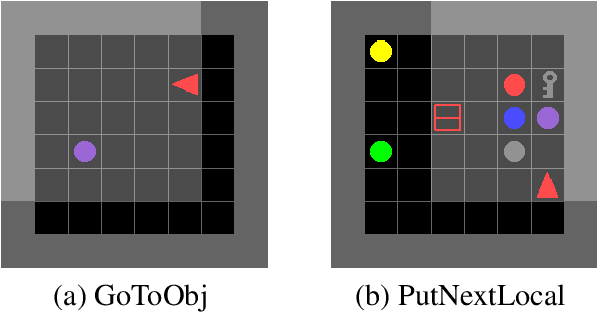
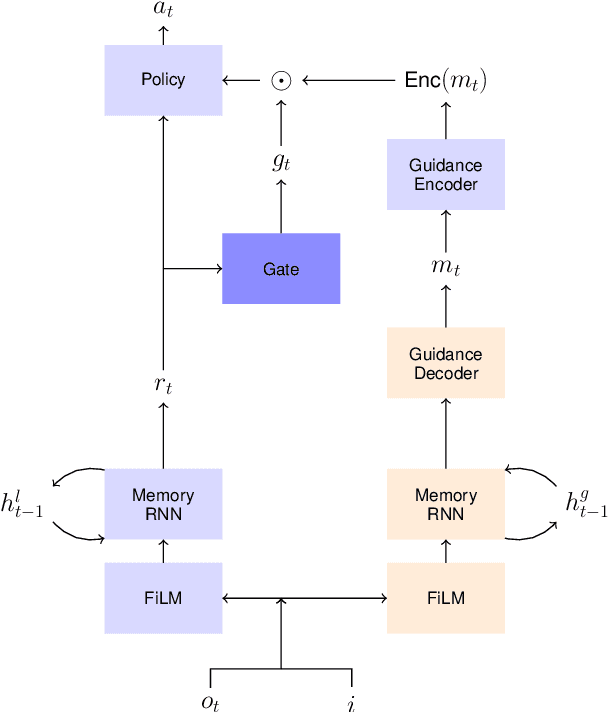
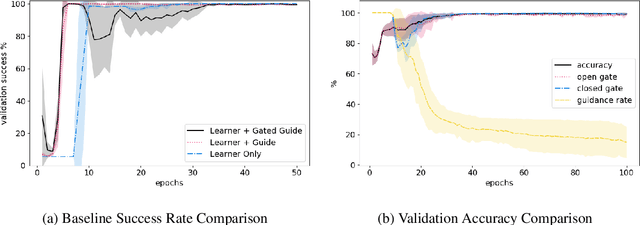
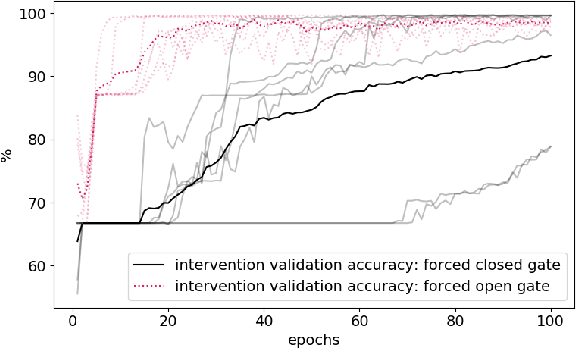
Previous research into agent communication has shown that a pre-trained guide can speed up the learning process of an imitation learning agent. The guide achieves this by providing the agent with discrete messages in an emerged language about how to solve the task. We extend this one-directional communication by a one-bit communication channel from the learner back to the guide: It is able to ask the guide for help, and we limit the guidance by penalizing the learner for these requests. During training, the agent learns to control this gate based on its current observation. We find that the amount of requested guidance decreases over time and guidance is requested in situations of high uncertainty. We investigate the agent's performance in cases of open and closed gates and discuss potential motives for the observed gating behavior.