 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Human-like Biases in Moral Reasoning Language Models
Nov 23, 2024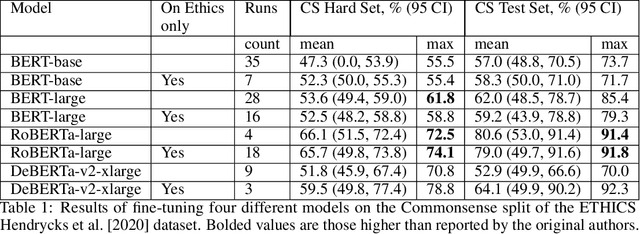
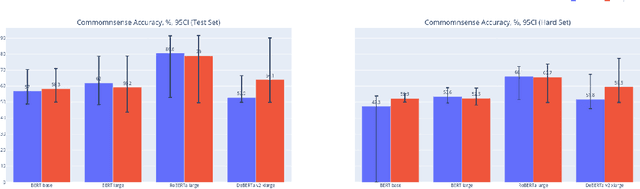
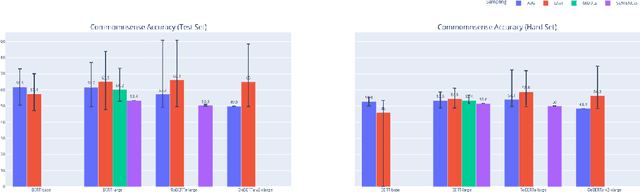
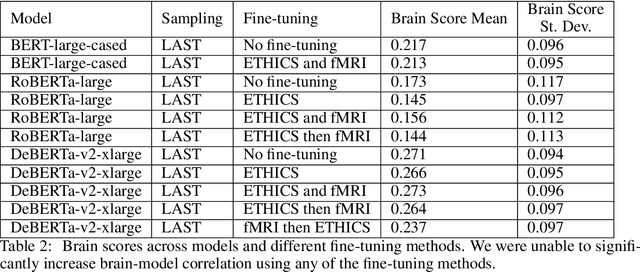
In this work, we study the alignment (BrainScore) of large language models (LLMs) fine-tuned for moral reasoning on behavioral data and/or brain data of humans performing the same task. We also explore if fine-tuning several LLMs on the fMRI data of humans performing moral reasoning can improve the BrainScore. We fine-tune several LLMs (BERT, RoBERTa, DeBERTa) on moral reasoning behavioral data from the ETHICS benchmark [Hendrycks et al., 2020], on the moral reasoning fMRI data from Koster-Hale et al. [2013], or on both. We study both the accuracy on the ETHICS benchmark and the BrainScores between model activations and fMRI data. While larger models generally performed better on both metrics, BrainScores did not significantly improve after fine-tuning.
Learning to Request Guidance in Emergent Communication
Dec 11, 2019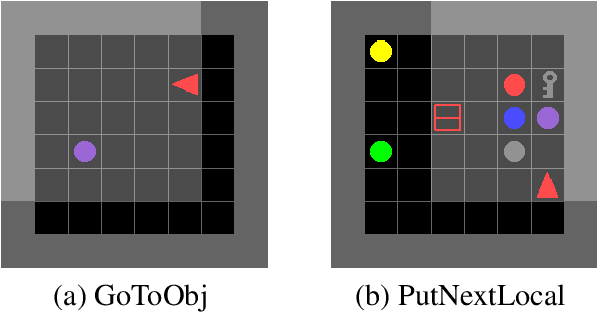
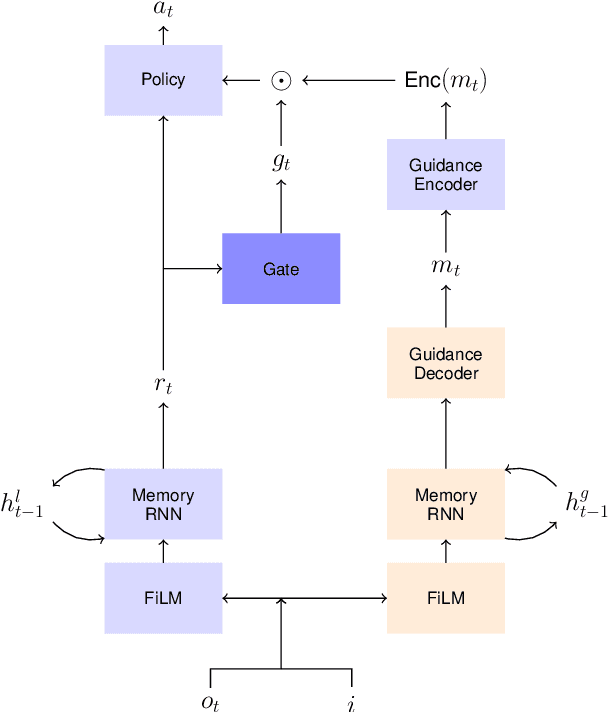
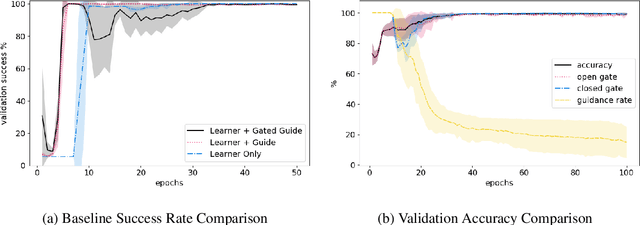
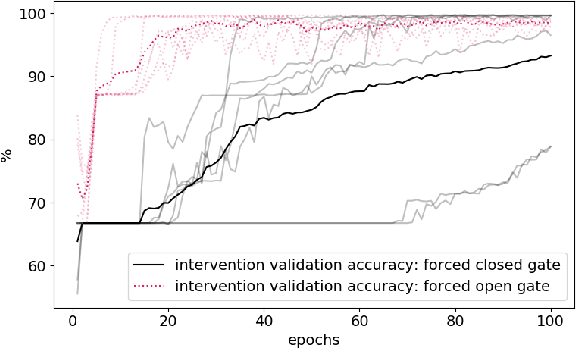
Previous research into agent communication has shown that a pre-trained guide can speed up the learning process of an imitation learning agent. The guide achieves this by providing the agent with discrete messages in an emerged language about how to solve the task. We extend this one-directional communication by a one-bit communication channel from the learner back to the guide: It is able to ask the guide for help, and we limit the guidance by penalizing the learner for these requests. During training, the agent learns to control this gate based on its current observation. We find that the amount of requested guidance decreases over time and guidance is requested in situations of high uncertainty. We investigate the agent's performance in cases of open and closed gates and discuss potential motives for the observed gating behavior.