Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback Recurrent AutoEncoder
Paper and Code
Nov 11, 2019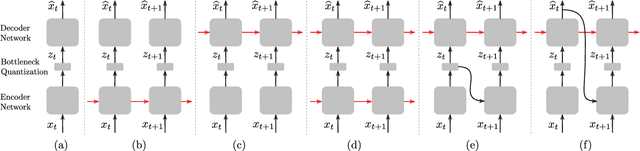
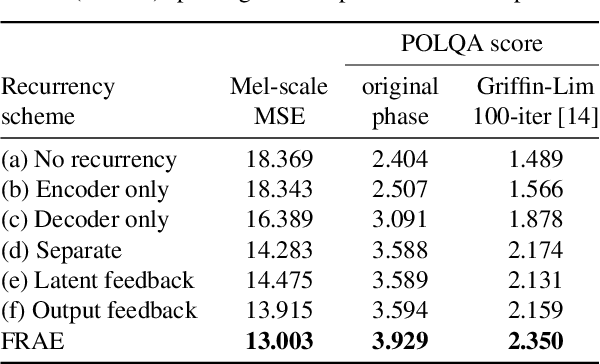
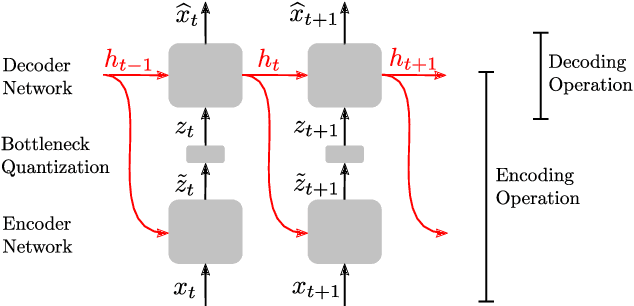
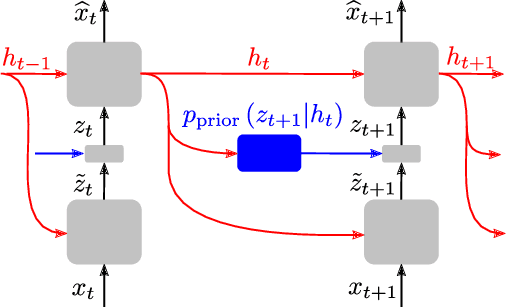
In this work, we propose a new recurrent autoencoder architecture, termed Feedback Recurrent AutoEncoder (FRAE), for online compression of sequential data with temporal dependency. The recurrent structure of FRAE is designed to efficiently extract the redundancy along the time dimension and allows a compact discrete representation of the data to be learned. We demonstrate its effectiveness in speech spectrogram compression. Specifically, we show that the FRAE, paired with a powerful neural vocoder, can produce high-quality speech waveforms at a low, fixed bitrate. We further show that by adding a learned prior for the latent space and using an entropy coder, we can achieve an even lower variable bitrate.
View paper on