 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark Experience for General Continual Learning: a Strong, Simple Baseline
Paper and Code


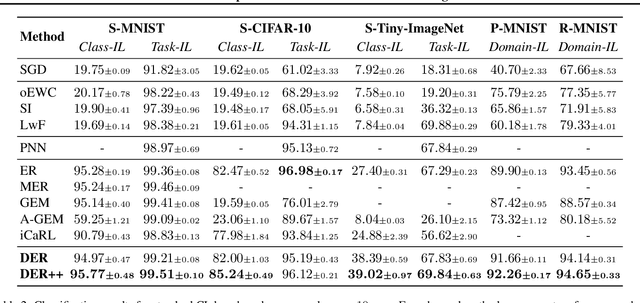

Neural networks struggle to learn continuously, as they forget the old knowledge catastrophically whenever the data distribution changes over time. Recently, Continual Learning has inspired a plethora of approaches and evaluation settings; however, the majority of them overlooks the properties of a practical scenario, where the data stream cannot be shaped as a sequence of tasks and offline training is not viable. We work towards General Continual Learning (GCL), where task boundaries blur and the domain and class distributions shift either gradually or suddenly. We address it through Dark Experience Replay, namely matching the network's logits sampled throughout the optimization trajectory, thus promoting consistency with its past. By conducting an extensive analysis on top of standard benchmarks, we show that such a seemingly simple baseline outperforms consolidated approaches and leverages limited resources. To provide a better understanding, we further introduce MNIST-360, a novel GCL evaluation setting.