 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewMorpher3D: A 3D-aware Diffusion Framework for Multi-Camera Novel View Synthesis in Autonomous Driving
Jan 13, 2026Autonomous driving systems rely heavily on multi-view images to ensure accurate perception and robust decision-making. To effectively develop and evaluate perception stacks and planning algorithms, realistic closed-loop simulators are indispensable. While 3D reconstruction techniques such as Gaussian Splatting offer promising avenues for simulator construction, the rendered novel views often exhibit artifacts, particularly in extrapolated perspectives or when available observations are sparse. We introduce ViewMorpher3D, a multi-view image enhancement framework based on image diffusion models, designed to elevate photorealism and multi-view coherence in driving scenes. Unlike single-view approaches, ViewMorpher3D jointly processes a set of rendered views conditioned on camera poses, 3D geometric priors, and temporally adjacent or spatially overlapping reference views. This enables the model to infer missing details, suppress rendering artifacts, and enforce cross-view consistency. Our framework accommodates variable numbers of cameras and flexible reference/target view configurations, making it adaptable to diverse sensor setups. Experiments on real-world driving datasets demonstrate substantial improvements in image quality metrics, effectively reducing artifacts while preserving geometric fidelity.
Gaussian Splatting is an Effective Data Generator for 3D Object Detection
Apr 23, 2025



We investigate data augmentation for 3D object detection in autonomous driving. We utilize recent advancements in 3D reconstruction based on Gaussian Splatting for 3D object placement in driving scenes. Unlike existing diffusion-based methods that synthesize images conditioned on BEV layouts, our approach places 3D objects directly in the reconstructed 3D space with explicitly imposed geometric transformations. This ensures both the physical plausibility of object placement and highly accurate 3D pose and position annotations. Our experiments demonstrate that even by integrating a limited number of external 3D objects into real scenes, the augmented data significantly enhances 3D object detection performance and outperforms existing diffusion-based 3D augmentation for object detection. Extensive testing on the nuScenes dataset reveals that imposing high geometric diversity in object placement has a greater impact compared to the appearance diversity of objects. Additionally, we show that generating hard examples, either by maximizing detection loss or imposing high visual occlusion in camera images, does not lead to more efficient 3D data augmentation for camera-based 3D object detection in autonomous driving.
Planar Gaussian Splatting
Dec 02, 2024



This paper presents Planar Gaussian Splatting (PGS), a novel neural rendering approach to learn the 3D geometry and parse the 3D planes of a scene, directly from multiple RGB images. The PGS leverages Gaussian primitives to model the scene and employ a hierarchical Gaussian mixture approach to group them. Similar Gaussians are progressively merged probabilistically in the tree-structured Gaussian mixtures to identify distinct 3D plane instances and form the overall 3D scene geometry. In order to enable the grouping, the Gaussian primitives contain additional parameters, such as plane descriptors derived by lifting 2D masks from a general 2D segmentation model and surface normals. Experiments show that the proposed PGS achieves state-of-the-art performance in 3D planar reconstruction without requiring either 3D plane labels or depth supervision. In contrast to existing supervised methods that have limited generalizability and struggle under domain shift, PGS maintains its performance across datasets thanks to its neural rendering and scene-specific optimization mechanism, while also being significantly faster than existing optimization-based approaches.
Neural Mesh Fusion: Unsupervised 3D Planar Surface Understanding
Feb 26, 2024



This paper presents Neural Mesh Fusion (NMF), an efficient approach for joint optimization of polygon mesh from multi-view image observations and unsupervised 3D planar-surface parsing of the scene. In contrast to implicit neural representations, NMF directly learns to deform surface triangle mesh and generate an embedding for unsupervised 3D planar segmentation through gradient-based optimization directly on the surface mesh. The conducted experiments show that NMF obtains competitive results compared to state-of-the-art multi-view planar reconstruction, while not requiring any ground-truth 3D or planar supervision. Moreover, NMF is significantly more computationally efficient compared to implicit neural rendering-based scene reconstruction approaches.
VaLID: Variable-Length Input Diffusion for Novel View Synthesis
Dec 14, 2023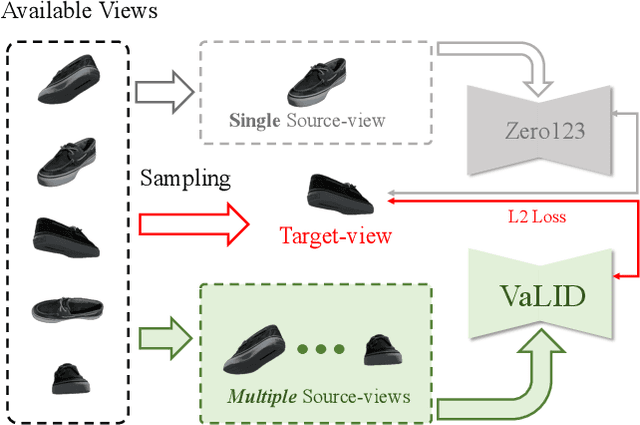

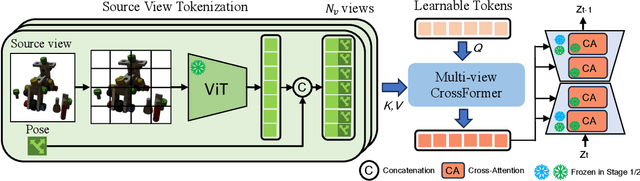
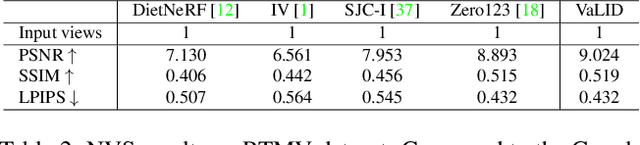
Novel View Synthesis (NVS), which tries to produce a realistic image at the target view given source view images and their corresponding poses, is a fundamental problem in 3D Vision. As this task is heavily under-constrained, some recent work, like Zero123, tries to solve this problem with generative modeling, specifically using pre-trained diffusion models. Although this strategy generalizes well to new scenes, compared to neural radiance field-based methods, it offers low levels of flexibility. For example, it can only accept a single-view image as input, despite realistic applications often offering multiple input images. This is because the source-view images and corresponding poses are processed separately and injected into the model at different stages. Thus it is not trivial to generalize the model into multi-view source images, once they are available. To solve this issue, we try to process each pose image pair separately and then fuse them as a unified visual representation which will be injected into the model to guide image synthesis at the target-views. However, inconsistency and computation costs increase as the number of input source-view images increases. To solve these issues, the Multi-view Cross Former module is proposed which maps variable-length input data to fix-size output data. A two-stage training strategy is introduced to further improve the efficiency during training time. Qualitative and quantitative evaluation over multiple datasets demonstrates the effectiveness of the proposed method against previous approaches. The code will be released according to the acceptance.
Automated Segmentation of Lesions in Ultrasound Using Semi-pixel-wise Cycle Generative Adversarial Nets
May 27, 2019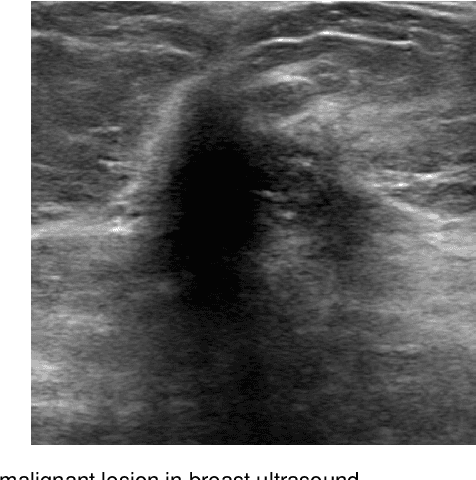
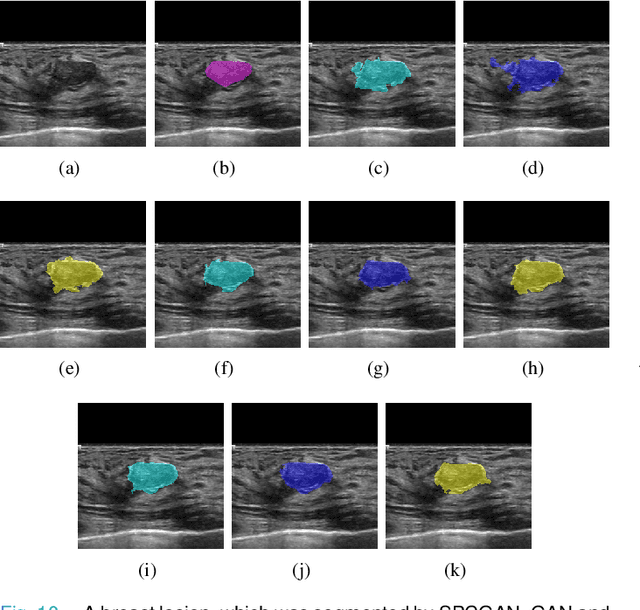
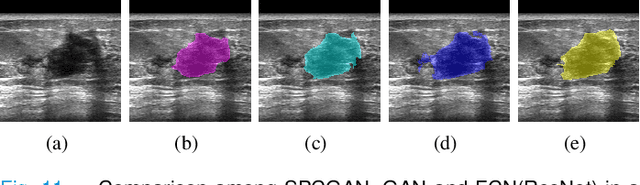
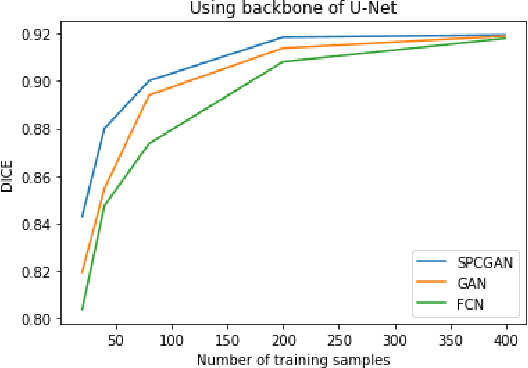
Breast cancer is the most common invasive cancer with the highest cancer occurrence in females. Handheld ultrasound is one of the most efficient ways to identify and diagnose the breast cancer. The area and the shape information of a lesion is very helpful for clinicians to make diagnostic decisions. In this study we propose a new deep-learning scheme, semi-pixel-wise cycle generative adversarial net (SPCGAN) for segmenting the lesion in 2D ultrasound. The method takes the advantage of a fully connected convolutional neural network (FCN) and a generative adversarial net to segment a lesion by using prior knowledge. We compared the proposed method to a fully connected neural network and the level set segmentation method on a test dataset consisting of 32 malignant lesions and 109 benign lesions. Our proposed method achieved a Dice similarity coefficient (DSC) of 0.92 while FCN and the level set achieved 0.90 and 0.79 respectively. Particularly, for malignant lesions, our method increases the DSC (0.90) of the fully connected neural network to 0.93 significantly (p$<$0.001). The results show that our SPCGAN can obtain robust segmentation results and may be used to relieve the radiologists' burden for annotation.