 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
Neural Mesh Fusion: Unsupervised 3D Planar Surface Understanding
Feb 26, 2024



This paper presents Neural Mesh Fusion (NMF), an efficient approach for joint optimization of polygon mesh from multi-view image observations and unsupervised 3D planar-surface parsing of the scene. In contrast to implicit neural representations, NMF directly learns to deform surface triangle mesh and generate an embedding for unsupervised 3D planar segmentation through gradient-based optimization directly on the surface mesh. The conducted experiments show that NMF obtains competitive results compared to state-of-the-art multi-view planar reconstruction, while not requiring any ground-truth 3D or planar supervision. Moreover, NMF is significantly more computationally efficient compared to implicit neural rendering-based scene reconstruction approaches.
Hyperbolic Vision Transformers: Combining Improvements in Metric Learning
Mar 22, 2022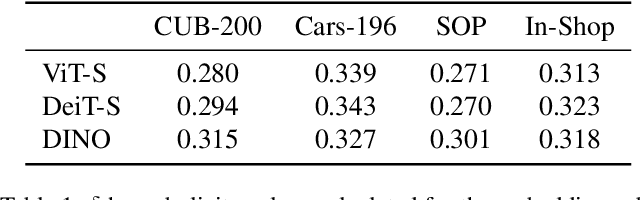

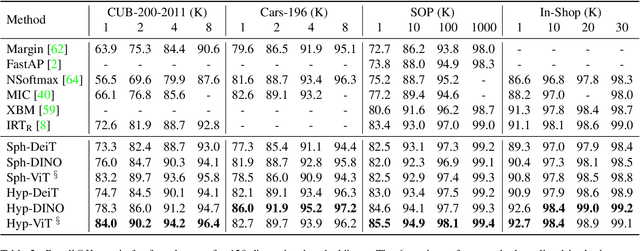
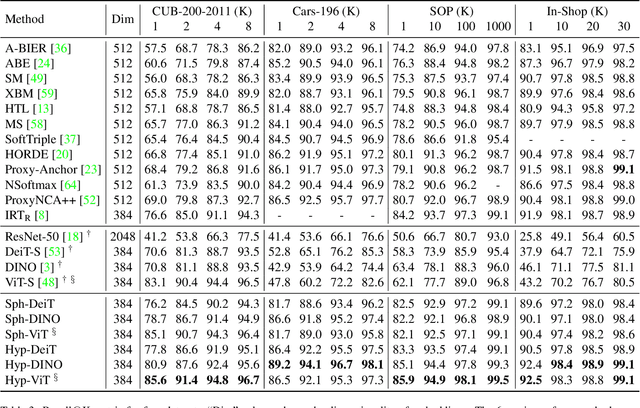
Metric learning aims to learn a highly discriminative model encouraging the embeddings of similar classes to be close in the chosen metrics and pushed apart for dissimilar ones. The common recipe is to use an encoder to extract embeddings and a distance-based loss function to match the representations -- usually, the Euclidean distance is utilized. An emerging interest in learning hyperbolic data embeddings suggests that hyperbolic geometry can be beneficial for natural data. Following this line of work, we propose a new hyperbolic-based model for metric learning. At the core of our method is a vision transformer with output embeddings mapped to hyperbolic space. These embeddings are directly optimized using modified pairwise cross-entropy loss. We evaluate the proposed model with six different formulations on four datasets achieving the new state-of-the-art performance. The source code is available at https://github.com/htdt/hyp_metric.
Latent Transformations via NeuralODEs for GAN-based Image Editing
Nov 29, 2021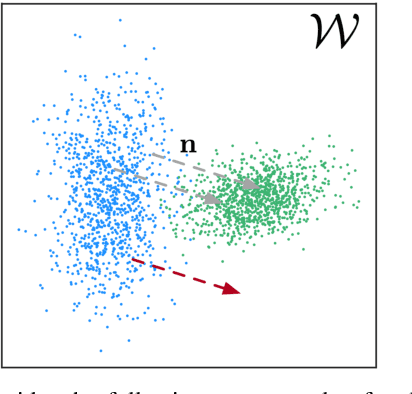

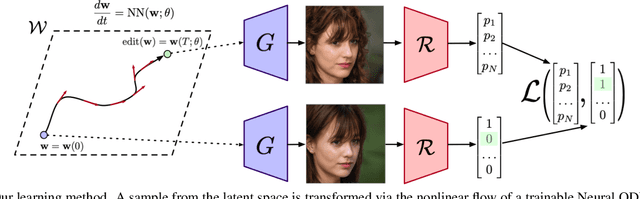
Recent advances in high-fidelity semantic image editing heavily rely on the presumably disentangled latent spaces of the state-of-the-art generative models, such as StyleGAN. Specifically, recent works show that it is possible to achieve decent controllability of attributes in face images via linear shifts along with latent directions. Several recent methods address the discovery of such directions, implicitly assuming that the state-of-the-art GANs learn the latent spaces with inherently linearly separable attribute distributions and semantic vector arithmetic properties. In our work, we show that nonlinear latent code manipulations realized as flows of a trainable Neural ODE are beneficial for many practical non-face image domains with more complex non-textured factors of variation. In particular, we investigate a large number of datasets with known attributes and demonstrate that certain attribute manipulations are challenging to obtain with linear shifts only.
Disentangled Representations from Non-Disentangled Models
Feb 11, 2021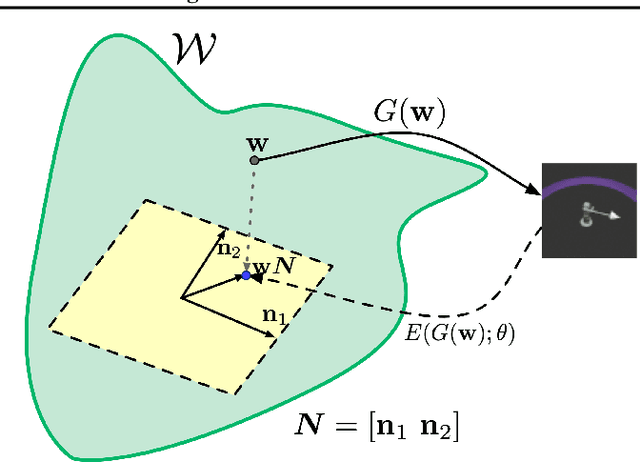
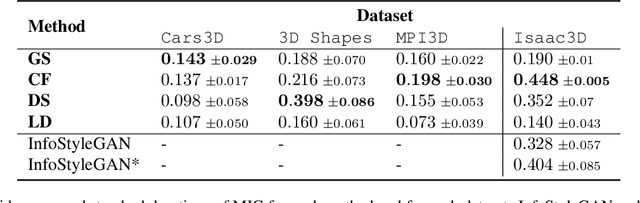
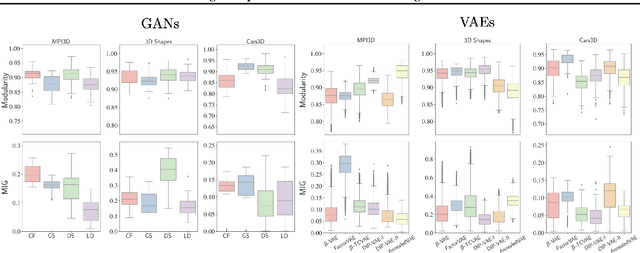

Constructing disentangled representations is known to be a difficult task, especially in the unsupervised scenario. The dominating paradigm of unsupervised disentanglement is currently to train a generative model that separates different factors of variation in its latent space. This separation is typically enforced by training with specific regularization terms in the model's objective function. These terms, however, introduce additional hyperparameters responsible for the trade-off between disentanglement and generation quality. While tuning these hyperparameters is crucial for proper disentanglement, it is often unclear how to tune them without external supervision. This paper investigates an alternative route to disentangled representations. Namely, we propose to extract such representations from the state-of-the-art generative models trained without disentangling terms in their objectives. This paradigm of post hoc disentanglement employs little or no hyperparameters when learning representations while achieving results on par with existing state-of-the-art, as shown by comparison in terms of established disentanglement metrics, fairness, and the abstract reasoning task. All our code and models are publicly available.
Performance of Hyperbolic Geometry Models on Top-N Recommendation Tasks
Aug 15, 2020
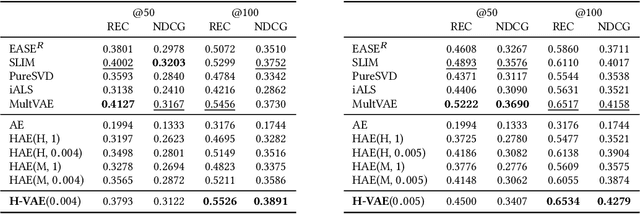
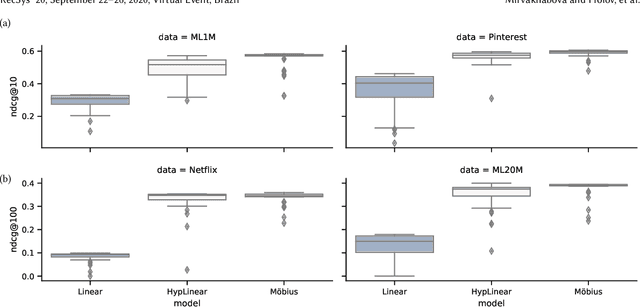
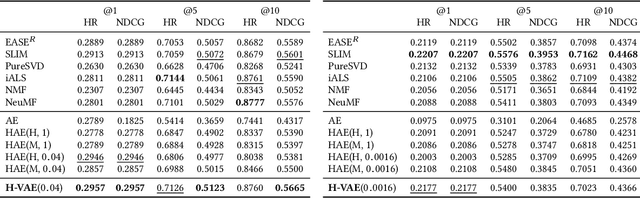
We introduce a simple autoencoder based on hyperbolic geometry for solving standard collaborative filtering problem. In contrast to many modern deep learning techniques, we build our solution using only a single hidden layer. Remarkably, even with such a minimalistic approach, we not only outperform the Euclidean counterpart but also achieve a competitive performance with respect to the current state-of-the-art. We additionally explore the effects of space curvature on the quality of hyperbolic models and propose an efficient data-driven method for estimating its optimal value.
Hyperbolic Image Embeddings
Apr 03, 2019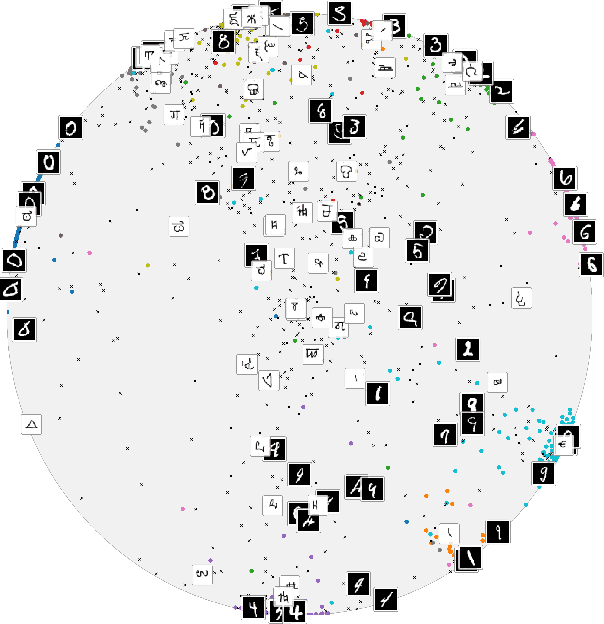
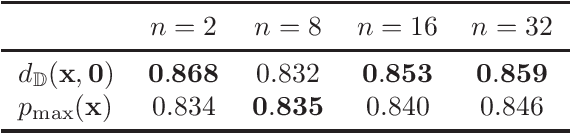
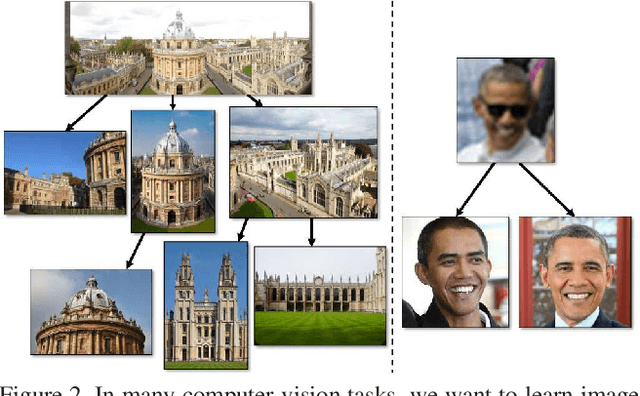
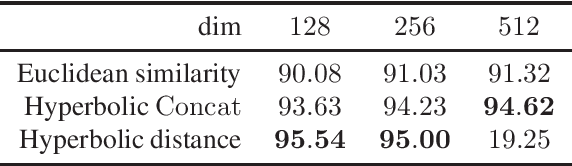
Computer vision tasks such as image classification, image retrieval and few-shot learning are currently dominated by Euclidean and spherical embeddings, so that the final decisions about class belongings or the degree of similarity are made using linear hyperplanes, Euclidean distances, or spherical geodesic distances (cosine similarity). In this work, we demonstrate that in many practical scenarios hyperbolic embeddings provide a better alternative.
Tensorized Embedding Layers for Efficient Model Compression
Jan 30, 2019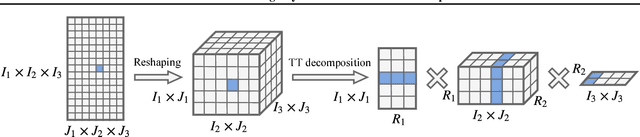

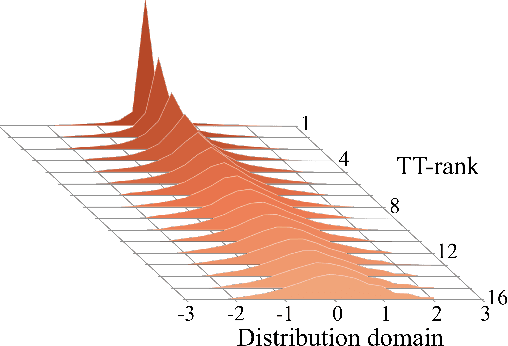
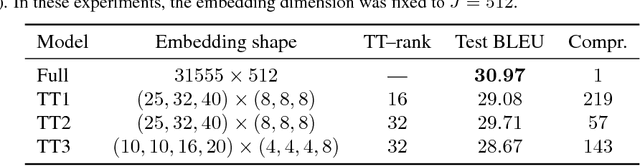
The embedding layers transforming input words into real vectors are the key components of deep neural networks used in natural language processing. However, when the vocabulary is large (e.g., 800k unique words in the One-Billion-Word dataset), the corresponding weight matrices can be enormous, which precludes their deployment in a limited resource setting. We introduce a novel way of parametrizing embedding layers based on the Tensor Train (TT) decomposition, which allows compressing the model significantly at the cost of a negligible drop or even a slight gain in performance. Importantly, our method does not take the pre-trained model and compress its weights but rather supplants the standard embedding layers with their TT-based counterparts. The resulting model is then trained end-to-end, however, it can capitalize on larger batches due to the reduced memory requirements. We evaluate our method on a wide range of benchmarks in sentiment analysis, neural machine translation, and language modeling, and analyze the trade-off between performance and compression ratios for a wide range of architectures, from MLPs to LSTMs and Transformers.