 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tool Dependency Retrieval for Efficient Function Calling
Dec 23, 2025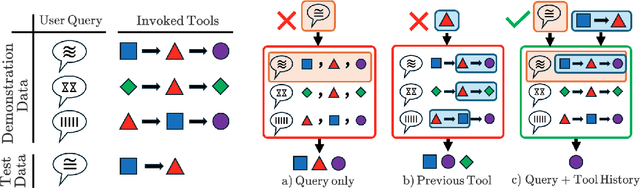

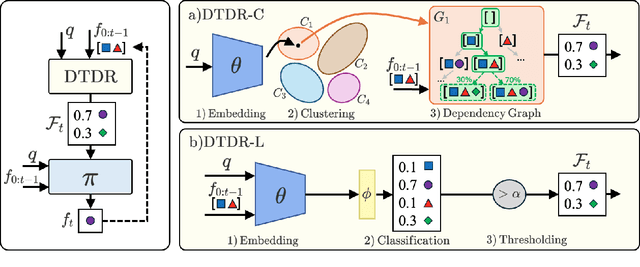
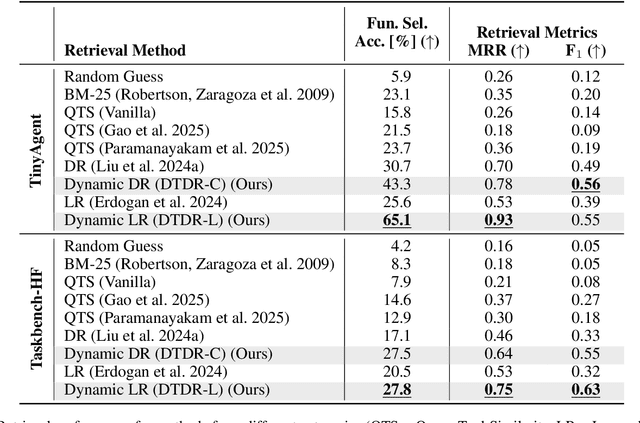
Function calling agents powered by Large Language Models (LLMs) select external tools to automate complex tasks. On-device agents typically use a retrieval module to select relevant tools, improving performance and reducing context length. However, existing retrieval methods rely on static and limited inputs, failing to capture multi-step tool dependencies and evolving task context. This limitation often introduces irrelevant tools that mislead the agent, degrading efficiency and accuracy. We propose Dynamic Tool Dependency Retrieval (DTDR), a lightweight retrieval method that conditions on both the initial query and the evolving execution context. DTDR models tool dependencies from function calling demonstrations, enabling adaptive retrieval as plans unfold. We benchmark DTDR against state-of-the-art retrieval methods across multiple datasets and LLM backbones, evaluating retrieval precision, downstream task accuracy, and computational efficiency. Additionally, we explore strategies to integrate retrieved tools into prompts. Our results show that dynamic tool retrieval improves function calling success rates between $23\%$ and $104\%$ compared to state-of-the-art static retrievers.
Neural 5G Indoor Localization with IMU Supervision
Feb 15, 2024



Radio signals are well suited for user localization because they are ubiquitous, can operate in the dark and maintain privacy. Many prior works learn mappings between channel state information (CSI) and position fully-supervised. However, that approach relies on position labels which are very expensive to acquire. In this work, this requirement is relaxed by using pseudo-labels during deployment, which are calculated from an inertial measurement unit (IMU). We propose practical algorithms for IMU double integration and training of the localization system. We show decimeter-level accuracy on simulated and challenging real data of 5G measurements. Our IMU-supervised method performs similarly to fully-supervised, but requires much less effort to deploy.
Temporal Alignment for History Representation in Reinforcement Learning
Apr 07, 2022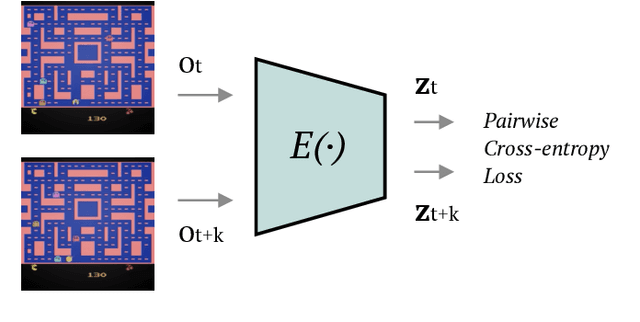
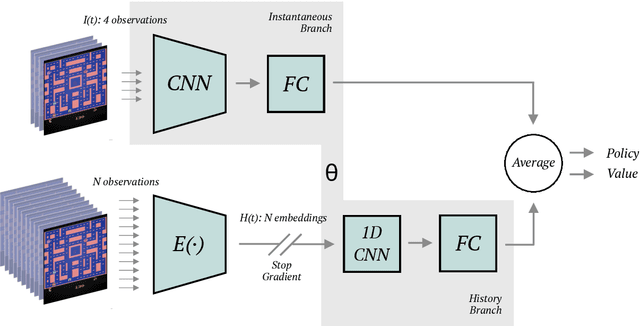
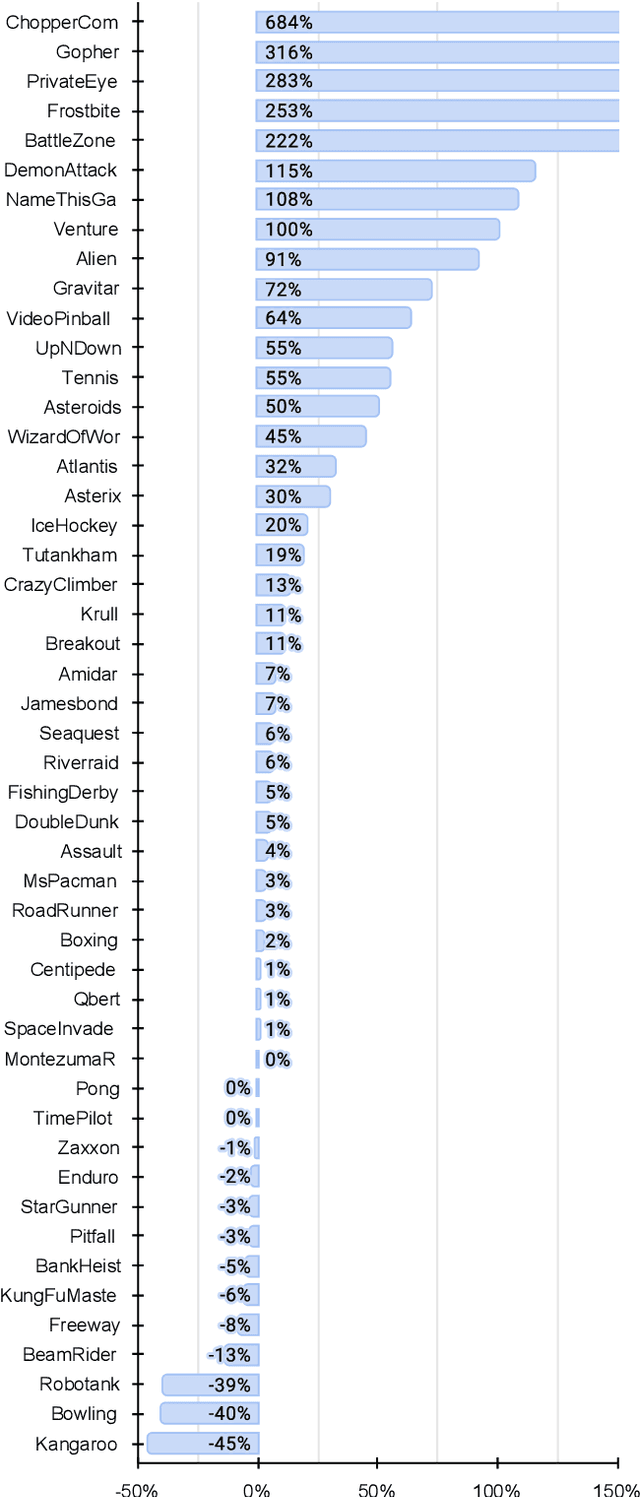
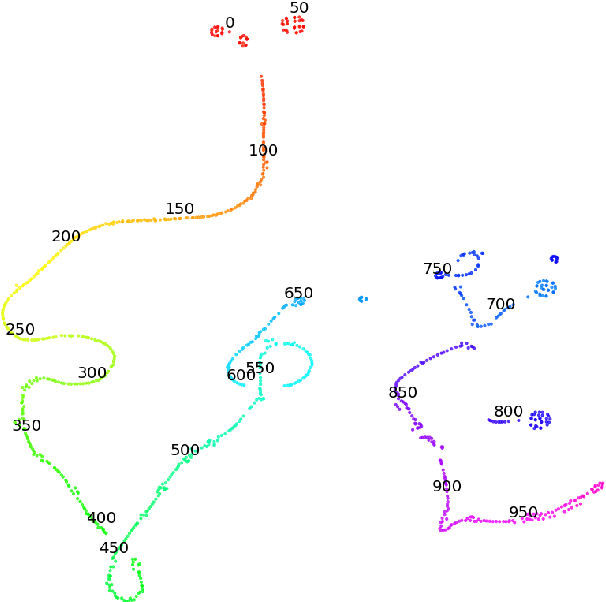
Environments in Reinforcement Learning are usually only partially observable. To address this problem, a possible solution is to provide the agent with information about the past. However, providing complete observations of numerous steps can be excessive. Inspired by human memory, we propose to represent history with only important changes in the environment and, in our approach, to obtain automatically this representation using self-supervision. Our method (TempAl) aligns temporally-close frames, revealing a general, slowly varying state of the environment. This procedure is based on contrastive loss, which pulls embeddings of nearby observations to each other while pushing away other samples from the batch. It can be interpreted as a metric that captures the temporal relations of observations. We propose to combine both common instantaneous and our history representation and we evaluate TempAl on all available Atari games from the Arcade Learning Environment. TempAl surpasses the instantaneous-only baseline in 35 environments out of 49. The source code of the method and of all the experiments is available at https://github.com/htdt/tempal.
Hyperbolic Vision Transformers: Combining Improvements in Metric Learning
Mar 22, 2022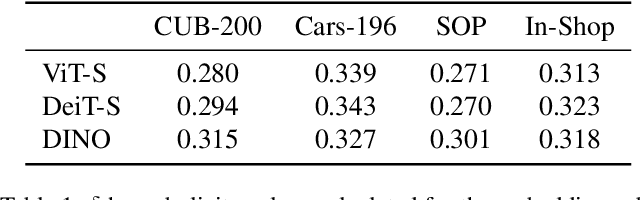

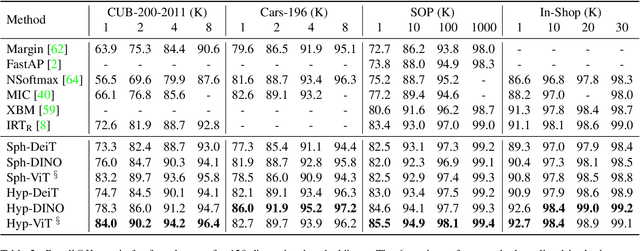
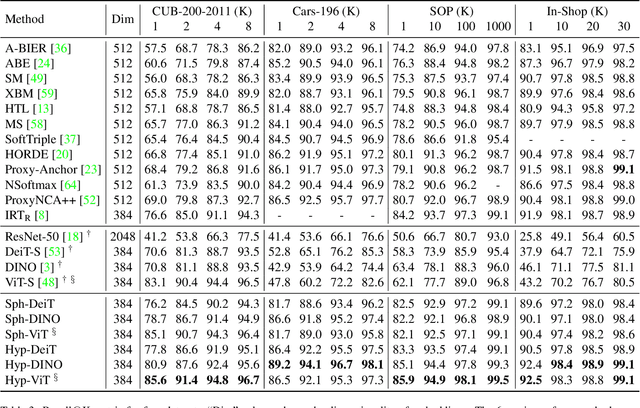
Metric learning aims to learn a highly discriminative model encouraging the embeddings of similar classes to be close in the chosen metrics and pushed apart for dissimilar ones. The common recipe is to use an encoder to extract embeddings and a distance-based loss function to match the representations -- usually, the Euclidean distance is utilized. An emerging interest in learning hyperbolic data embeddings suggests that hyperbolic geometry can be beneficial for natural data. Following this line of work, we propose a new hyperbolic-based model for metric learning. At the core of our method is a vision transformer with output embeddings mapped to hyperbolic space. These embeddings are directly optimized using modified pairwise cross-entropy loss. We evaluate the proposed model with six different formulations on four datasets achieving the new state-of-the-art performance. The source code is available at https://github.com/htdt/hyp_metric.
Latent World Models For Intrinsically Motivated Exploration
Oct 05, 2020



In this work we consider partially observable environments with sparse rewards. We present a self-supervised representation learning method for image-based observations, which arranges embeddings respecting temporal distance of observations. This representation is empirically robust to stochasticity and suitable for novelty detection from the error of a predictive forward model. We consider episodic and life-long uncertainties to guide the exploration. We propose to estimate the missing information about the environment with the world model, which operates in the learned latent space. As a motivation of the method, we analyse the exploration problem in a tabular Partially Observable Labyrinth. We demonstrate the method on image-based hard exploration environments from the Atari benchmark and report significant improvement with respect to prior work. The source code of the method and all the experiments is available at https://github.com/htdt/lwm.
Whitening for Self-Supervised Representation Learning
Jul 13, 2020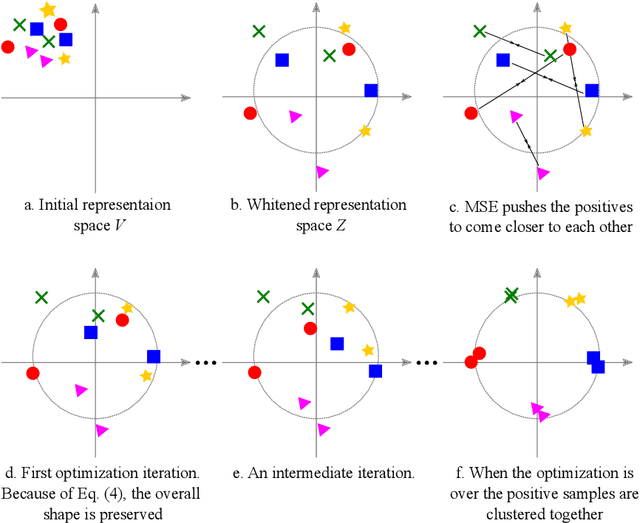
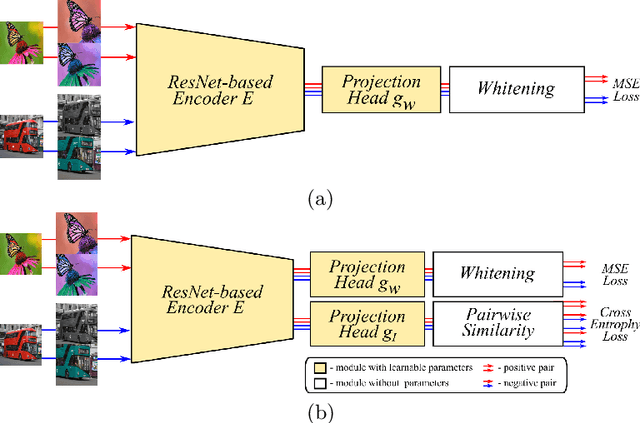
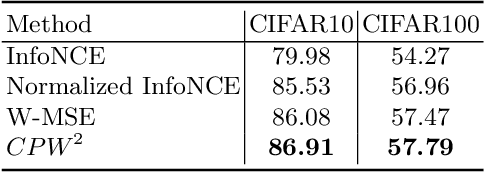
Recent literature on self-supervised learning is based on the contrastive loss, where image instances which share the same semantic content ("positives") are contrasted with instances extracted from other images ("negatives"). However, in order for the learning to be effective, a lot of negatives should be compared with a positive pair. This is not only computationally demanding, but it also requires that the positive and the negative representations are kept consistent with each other over a long training period. In this paper we propose a different direction and a new loss function for self-supervised learning which is based on the whitening of the latent-space features. The whitening operation has a "scattering" effect on the batch samples, which compensates the lack of a large number of negatives, avoiding degenerate solutions where all the sample representations collapse to a single point. We empirically show that our loss accelerates self-supervised training and the learned representations are much more effective for downstream tasks than previously published work.