 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhitening for Self-Supervised Representation Learning
Paper and Code
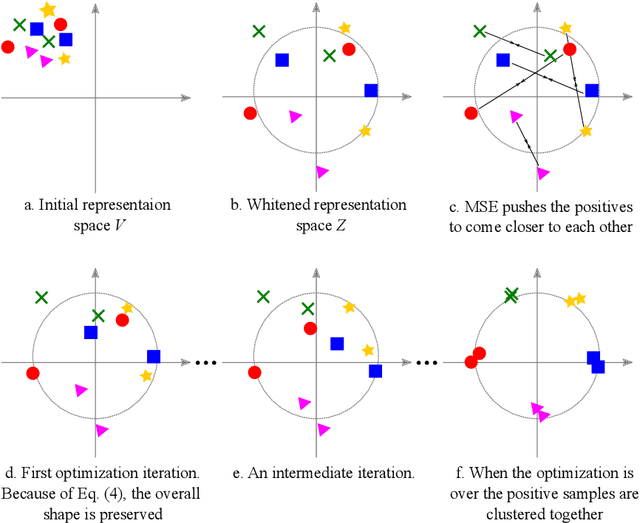
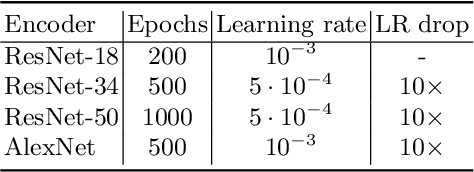
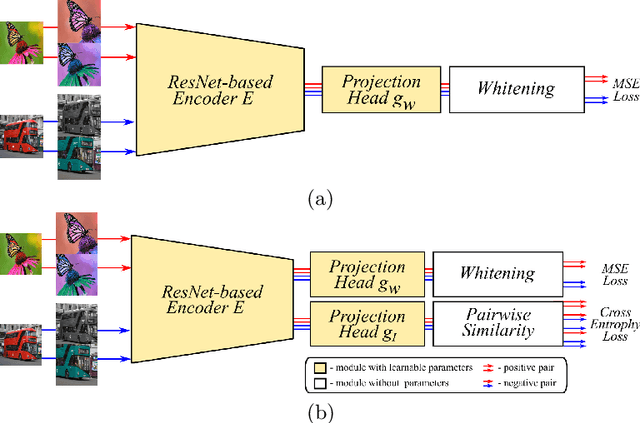
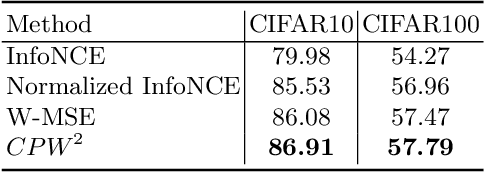
Recent literature on self-supervised learning is based on the contrastive loss, where image instances which share the same semantic content ("positives") are contrasted with instances extracted from other images ("negatives"). However, in order for the learning to be effective, a lot of negatives should be compared with a positive pair. This is not only computationally demanding, but it also requires that the positive and the negative representations are kept consistent with each other over a long training period. In this paper we propose a different direction and a new loss function for self-supervised learning which is based on the whitening of the latent-space features. The whitening operation has a "scattering" effect on the batch samples, which compensates the lack of a large number of negatives, avoiding degenerate solutions where all the sample representations collapse to a single point. We empirically show that our loss accelerates self-supervised training and the learned representations are much more effective for downstream tasks than previously published work.