 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Representations from Non-Disentangled Models
Paper and Code
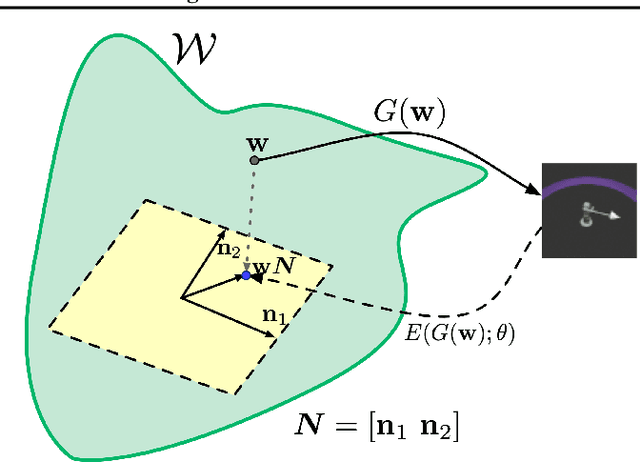
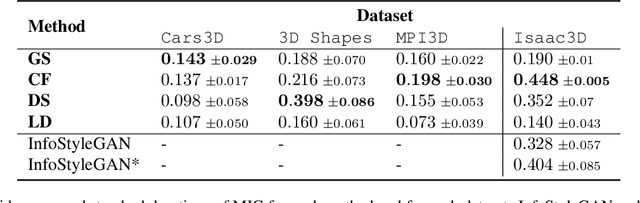
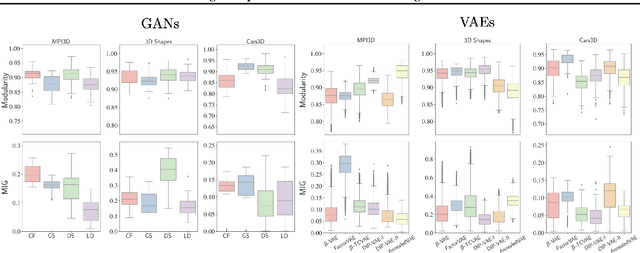

Constructing disentangled representations is known to be a difficult task, especially in the unsupervised scenario. The dominating paradigm of unsupervised disentanglement is currently to train a generative model that separates different factors of variation in its latent space. This separation is typically enforced by training with specific regularization terms in the model's objective function. These terms, however, introduce additional hyperparameters responsible for the trade-off between disentanglement and generation quality. While tuning these hyperparameters is crucial for proper disentanglement, it is often unclear how to tune them without external supervision. This paper investigates an alternative route to disentangled representations. Namely, we propose to extract such representations from the state-of-the-art generative models trained without disentangling terms in their objectives. This paradigm of post hoc disentanglement employs little or no hyperparameters when learning representations while achieving results on par with existing state-of-the-art, as shown by comparison in terms of established disentanglement metrics, fairness, and the abstract reasoning task. All our code and models are publicly available.