 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSENTRA: Selected-Next-Token Transformer for LLM Text Detection
Sep 15, 2025LLMs are becoming increasingly capable and widespread. Consequently, the potential and reality of their misuse is also growing. In this work, we address the problem of detecting LLM-generated text that is not explicitly declared as such. We present a novel, general-purpose, and supervised LLM text detector, SElected-Next-Token tRAnsformer (SENTRA). SENTRA is a Transformer-based encoder leveraging selected-next-token-probability sequences and utilizing contrastive pre-training on large amounts of unlabeled data. Our experiments on three popular public datasets across 24 domains of text demonstrate SENTRA is a general-purpose classifier that significantly outperforms popular baselines in the out-of-domain setting.
STARE: Predicting Decision Making Based on Spatio-Temporal Eye Movements
Aug 06, 2025
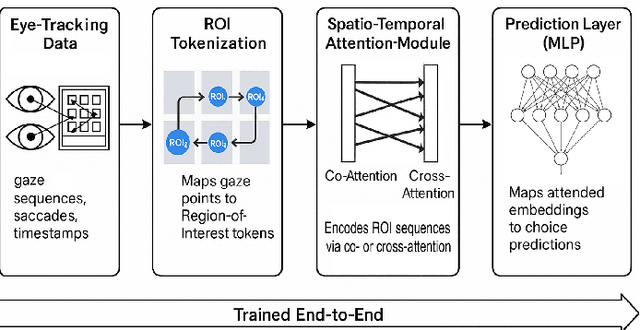


The present work proposes a Deep Learning architecture for the prediction of various consumer choice behaviors from time series of raw gaze or eye fixations on images of the decision environment, for which currently no foundational models are available. The architecture, called STARE (Spatio-Temporal Attention Representation for Eye Tracking), uses a new tokenization strategy, which involves mapping the x- and y- pixel coordinates of eye-movement time series on predefined, contiguous Regions of Interest. That tokenization makes the spatio-temporal eye-movement data available to the Chronos, a time-series foundation model based on the T5 architecture, to which co-attention and/or cross-attention is added to capture directional and/or interocular influences of eye movements. We compare STARE with several state-of-the art alternatives on multiple datasets with the purpose of predicting consumer choice behaviors from eye movements. We thus make a first step towards developing and testing DL architectures that represent visual attention dynamics rooted in the neurophysiology of eye movements.
Deep Pareto Reinforcement Learning for Multi-Objective Recommender System
Jul 04, 2024Optimizing multiple objectives simultaneously is an important task in recommendation platforms to improve their performance on different fronts. However, this task is particularly challenging since the relationships between different objectives are heterogeneous across different consumers and dynamically fluctuating according to different contexts. Especially in those cases when objectives become conflicting with each other, the result of recommendations will form a pareto-frontier, where the improvements on any objective comes at the cost of a performance decrease in another objective. Unfortunately, existing multi-objective recommender systems do not systematically consider such relationships; instead, they balance between these objectives in a static and uniform manner, resulting in performance that is significantly worse than the pareto-optimality. In this paper, we propose a Deep Pareto Reinforcement Learning (DeepPRL) approach, where we (1) comprehensively model the complex relationships between multiple objectives in recommendations; (2) effectively capture the personalized and contextual consumer preference towards each objective and update the recommendations correspondingly; (3) optimize both the short-term and the long-term performance of multi-objective recommendations. As a result, our method achieves significant pareto-dominance over state-of-the-art baselines in extensive offline experiments conducted on three real-world datasets. Furthermore, we conduct a large-scale online controlled experiment at the video streaming platform of Alibaba, where our method simultaneously improves the three conflicting objectives of Click-Through Rate, Video View, and Dwell Time by 2%, 5%, and 7% respectively over the latest production system, demonstrating its tangible economic impact in industrial applications.
The Long Tail of Context: Does it Exist and Matter?
Oct 03, 2022
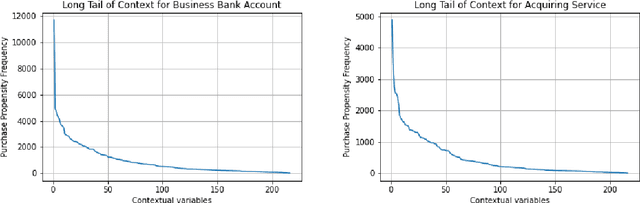
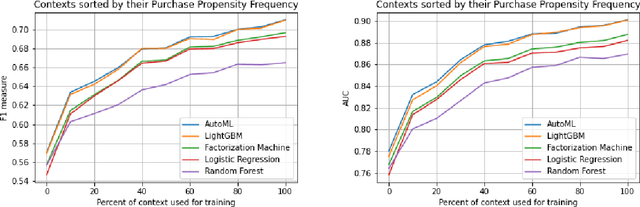
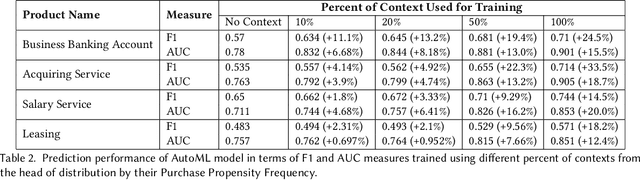
Context has been an important topic in recommender systems over the past two decades. A standard representational approach to context assumes that contextual variables and their structures are known in an application. Most of the prior CARS papers following representational approach manually selected and considered only a few crucial contextual variables in an application, such as time, location, and company of a person. This prior work demonstrated significant recommendation performance improvements when various CARS-based methods have been deployed in numerous applications. However, some recommender systems applications deal with a much bigger and broader types of contexts, and manually identifying and capturing a few contextual variables is not sufficient in such cases. In this paper, we study such ``context-rich'' applications dealing with a large variety of different types of contexts. We demonstrate that supporting only a few most important contextual variables, although useful, is not sufficient. In our study, we focus on the application that recommends various banking products to commercial customers within the context of dialogues initiated by customer service representatives. In this application, we managed to identify over two hundred types of contextual variables. Sorting those variables by their importance forms the Long Tail of Context (LTC). In this paper, we empirically demonstrate that LTC matters and using all these contextual variables from the Long Tail leads to significant improvements in recommendation performance.
LightAutoML: AutoML Solution for a Large Financial Services Ecosystem
Sep 03, 2021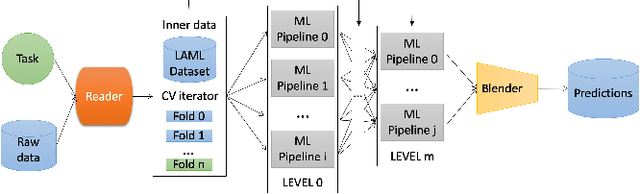


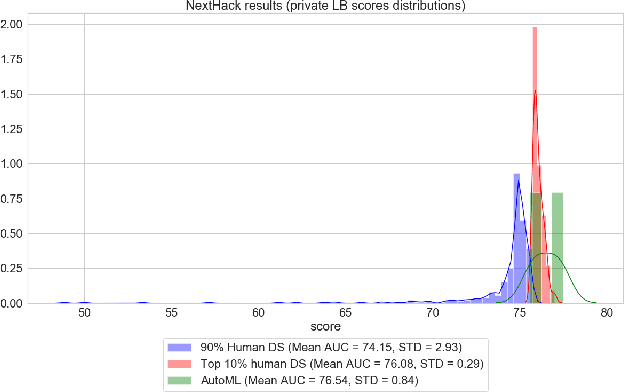
We present an AutoML system called LightAutoML developed for a large European financial services company and its ecosystem satisfying the set of idiosyncratic requirements that this ecosystem has for AutoML solutions. Our framework was piloted and deployed in numerous applications and performed at the level of the experienced data scientists while building high-quality ML models significantly faster than these data scientists. We also compare the performance of our system with various general-purpose open source AutoML solutions and show that it performs better for most of the ecosystem and OpenML problems. We also present the lessons that we learned while developing the AutoML system and moving it into production.
PURS: Personalized Unexpected Recommender System for Improving User Satisfaction
Jun 05, 2021
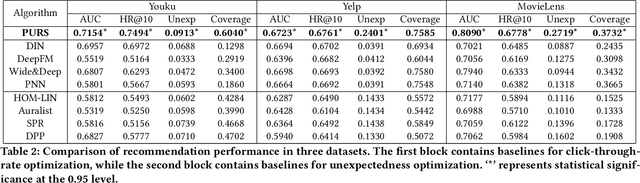
Classical recommender system methods typically face the filter bubble problem when users only receive recommendations of their familiar items, making them bored and dissatisfied. To address the filter bubble problem, unexpected recommendations have been proposed to recommend items significantly deviating from user's prior expectations and thus surprising them by presenting "fresh" and previously unexplored items to the users. In this paper, we describe a novel Personalized Unexpected Recommender System (PURS) model that incorporates unexpectedness into the recommendation process by providing multi-cluster modeling of user interests in the latent space and personalized unexpectedness via the self-attention mechanism and via selection of an appropriate unexpected activation function. Extensive offline experiments on three real-world datasets illustrate that the proposed PURS model significantly outperforms the state-of-the-art baseline approaches in terms of both accuracy and unexpectedness measures. In addition, we conduct an online A/B test at a major video platform Alibaba-Youku, where our model achieves over 3\% increase in the average video view per user metric. The proposed model is in the process of being deployed by the company.
Dual Attentive Sequential Learning for Cross-Domain Click-Through Rate Prediction
Jun 05, 2021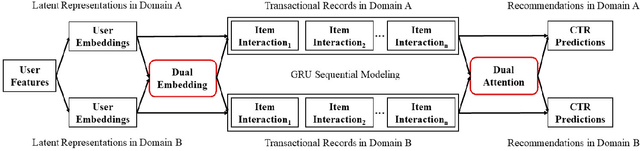
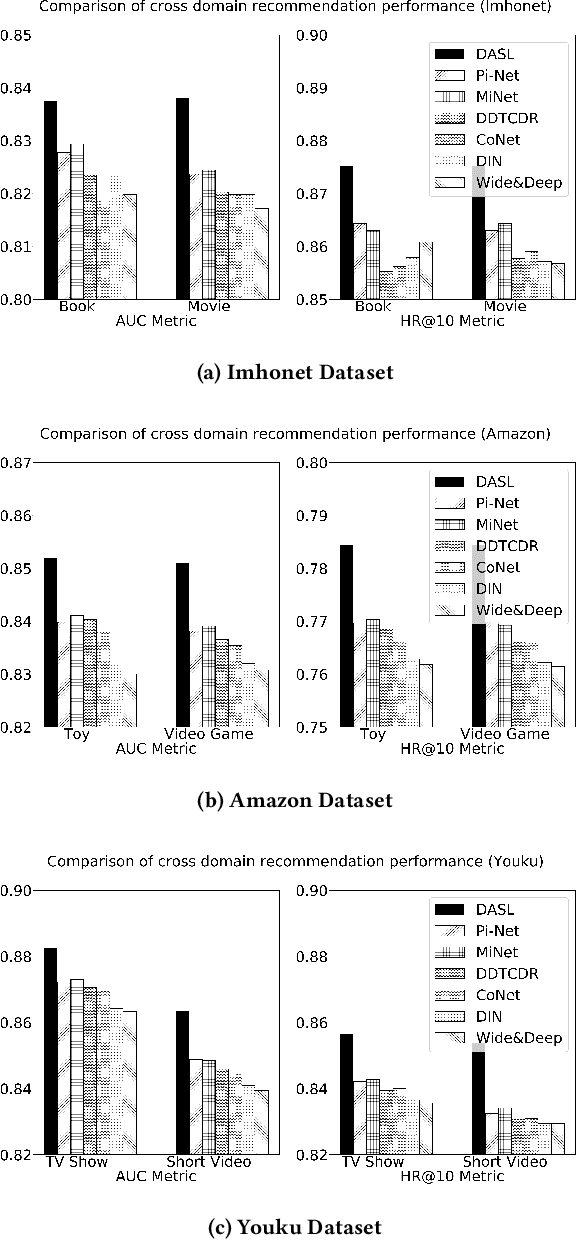
Cross domain recommender system constitutes a powerful method to tackle the cold-start and sparsity problem by aggregating and transferring user preferences across multiple category domains. Therefore, it has great potential to improve click-through-rate prediction performance in online commerce platforms having many domains of products. While several cross domain sequential recommendation models have been proposed to leverage information from a source domain to improve CTR predictions in a target domain, they did not take into account bidirectional latent relations of user preferences across source-target domain pairs. As such, they cannot provide enhanced cross-domain CTR predictions for both domains simultaneously. In this paper, we propose a novel approach to cross-domain sequential recommendations based on the dual learning mechanism that simultaneously transfers information between two related domains in an iterative manner until the learning process stabilizes. In particular, the proposed Dual Attentive Sequential Learning (DASL) model consists of two novel components Dual Embedding and Dual Attention, which jointly establish the two-stage learning process: we first construct dual latent embeddings that extract user preferences in both domains simultaneously, and subsequently provide cross-domain recommendations by matching the extracted latent embeddings with candidate items through dual-attention learning mechanism. We conduct extensive offline experiments on three real-world datasets to demonstrate the superiority of our proposed model, which significantly and consistently outperforms several state-of-the-art baselines across all experimental settings. We also conduct an online A/B test at a major video streaming platform Alibaba-Youku, where our proposed model significantly improves business performance over the latest production system in the company.
Dual Metric Learning for Effective and Efficient Cross-Domain Recommendations
Apr 20, 2021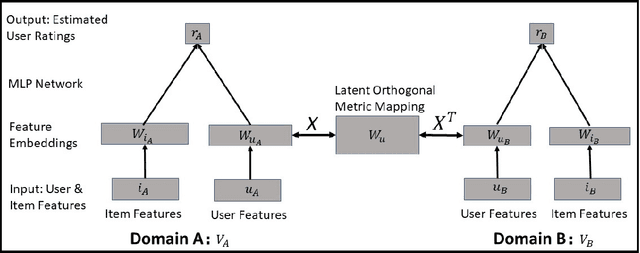
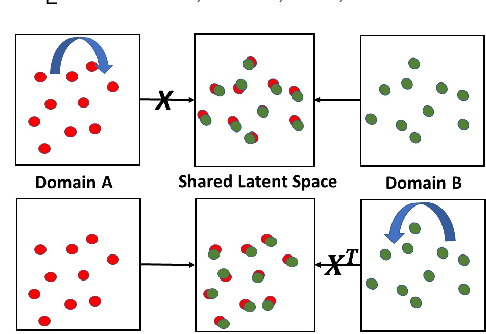
Cross domain recommender systems have been increasingly valuable for helping consumers identify useful items in different applications. However, existing cross-domain models typically require large number of overlap users, which can be difficult to obtain in some applications. In addition, they did not consider the duality structure of cross-domain recommendation tasks, thus failing to take into account bidirectional latent relations between users and items and achieve optimal recommendation performance. To address these issues, in this paper we propose a novel cross-domain recommendation model based on dual learning that transfers information between two related domains in an iterative manner until the learning process stabilizes. We develop a novel latent orthogonal mapping to extract user preferences over multiple domains while preserving relations between users across different latent spaces. Furthermore, we combine the dual learning method with the metric learning approach, which allows us to significantly reduce the required common user overlap across the two domains and leads to even better cross-domain recommendation performance. We test the proposed model on two large-scale industrial datasets and six domain pairs, demonstrating that it consistently and significantly outperforms all the state-of-the-art baselines. We also show that the proposed model works well with very few overlap users to obtain satisfying recommendation performance comparable to the state-of-the-art baselines that use many overlap users.
Noise-Resilient Automatic Interpretation of Holter ECG Recordings
Nov 17, 2020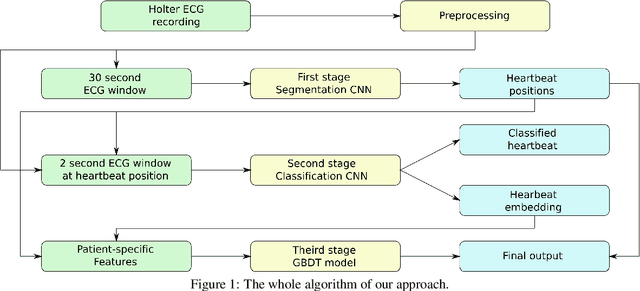
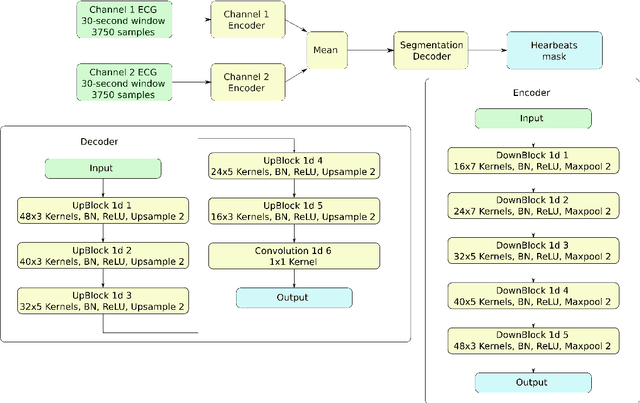
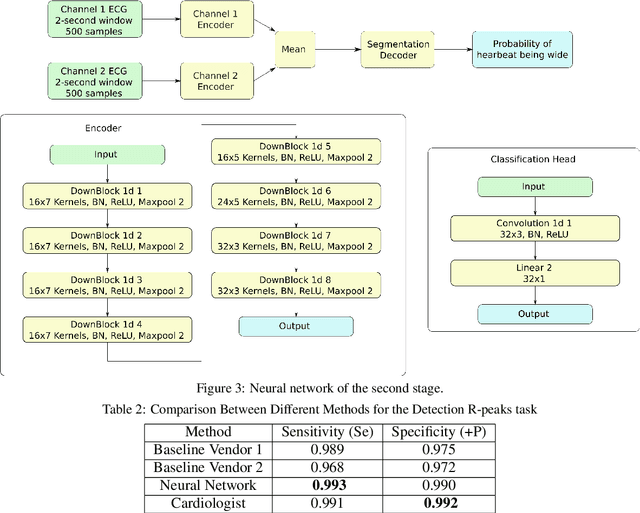
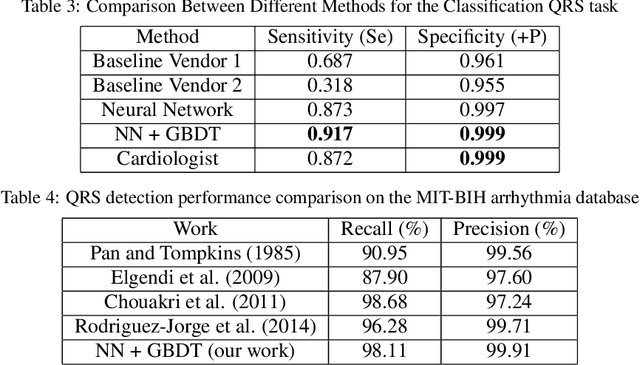
Holter monitoring, a long-term ECG recording (24-hours and more), contains a large amount of valuable diagnostic information about the patient. Its interpretation becomes a difficult and time-consuming task for the doctor who analyzes them because every heartbeat needs to be classified, thus requiring highly accurate methods for automatic interpretation. In this paper, we present a three-stage process for analysing Holter recordings with robustness to noisy signal. First stage is a segmentation neural network (NN) with encoderdecoder architecture which detects positions of heartbeats. Second stage is a classification NN which will classify heartbeats as wide or narrow. Third stage in gradient boosting decision trees (GBDT) on top of NN features that incorporates patient-wise features and further increases performance of our approach. As a part of this work we acquired 5095 Holter recordings of patients annotated by an experienced cardiologist. A committee of three cardiologists served as a ground truth annotators for the 291 examples in the test set. We show that the proposed method outperforms the selected baselines, including two commercial-grade software packages and some methods previously published in the literature.
Performance of Hyperbolic Geometry Models on Top-N Recommendation Tasks
Aug 15, 2020
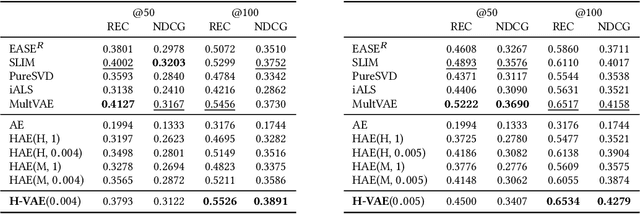
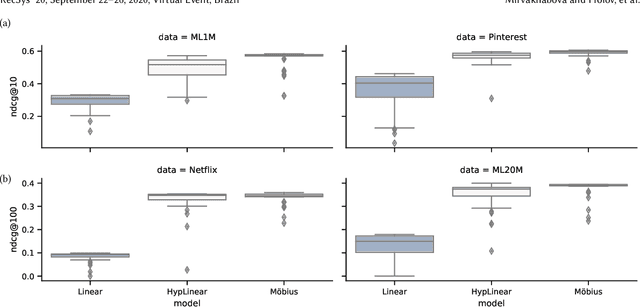
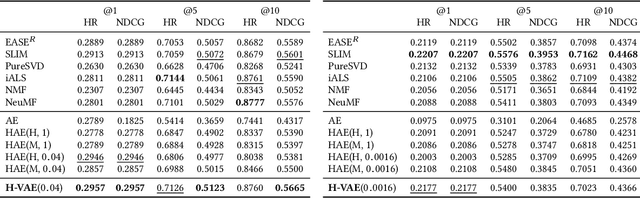
We introduce a simple autoencoder based on hyperbolic geometry for solving standard collaborative filtering problem. In contrast to many modern deep learning techniques, we build our solution using only a single hidden layer. Remarkably, even with such a minimalistic approach, we not only outperform the Euclidean counterpart but also achieve a competitive performance with respect to the current state-of-the-art. We additionally explore the effects of space curvature on the quality of hyperbolic models and propose an efficient data-driven method for estimating its optimal value.