 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Detection in LLMs via Topological Divergence on Attention Graphs
Apr 14, 2025Hallucination, i.e., generating factually incorrect content, remains a critical challenge for large language models (LLMs). We introduce TOHA, a TOpology-based HAllucination detector in the RAG setting, which leverages a topological divergence metric to quantify the structural properties of graphs induced by attention matrices. Examining the topological divergence between prompt and response subgraphs reveals consistent patterns: higher divergence values in specific attention heads correlate with hallucinated outputs, independent of the dataset. Extensive experiments, including evaluation on question answering and data-to-text tasks, show that our approach achieves state-of-the-art or competitive results on several benchmarks, two of which were annotated by us and are being publicly released to facilitate further research. Beyond its strong in-domain performance, TOHA maintains remarkable domain transferability across multiple open-source LLMs. Our findings suggest that analyzing the topological structure of attention matrices can serve as an efficient and robust indicator of factual reliability in LLMs.
LightAutoML: AutoML Solution for a Large Financial Services Ecosystem
Sep 03, 2021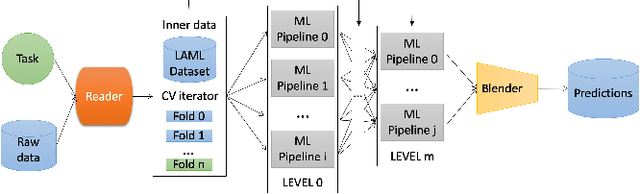


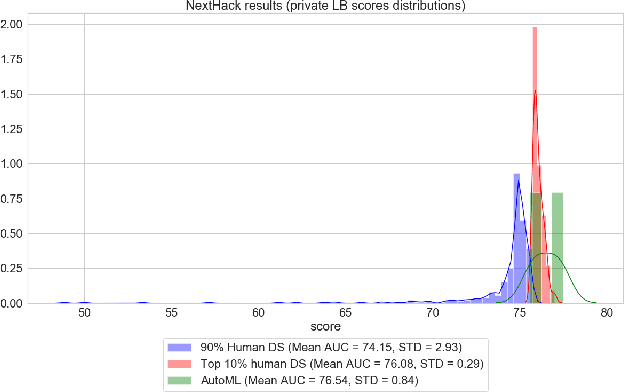
We present an AutoML system called LightAutoML developed for a large European financial services company and its ecosystem satisfying the set of idiosyncratic requirements that this ecosystem has for AutoML solutions. Our framework was piloted and deployed in numerous applications and performed at the level of the experienced data scientists while building high-quality ML models significantly faster than these data scientists. We also compare the performance of our system with various general-purpose open source AutoML solutions and show that it performs better for most of the ecosystem and OpenML problems. We also present the lessons that we learned while developing the AutoML system and moving it into production.
E.T.-RNN: Applying Deep Learning to Credit Loan Applications
Nov 06, 2019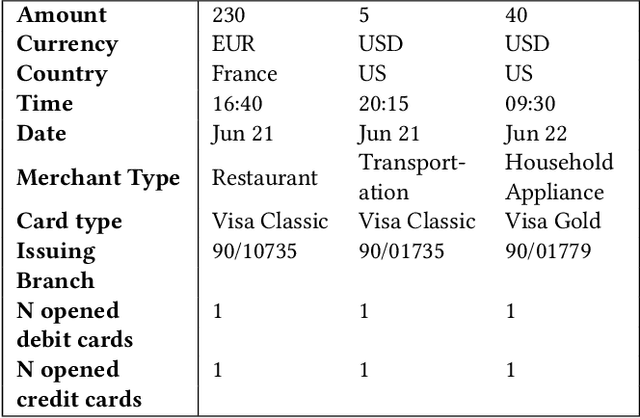
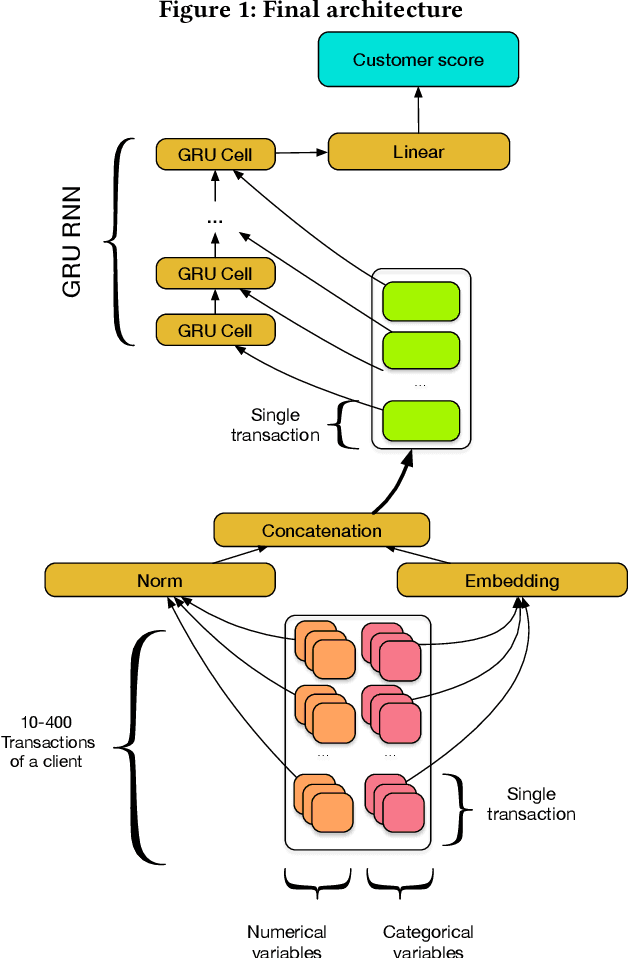
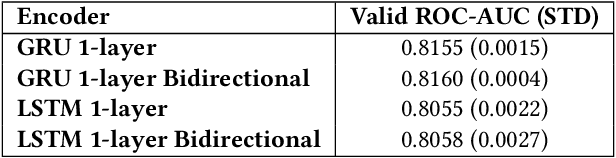
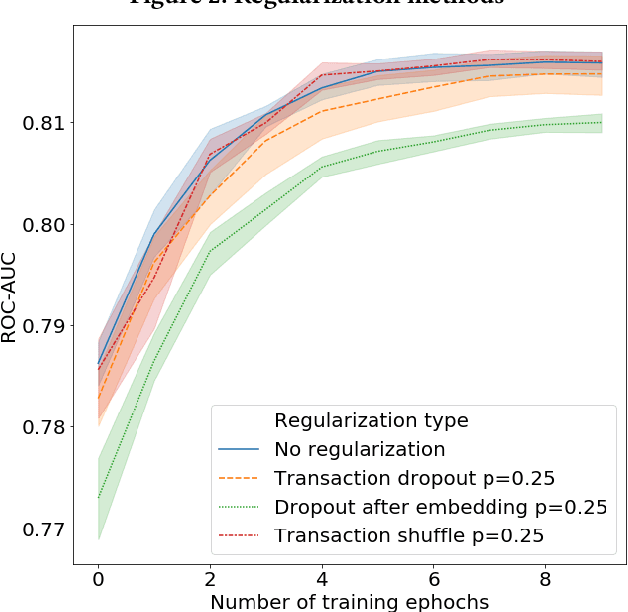
In this paper we present a novel approach to credit scoring of retail customers in the banking industry based on deep learning methods. We used RNNs on fine grained transnational data to compute credit scores for the loan applicants. We demonstrate that our approach significantly outperforms the baselines based on the customer data of a large European bank. We also conducted a pilot study on loan applicants of the bank, and the study produced significant financial gains for the organization. In addition, our method has several other advantages described in the paper that are very significant for the bank.