 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsururu: A Python-based Time Series Forecasting Strategies Library
Sep 19, 2025



While current time series research focuses on developing new models, crucial questions of selecting an optimal approach for training such models are underexplored. Tsururu, a Python library introduced in this paper, bridges SoTA research and industry by enabling flexible combinations of global and multivariate approaches and multi-step-ahead forecasting strategies. It also enables seamless integration with various forecasting models. Available at https://github.com/sb-ai-lab/tsururu .
Sparse Autoencoders for Sequential Recommendation Models: Interpretation and Flexible Control
Jul 16, 2025Many current state-of-the-art models for sequential recommendations are based on transformer architectures. Interpretation and explanation of such black box models is an important research question, as a better understanding of their internals can help understand, influence, and control their behavior, which is very important in a variety of real-world applications. Recently sparse autoencoders (SAE) have been shown to be a promising unsupervised approach for extracting interpretable features from language models. These autoencoders learn to reconstruct hidden states of the transformer's internal layers from sparse linear combinations of directions in their activation space. This paper is focused on the application of SAE to the sequential recommendation domain. We show that this approach can be successfully applied to the transformer trained on a sequential recommendation task: learned directions turn out to be more interpretable and monosemantic than the original hidden state dimensions. Moreover, we demonstrate that the features learned by SAE can be used to effectively and flexibly control the model's behavior, providing end-users with a straightforward method to adjust their recommendations to different custom scenarios and contexts.
Data-efficient Meta-models for Evaluation of Context-based Questions and Answers in LLMs
May 29, 2025



Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems are increasingly deployed in industry applications, yet their reliability remains hampered by challenges in detecting hallucinations. While supervised state-of-the-art (SOTA) methods that leverage LLM hidden states -- such as activation tracing and representation analysis -- show promise, their dependence on extensively annotated datasets limits scalability in real-world applications. This paper addresses the critical bottleneck of data annotation by investigating the feasibility of reducing training data requirements for two SOTA hallucination detection frameworks: Lookback Lens, which analyzes attention head dynamics, and probing-based approaches, which decode internal model representations. We propose a methodology combining efficient classification algorithms with dimensionality reduction techniques to minimize sample size demands while maintaining competitive performance. Evaluations on standardized question-answering RAG benchmarks show that our approach achieves performance comparable to strong proprietary LLM-based baselines with only 250 training samples. These results highlight the potential of lightweight, data-efficient paradigms for industrial deployment, particularly in annotation-constrained scenarios.
Hallucination Detection in LLMs via Topological Divergence on Attention Graphs
Apr 14, 2025Hallucination, i.e., generating factually incorrect content, remains a critical challenge for large language models (LLMs). We introduce TOHA, a TOpology-based HAllucination detector in the RAG setting, which leverages a topological divergence metric to quantify the structural properties of graphs induced by attention matrices. Examining the topological divergence between prompt and response subgraphs reveals consistent patterns: higher divergence values in specific attention heads correlate with hallucinated outputs, independent of the dataset. Extensive experiments, including evaluation on question answering and data-to-text tasks, show that our approach achieves state-of-the-art or competitive results on several benchmarks, two of which were annotated by us and are being publicly released to facilitate further research. Beyond its strong in-domain performance, TOHA maintains remarkable domain transferability across multiple open-source LLMs. Our findings suggest that analyzing the topological structure of attention matrices can serve as an efficient and robust indicator of factual reliability in LLMs.
Towards Foundation Time Series Model: To Synthesize Or Not To Synthesize?
Mar 04, 2024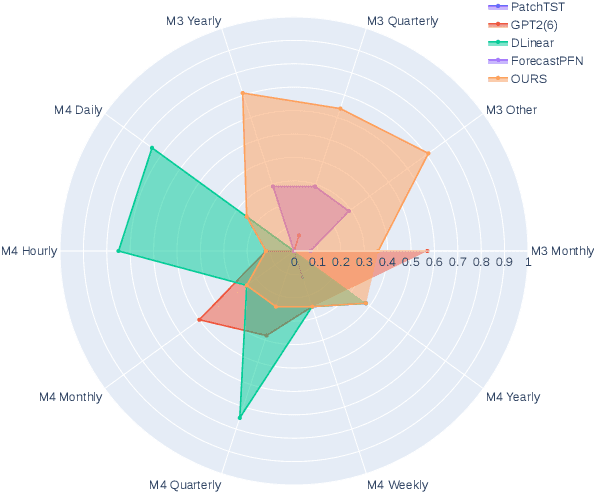

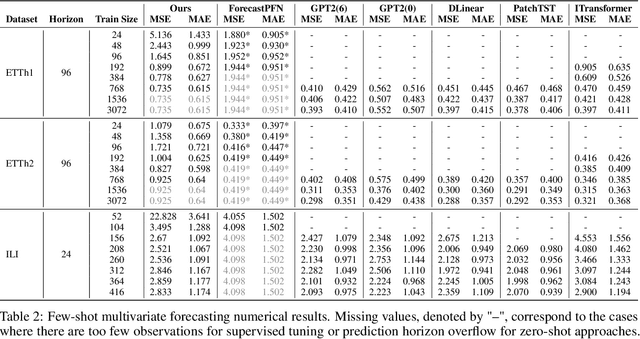
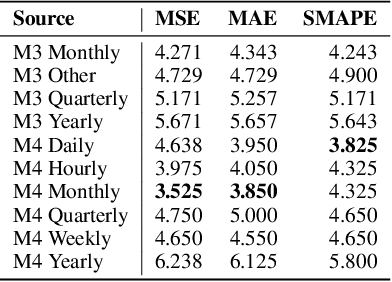
The industry is rich in cases when we are required to make forecasting for large amounts of time series at once. However, we might be in a situation where we can not afford to train a separate model for each of them. Such issue in time series modeling remains without due attention. The remedy for this setting is the establishment of a foundation model. Such a model is expected to work in zero-shot and few-shot regimes. However, what should we take as a training dataset for such kind of model? Witnessing the benefits from the enrichment of NLP datasets with artificially-generated data, we might want to adopt their experience for time series. In contrast to natural language, the process of generation of synthetic time series data is even more favorable because it provides full control of series patterns, time horizons, and number of samples. In this work, we consider the essential question if it is advantageous to train a foundation model on synthetic data or it is better to utilize only a limited number of real-life examples. Our experiments are conducted only for regular time series and speak in favor of leveraging solely the real time series. Moreover, the choice of the proper source dataset strongly influences the performance during inference. When provided access even to a limited quantity of short time series data, employing it within a supervised framework yields more favorable results than training on a larger volume of synthetic data. The code for our experiments is publicly available on Github \url{https://github.com/sb-ai-lab/synthesize_or_not}.
LightAutoML: AutoML Solution for a Large Financial Services Ecosystem
Sep 03, 2021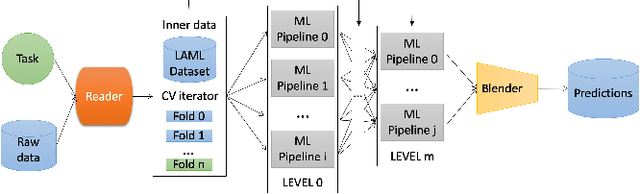


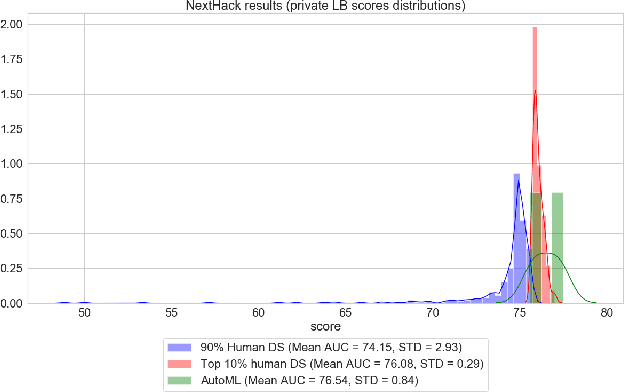
We present an AutoML system called LightAutoML developed for a large European financial services company and its ecosystem satisfying the set of idiosyncratic requirements that this ecosystem has for AutoML solutions. Our framework was piloted and deployed in numerous applications and performed at the level of the experienced data scientists while building high-quality ML models significantly faster than these data scientists. We also compare the performance of our system with various general-purpose open source AutoML solutions and show that it performs better for most of the ecosystem and OpenML problems. We also present the lessons that we learned while developing the AutoML system and moving it into production.