 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsururu: A Python-based Time Series Forecasting Strategies Library
Sep 19, 2025



While current time series research focuses on developing new models, crucial questions of selecting an optimal approach for training such models are underexplored. Tsururu, a Python library introduced in this paper, bridges SoTA research and industry by enabling flexible combinations of global and multivariate approaches and multi-step-ahead forecasting strategies. It also enables seamless integration with various forecasting models. Available at https://github.com/sb-ai-lab/tsururu .
Towards Foundation Time Series Model: To Synthesize Or Not To Synthesize?
Mar 04, 2024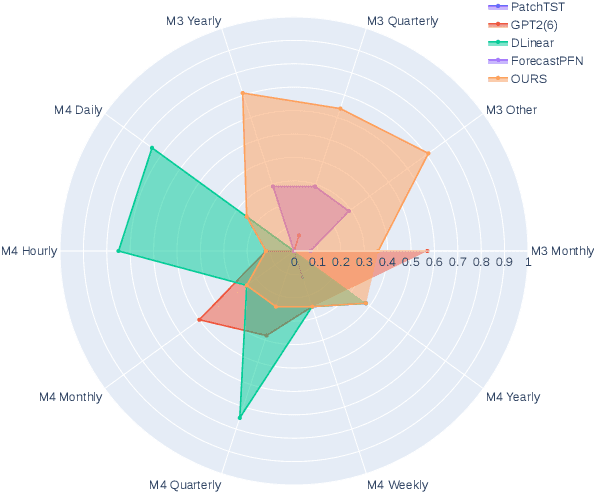

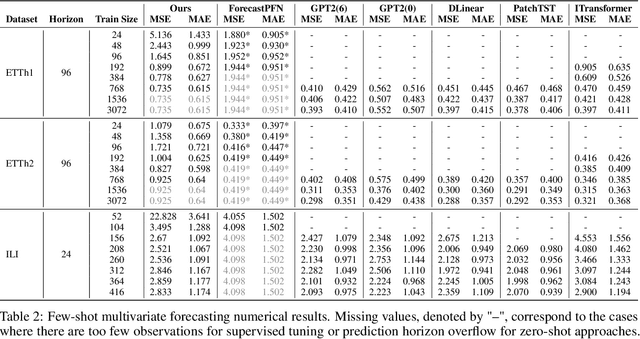
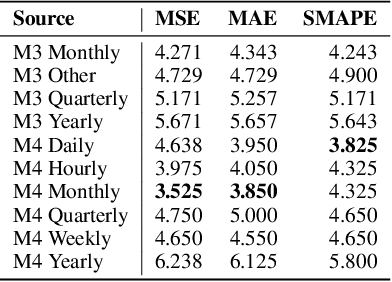
The industry is rich in cases when we are required to make forecasting for large amounts of time series at once. However, we might be in a situation where we can not afford to train a separate model for each of them. Such issue in time series modeling remains without due attention. The remedy for this setting is the establishment of a foundation model. Such a model is expected to work in zero-shot and few-shot regimes. However, what should we take as a training dataset for such kind of model? Witnessing the benefits from the enrichment of NLP datasets with artificially-generated data, we might want to adopt their experience for time series. In contrast to natural language, the process of generation of synthetic time series data is even more favorable because it provides full control of series patterns, time horizons, and number of samples. In this work, we consider the essential question if it is advantageous to train a foundation model on synthetic data or it is better to utilize only a limited number of real-life examples. Our experiments are conducted only for regular time series and speak in favor of leveraging solely the real time series. Moreover, the choice of the proper source dataset strongly influences the performance during inference. When provided access even to a limited quantity of short time series data, employing it within a supervised framework yields more favorable results than training on a larger volume of synthetic data. The code for our experiments is publicly available on Github \url{https://github.com/sb-ai-lab/synthesize_or_not}.
Sparse and Transferable Universal Singular Vectors Attack
Jan 25, 2024The research in the field of adversarial attacks and models' vulnerability is one of the fundamental directions in modern machine learning. Recent studies reveal the vulnerability phenomenon, and understanding the mechanisms behind this is essential for improving neural network characteristics and interpretability. In this paper, we propose a novel sparse universal white-box adversarial attack. Our approach is based on truncated power iteration providing sparsity to $(p,q)$-singular vectors of the hidden layers of Jacobian matrices. Using the ImageNet benchmark validation subset, we analyze the proposed method in various settings, achieving results comparable to dense baselines with more than a 50% fooling rate while damaging only 5% of pixels and utilizing 256 samples for perturbation fitting. We also show that our algorithm admits higher attack magnitude without affecting the human ability to solve the task. Furthermore, we investigate that the constructed perturbations are highly transferable among different models without significantly decreasing the fooling rate. Our findings demonstrate the vulnerability of state-of-the-art models to sparse attacks and highlight the importance of developing robust machine learning systems.