 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding-Aware Feature Discovery: Bridging Latent Representations and Interpretable Features in Event Sequences
Mar 16, 2026Industrial financial systems operate on temporal event sequences such as transactions, user actions, and system logs. While recent research emphasizes representation learning and large language models, production systems continue to rely heavily on handcrafted statistical features due to their interpretability, robustness under limited supervision, and strict latency constraints. This creates a persistent disconnect between learned embeddings and feature-based pipelines. We introduce Embedding-Aware Feature Discovery (EAFD), a unified framework that bridges this gap by coupling pretrained event-sequence embeddings with a self-reflective LLM-driven feature generation agent. EAFD iteratively discovers, evaluates, and refines features directly from raw event sequences using two complementary criteria: \emph{alignment}, which explains information already encoded in embeddings, and \emph{complementarity}, which identifies predictive signals missing from them. Across both open-source and industrial transaction benchmarks, EAFD consistently outperforms embedding-only and feature-based baselines, achieving relative gains of up to $+5.8\%$ over state-of-the-art pretrained embeddings, resulting in new state-of-the-art performance across event-sequence datasets.
PINE: Pipeline for Important Node Exploration in Attributed Networks
Dec 08, 2025
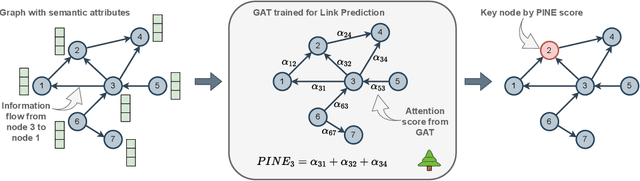
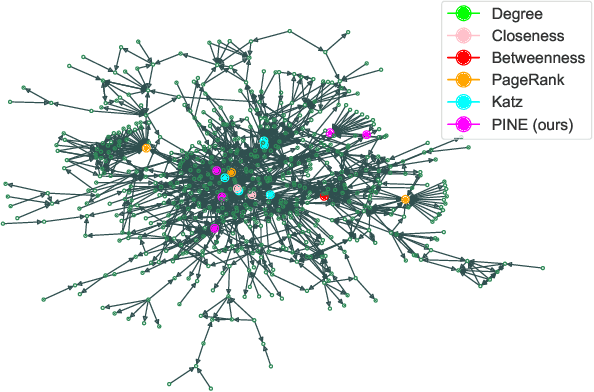
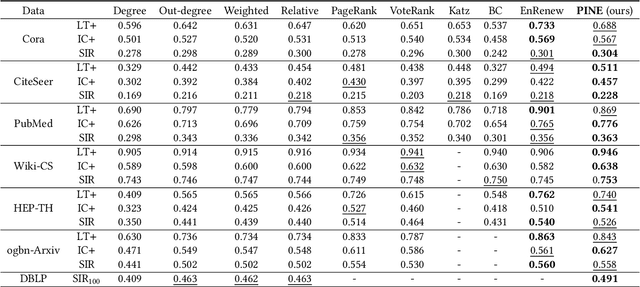
A graph with semantically attributed nodes are a common data structure in a wide range of domains. It could be interlinked web data or citation networks of scientific publications. The essential problem for such a data type is to determine nodes that carry greater importance than all the others, a task that markedly enhances system monitoring and management. Traditional methods to identify important nodes in networks introduce centrality measures, such as node degree or more complex PageRank. However, they consider only the network structure, neglecting the rich node attributes. Recent methods adopt neural networks capable of handling node features, but they require supervision. This work addresses the identified gap--the absence of approaches that are both unsupervised and attribute-aware--by introducing a Pipeline for Important Node Exploration (PINE). At the core of the proposed framework is an attention-based graph model that incorporates node semantic features in the learning process of identifying the structural graph properties. The PINE's node importance scores leverage the obtained attention distribution. We demonstrate the superior performance of the proposed PINE method on various homogeneous and heterogeneous attributed networks. As an industry-implemented system, PINE tackles the real-world challenge of unsupervised identification of key entities within large-scale enterprise graphs.
Towards Foundation Time Series Model: To Synthesize Or Not To Synthesize?
Mar 04, 2024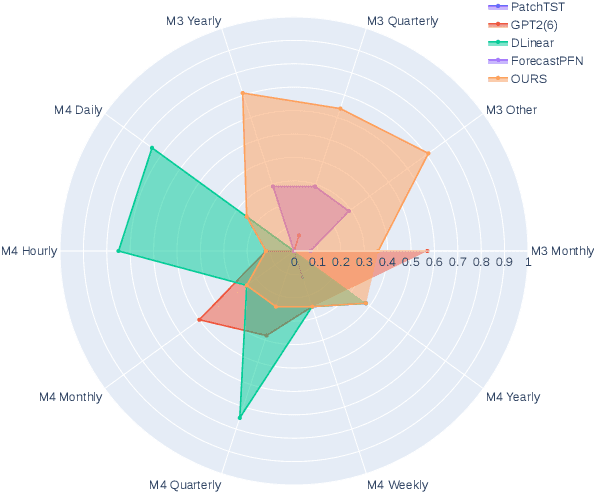

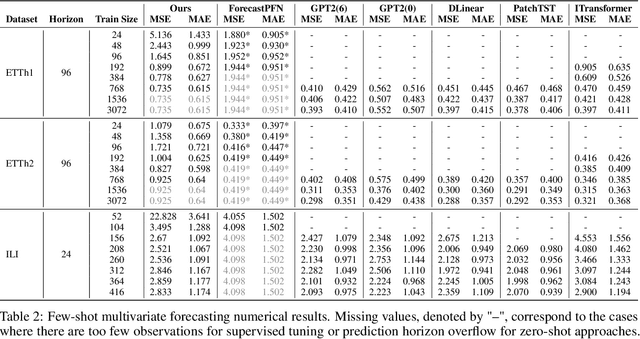
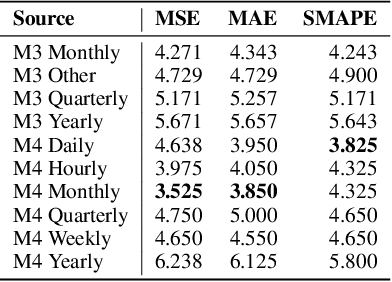
The industry is rich in cases when we are required to make forecasting for large amounts of time series at once. However, we might be in a situation where we can not afford to train a separate model for each of them. Such issue in time series modeling remains without due attention. The remedy for this setting is the establishment of a foundation model. Such a model is expected to work in zero-shot and few-shot regimes. However, what should we take as a training dataset for such kind of model? Witnessing the benefits from the enrichment of NLP datasets with artificially-generated data, we might want to adopt their experience for time series. In contrast to natural language, the process of generation of synthetic time series data is even more favorable because it provides full control of series patterns, time horizons, and number of samples. In this work, we consider the essential question if it is advantageous to train a foundation model on synthetic data or it is better to utilize only a limited number of real-life examples. Our experiments are conducted only for regular time series and speak in favor of leveraging solely the real time series. Moreover, the choice of the proper source dataset strongly influences the performance during inference. When provided access even to a limited quantity of short time series data, employing it within a supervised framework yields more favorable results than training on a larger volume of synthetic data. The code for our experiments is publicly available on Github \url{https://github.com/sb-ai-lab/synthesize_or_not}.
Hiding Backdoors within Event Sequence Data via Poisoning Attacks
Aug 20, 2023The financial industry relies on deep learning models for making important decisions. This adoption brings new danger, as deep black-box models are known to be vulnerable to adversarial attacks. In computer vision, one can shape the output during inference by performing an adversarial attack called poisoning via introducing a backdoor into the model during training. For sequences of financial transactions of a customer, insertion of a backdoor is harder to perform, as models operate over a more complex discrete space of sequences, and systematic checks for insecurities occur. We provide a method to introduce concealed backdoors, creating vulnerabilities without altering their functionality for uncontaminated data. To achieve this, we replace a clean model with a poisoned one that is aware of the availability of a backdoor and utilize this knowledge. Our most difficult for uncovering attacks include either additional supervised detection step of poisoned data activated during the test or well-hidden model weight modifications. The experimental study provides insights into how these effects vary across different datasets, architectures, and model components. Alternative methods and baselines, such as distillation-type regularization, are also explored but found to be less efficient. Conducted on three open transaction datasets and architectures, including LSTM, CNN, and Transformer, our findings not only illuminate the vulnerabilities in contemporary models but also can drive the construction of more robust systems.
The Battle of Information Representations: Comparing Sentiment and Semantic Features for Forecasting Market Trends
Mar 24, 2023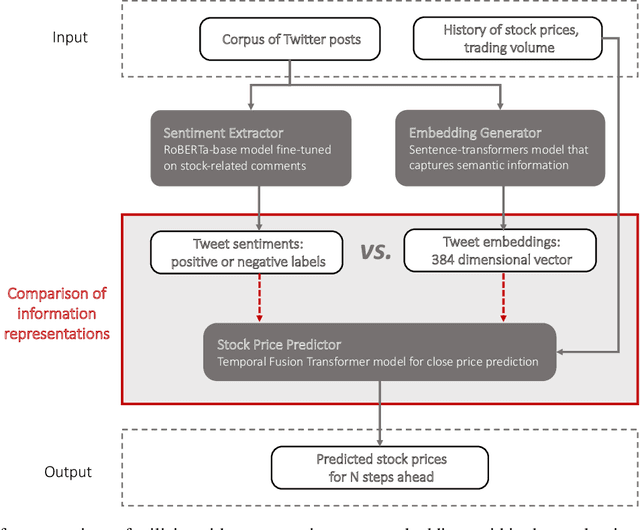
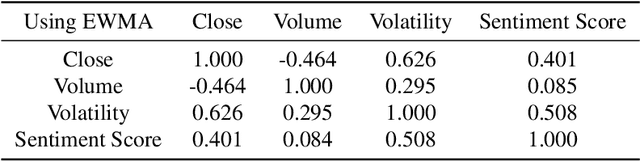


The study of the stock market with the attraction of machine learning approaches is a major direction for revealing hidden market regularities. This knowledge contributes to a profound understanding of financial market dynamics and getting behavioural insights, which could hardly be discovered with traditional analytical methods. Stock prices are inherently interrelated with world events and social perception. Thus, in constructing the model for stock price prediction, the critical stage is to incorporate such information on the outside world, reflected through news and social media posts. To accommodate this, researchers leverage the implicit or explicit knowledge representations: (1) sentiments extracted from the texts or (2) raw text embeddings. However, there is too little research attention to the direct comparison of these approaches in terms of the influence on the predictive power of financial models. In this paper, we aim to close this gap and figure out whether the semantic features in the form of contextual embeddings are more valuable than sentiment attributes for forecasting market trends. We consider the corpus of Twitter posts related to the largest companies by capitalization from NASDAQ and their close prices. To start, we demonstrate the connection of tweet sentiments with the volatility of companies' stock prices. Convinced of the existing relationship, we train Temporal Fusion Transformer models for price prediction supplemented with either tweet sentiments or tweet embeddings. Our results show that in the substantially prevailing number of cases, the use of sentiment features leads to higher metrics. Noteworthy, the conclusions are justifiable within the considered scenario involving Twitter posts and stocks of the biggest tech companies.
Label Attention Network for sequential multi-label classification
Mar 01, 2023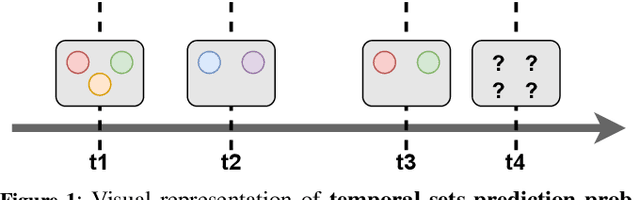
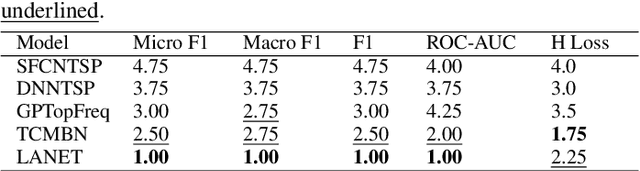
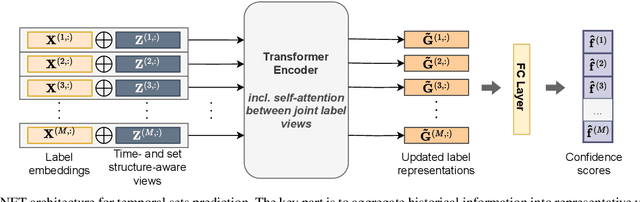
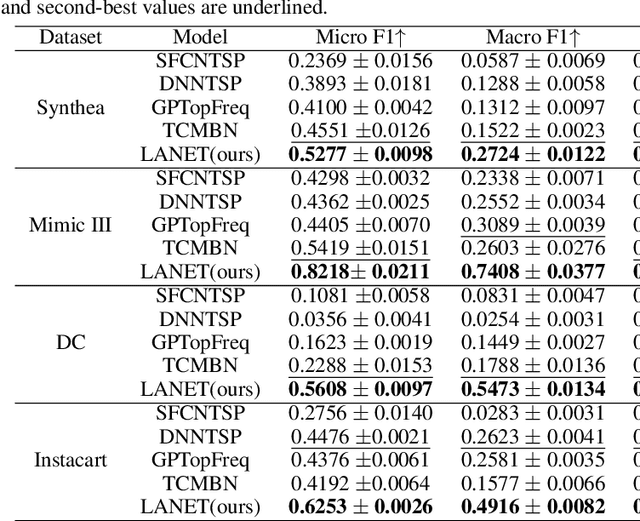
Multi-label classification is a natural problem statement for sequential data. We might be interested in the items of the next order by a customer, or types of financial transactions that will occur tomorrow. Most modern approaches focus on transformer architecture for multi-label classification, introducing self-attention for the elements of a sequence with each element being a multi-label vector and supplementary information. However, in this way we loose local information related to interconnections between particular labels. We propose instead to use a self-attention mechanism over labels preceding the predicted step. Conducted experiments suggest that such architecture improves the model performance and provides meaningful attention between labels. The metric such as micro-AUC of our label attention network is $0.9847$ compared to $0.7390$ for vanilla transformers benchmark.
Relationships between patenting trends and research activity for green energy technologies
Oct 18, 2022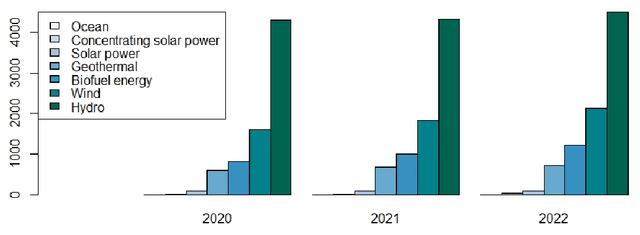
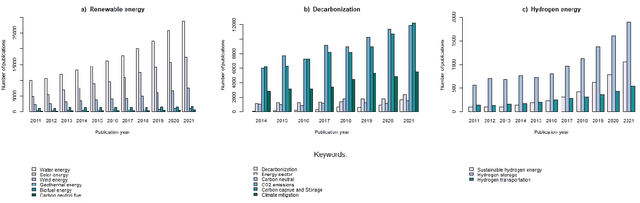
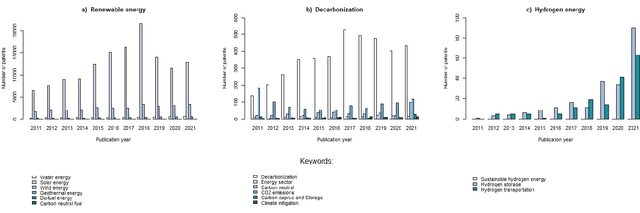
Green technology is viewed as a means of creating a sustainable society and a catalyst for sustainable development by the global community. It is responsible for both the potential reduction of production waste and the reduction of carbon footprint and CO2 emissions. However, alongside with the growing popularity of green technologies, there is an emerging skepticism about their contribution to solving environmental challenges. This article focuses on three areas of eco-innovation in green technology: renewable energy, hydrogen power, and decarbonization. Our main goal is to analyze the relationship between publication activity and the number of patented research results, thus shedding light on the real-world applicability of scientific outcomes. We used several bibliometric methods for analyzing global publication and patent activity, applied to the Scopus citation database and the European Patent Office's patent database. Our results show that the advancement of research in all three areas of eco-innovation does not automatically lead to the increase in the number of patents. We offer possible reasons for such dependency based on the observations of the worldwide tendencies in green innovation sphere.
New drugs and stock market: how to predict pharma market reaction to clinical trial announcements
Aug 16, 2022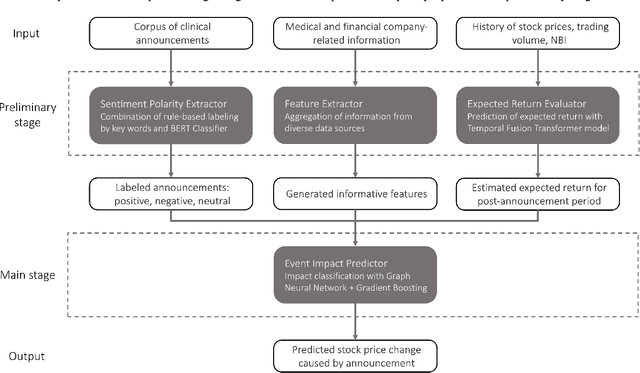


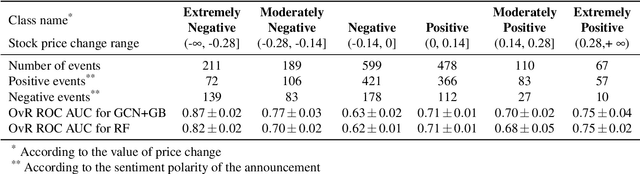
Pharmaceutical companies operate in a strictly regulated and highly risky environment in which a single slip can lead to serious financial implications. Accordingly, the announcements of clinical trial results tend to determine the future course of events, hence being closely monitored by the public. In this work, we provide statistical evidence for the result promulgation influence on the public pharma market value. Whereas most works focus on retrospective impact analysis, the present research aims to predict the numerical values of announcement-induced changes in stock prices. For this purpose, we develop a pipeline that includes a BERT-based model for extracting sentiment polarity of announcements, a Temporal Fusion Transformer for forecasting the expected return, a graph convolution network for capturing event relationships, and gradient boosting for predicting the price change. The challenge of the problem lies in inherently different patterns of responses to positive and negative announcements, reflected in a stronger and more pronounced reaction to the negative news. Moreover, such phenomenon as the drop in stocks after the positive announcements affirms the counterintuitiveness of the price behavior. Importantly, we discover two crucial factors that should be considered while working within a predictive framework. The first factor is the drug portfolio size of the company, indicating the greater susceptibility to an announcement in the case of small drug diversification. The second one is the network effect of the events related to the same company or nosology. All findings and insights are gained on the basis of one of the biggest FDA (the Food and Drug Administration) announcement datasets, consisting of 5436 clinical trial announcements from 681 companies over the last five years.
Adversarial Attacks on Deep Models for Financial Transaction Records
Jun 15, 2021
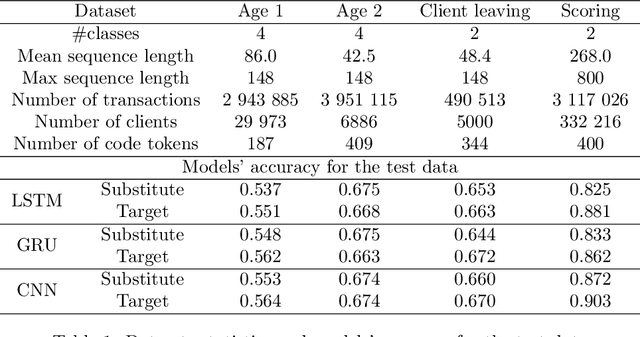
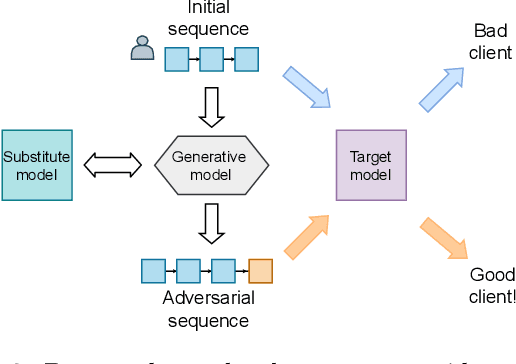
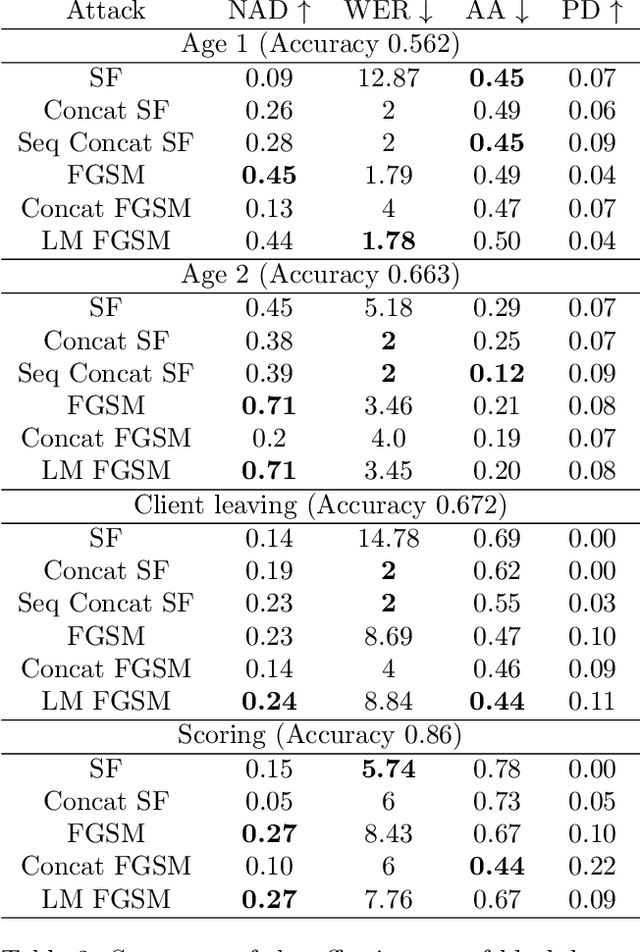
Machine learning models using transaction records as inputs are popular among financial institutions. The most efficient models use deep-learning architectures similar to those in the NLP community, posing a challenge due to their tremendous number of parameters and limited robustness. In particular, deep-learning models are vulnerable to adversarial attacks: a little change in the input harms the model's output. In this work, we examine adversarial attacks on transaction records data and defences from these attacks. The transaction records data have a different structure than the canonical NLP or time series data, as neighbouring records are less connected than words in sentences, and each record consists of both discrete merchant code and continuous transaction amount. We consider a black-box attack scenario, where the attack doesn't know the true decision model, and pay special attention to adding transaction tokens to the end of a sequence. These limitations provide more realistic scenario, previously unexplored in NLP world. The proposed adversarial attacks and the respective defences demonstrate remarkable performance using relevant datasets from the financial industry. Our results show that a couple of generated transactions are sufficient to fool a deep-learning model. Further, we improve model robustness via adversarial training or separate adversarial examples detection. This work shows that embedding protection from adversarial attacks improves model robustness, allowing a wider adoption of deep models for transaction records in banking and finance.