 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINE: Pipeline for Important Node Exploration in Attributed Networks
Dec 08, 2025
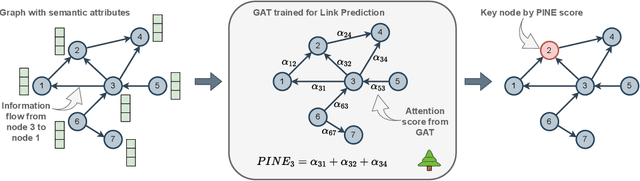
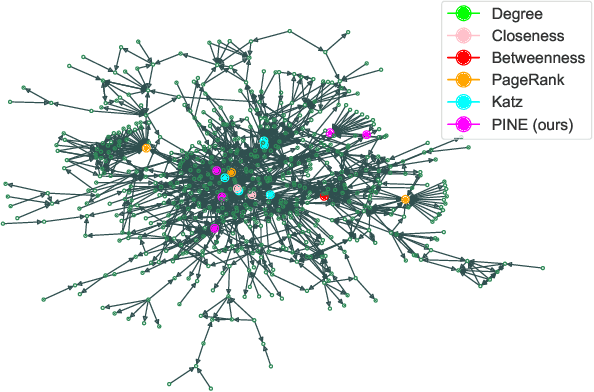
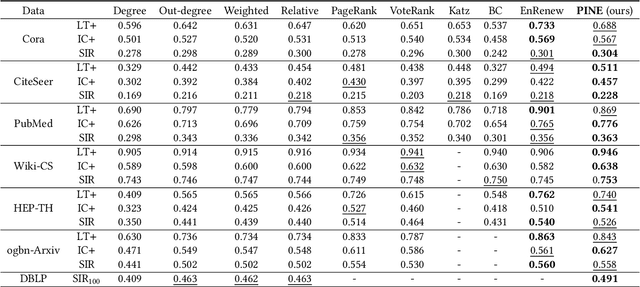
A graph with semantically attributed nodes are a common data structure in a wide range of domains. It could be interlinked web data or citation networks of scientific publications. The essential problem for such a data type is to determine nodes that carry greater importance than all the others, a task that markedly enhances system monitoring and management. Traditional methods to identify important nodes in networks introduce centrality measures, such as node degree or more complex PageRank. However, they consider only the network structure, neglecting the rich node attributes. Recent methods adopt neural networks capable of handling node features, but they require supervision. This work addresses the identified gap--the absence of approaches that are both unsupervised and attribute-aware--by introducing a Pipeline for Important Node Exploration (PINE). At the core of the proposed framework is an attention-based graph model that incorporates node semantic features in the learning process of identifying the structural graph properties. The PINE's node importance scores leverage the obtained attention distribution. We demonstrate the superior performance of the proposed PINE method on various homogeneous and heterogeneous attributed networks. As an industry-implemented system, PINE tackles the real-world challenge of unsupervised identification of key entities within large-scale enterprise graphs.
Unleashing the power of novel conditional generative approaches for new materials discovery
Nov 05, 2024
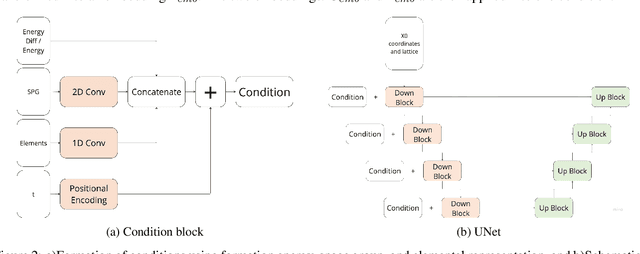

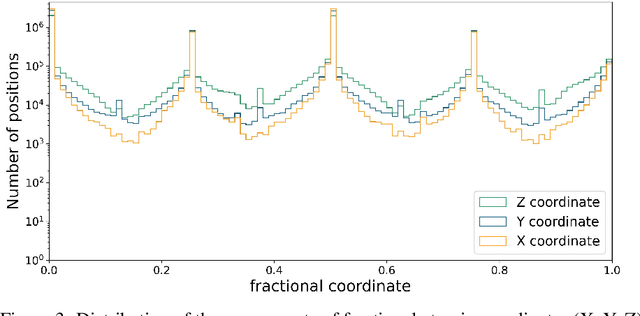
For a very long time, computational approaches to the design of new materials have relied on an iterative process of finding a candidate material and modeling its properties. AI has played a crucial role in this regard, helping to accelerate the discovery and optimization of crystal properties and structures through advanced computational methodologies and data-driven approaches. To address the problem of new materials design and fasten the process of new materials search, we have applied latest generative approaches to the problem of crystal structure design, trying to solve the inverse problem: by given properties generate a structure that satisfies them without utilizing supercomputer powers. In our work we propose two approaches: 1) conditional structure modification: optimization of the stability of an arbitrary atomic configuration, using the energy difference between the most energetically favorable structure and all its less stable polymorphs and 2) conditional structure generation. We used a representation for materials that includes the following information: lattice, atom coordinates, atom types, chemical features, space group and formation energy of the structure. The loss function was optimized to take into account the periodic boundary conditions of crystal structures. We have applied Diffusion models approach, Flow matching, usual Autoencoder (AE) and compared the results of the models and approaches. As a metric for the study, physical PyMatGen matcher was employed: we compare target structure with generated one using default tolerances. So far, our modifier and generator produce structures with needed properties with accuracy 41% and 82% respectively. To prove the offered methodology efficiency, inference have been carried out, resulting in several potentially new structures with formation energy below the AFLOW-derived convex hulls.
The Battle of Information Representations: Comparing Sentiment and Semantic Features for Forecasting Market Trends
Mar 24, 2023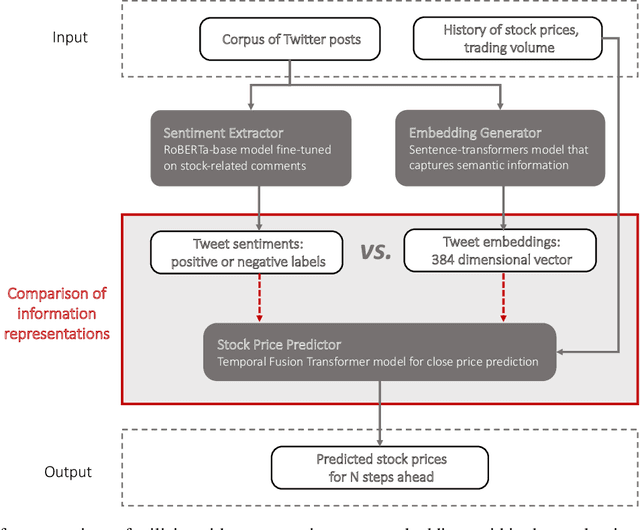
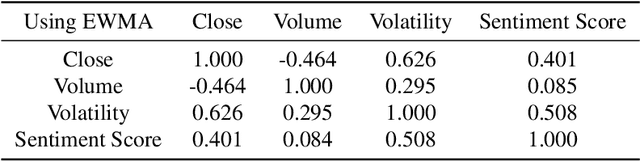


The study of the stock market with the attraction of machine learning approaches is a major direction for revealing hidden market regularities. This knowledge contributes to a profound understanding of financial market dynamics and getting behavioural insights, which could hardly be discovered with traditional analytical methods. Stock prices are inherently interrelated with world events and social perception. Thus, in constructing the model for stock price prediction, the critical stage is to incorporate such information on the outside world, reflected through news and social media posts. To accommodate this, researchers leverage the implicit or explicit knowledge representations: (1) sentiments extracted from the texts or (2) raw text embeddings. However, there is too little research attention to the direct comparison of these approaches in terms of the influence on the predictive power of financial models. In this paper, we aim to close this gap and figure out whether the semantic features in the form of contextual embeddings are more valuable than sentiment attributes for forecasting market trends. We consider the corpus of Twitter posts related to the largest companies by capitalization from NASDAQ and their close prices. To start, we demonstrate the connection of tweet sentiments with the volatility of companies' stock prices. Convinced of the existing relationship, we train Temporal Fusion Transformer models for price prediction supplemented with either tweet sentiments or tweet embeddings. Our results show that in the substantially prevailing number of cases, the use of sentiment features leads to higher metrics. Noteworthy, the conclusions are justifiable within the considered scenario involving Twitter posts and stocks of the biggest tech companies.
Machine learning-based detection of cardiovascular disease using ECG signals: performance vs. complexity
Mar 10, 2023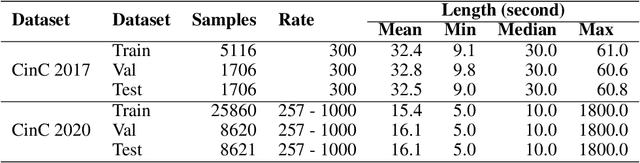
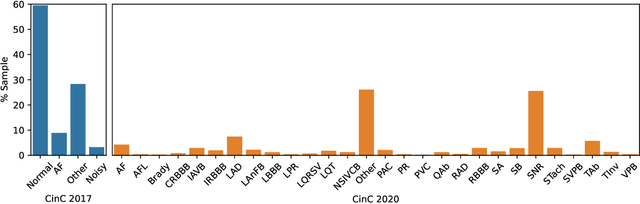
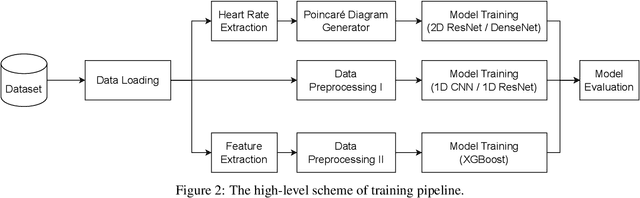

Cardiovascular disease remains a significant problem in modern society. Among non-invasive techniques, the electrocardiogram (ECG) is one of the most reliable methods for detecting abnormalities in cardiac activities. However, ECG interpretation requires expert knowledge and it is time-consuming. Developing a novel method to detect the disease early could prevent death and complication. The paper presents novel various approaches for classifying cardiac diseases from ECG recordings. The first approach suggests the Poincare representation of ECG signal and deep-learning-based image classifiers (ResNet50 and DenseNet121 were learned over Poincare diagrams), which showed decent performance in predicting AF (atrial fibrillation) but not other types of arrhythmia. XGBoost, a gradient-boosting model, showed an acceptable performance in long-term data but had a long inference time due to highly-consuming calculation within the pre-processing phase. Finally, the 1D convolutional model, specifically the 1D ResNet, showed the best results in both studied CinC 2017 and CinC 2020 datasets, reaching the F1 score of 85% and 71%, respectively, and that was superior to the first-ranking solution of each challenge. The paper also investigated efficiency metrics such as power consumption and equivalent CO2 emissions, with one-dimensional models like 1D CNN and 1D ResNet being the most energy efficient. Model interpretation analysis showed that the DenseNet detected AF using heart rate variability while the 1DResNet assessed AF pattern in raw ECG signals.
Relationships between patenting trends and research activity for green energy technologies
Oct 18, 2022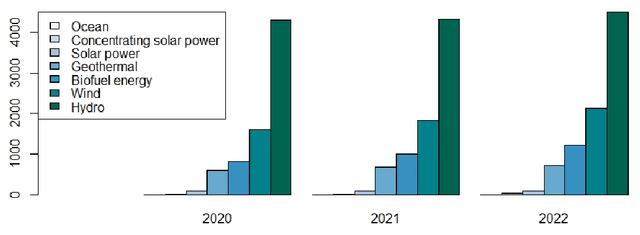
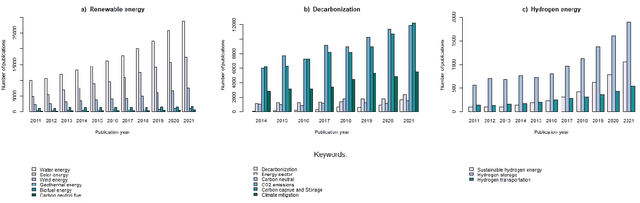
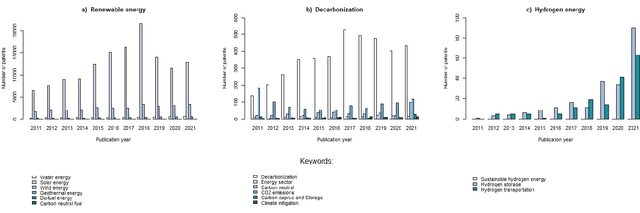
Green technology is viewed as a means of creating a sustainable society and a catalyst for sustainable development by the global community. It is responsible for both the potential reduction of production waste and the reduction of carbon footprint and CO2 emissions. However, alongside with the growing popularity of green technologies, there is an emerging skepticism about their contribution to solving environmental challenges. This article focuses on three areas of eco-innovation in green technology: renewable energy, hydrogen power, and decarbonization. Our main goal is to analyze the relationship between publication activity and the number of patented research results, thus shedding light on the real-world applicability of scientific outcomes. We used several bibliometric methods for analyzing global publication and patent activity, applied to the Scopus citation database and the European Patent Office's patent database. Our results show that the advancement of research in all three areas of eco-innovation does not automatically lead to the increase in the number of patents. We offer possible reasons for such dependency based on the observations of the worldwide tendencies in green innovation sphere.
New drugs and stock market: how to predict pharma market reaction to clinical trial announcements
Aug 16, 2022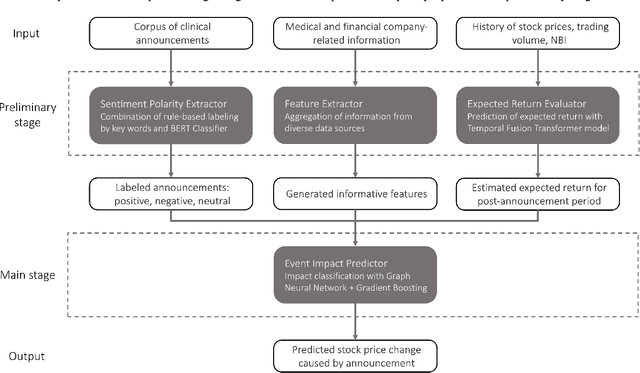


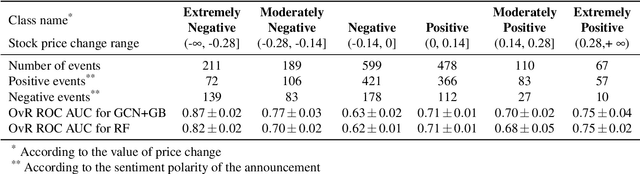
Pharmaceutical companies operate in a strictly regulated and highly risky environment in which a single slip can lead to serious financial implications. Accordingly, the announcements of clinical trial results tend to determine the future course of events, hence being closely monitored by the public. In this work, we provide statistical evidence for the result promulgation influence on the public pharma market value. Whereas most works focus on retrospective impact analysis, the present research aims to predict the numerical values of announcement-induced changes in stock prices. For this purpose, we develop a pipeline that includes a BERT-based model for extracting sentiment polarity of announcements, a Temporal Fusion Transformer for forecasting the expected return, a graph convolution network for capturing event relationships, and gradient boosting for predicting the price change. The challenge of the problem lies in inherently different patterns of responses to positive and negative announcements, reflected in a stronger and more pronounced reaction to the negative news. Moreover, such phenomenon as the drop in stocks after the positive announcements affirms the counterintuitiveness of the price behavior. Importantly, we discover two crucial factors that should be considered while working within a predictive framework. The first factor is the drug portfolio size of the company, indicating the greater susceptibility to an announcement in the case of small drug diversification. The second one is the network effect of the events related to the same company or nosology. All findings and insights are gained on the basis of one of the biggest FDA (the Food and Drug Administration) announcement datasets, consisting of 5436 clinical trial announcements from 681 companies over the last five years.
Anomaly segmentation model for defects detection in electroluminescence images of heterojunction solar cells
Aug 11, 2022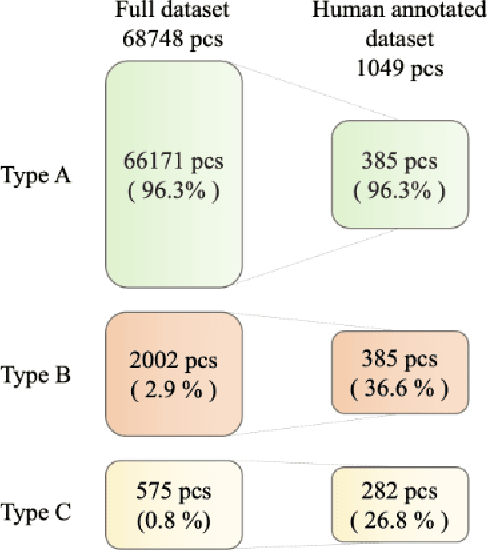
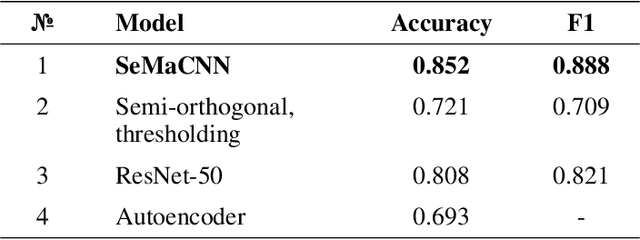

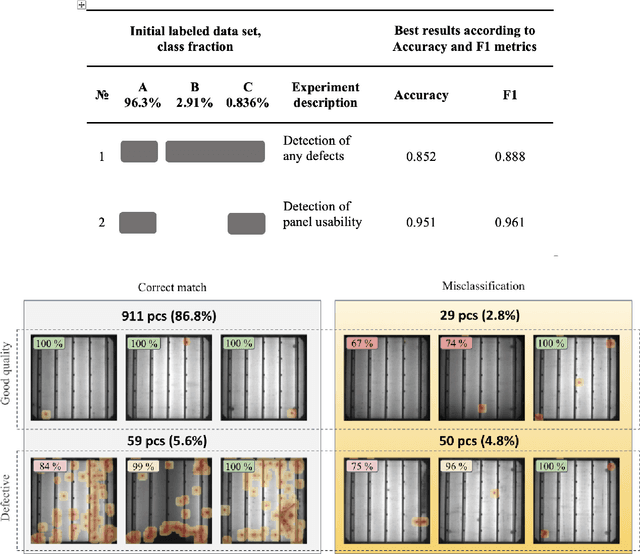
Efficient defect detection in solar cell manufacturing is crucial for stable green energy technology manufacturing. This paper presents a deep-learning-based automatic detection model SeMaCNN for classification and semantic segmentation of electroluminescent images for solar cell quality evaluation and anomalies detection. The core of the model is an anomaly detection algorithm based on Mahalanobis distance that can be trained in a semi-supervised manner on imbalanced data with small number of digital electroluminescence images with relevant defects. This is particularly valuable for prompt model integration into the industrial landscape. The model has been trained with the on-plant collected dataset consisting of 68 748 electroluminescent images of heterojunction solar cells with a busbar grid. Our model achieves the accuracy of 92.5%, F1 score 95.8%, recall 94.8%, and precision 96.9% within the validation subset consisting of 1049 manually annotated images. The model was also tested on the open ELPV dataset and demonstrates stable performance with accuracy 94.6% and F1 score 91.1%. The SeMaCNN model demonstrates a good balance between its performance and computational costs, which make it applicable for integrating into quality control systems of solar cell manufacturing.
Eco2AI: carbon emissions tracking of machine learning models as the first step towards sustainable AI
Aug 03, 2022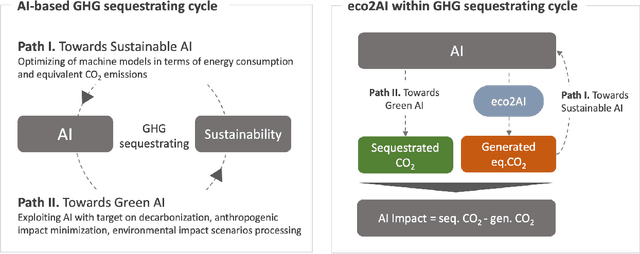
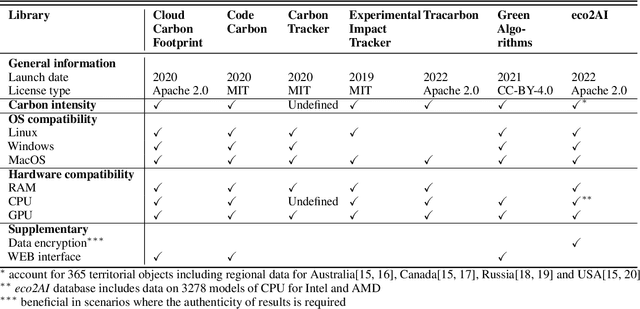


The size and complexity of deep neural networks continue to grow exponentially, significantly increasing energy consumption for training and inference by these models. We introduce an open-source package eco2AI to help data scientists and researchers to track energy consumption and equivalent CO2 emissions of their models in a straightforward way. In eco2AI we put emphasis on accuracy of energy consumption tracking and correct regional CO2 emissions accounting. We encourage research community to search for new optimal Artificial Intelligence (AI) architectures with a lower computational cost. The motivation also comes from the concept of AI-based green house gases sequestrating cycle with both Sustainable AI and Green AI pathways.