 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Guided Discovery of Novel Ionic Liquid Solvents for Industrial CO2 Capture
Jan 02, 2026We present an AI-driven approach to discover compounds with optimal properties for CO2 capture from flue gas-refinery emissions' primary source. Focusing on ionic liquids (ILs) as alternatives to traditional amine-based solvents, we successfully identify new IL candidates with high working capacity, manageable viscosity, favorable regeneration energy, and viable synthetic routes. Our approach follows a five-stage pipeline. First, we generate IL candidates by pairing available cation and anion molecules, then predict temperature- and pressure-dependent CO2 solubility and viscosity using a GNN-based molecular property prediction model. Next, we convert solubility to working capacity and regeneration energy via Van't Hoff modeling, and then find the best set of candidates using Pareto optimization, before finally filtering those based on feasible synthesis routes. We identify 36 feasible candidates that could enable 5-10% OPEX savings and up to 10% CAPEX reductions through lower regeneration energy requirements and reduced corrosivity-offering a novel carbon-capture strategy for refineries moving forward.
TEDDY: A Family Of Foundation Models For Understanding Single Cell Biology
Mar 05, 2025Understanding the biological mechanism of disease is critical for medicine, and in particular drug discovery. AI-powered analysis of genome-scale biological data hold great potential in this regard. The increasing availability of single-cell RNA sequencing data has enabled the development of large foundation models for disease biology. However, existing foundation models either do not improve or only modestly improve over task-specific models in downstream applications. Here, we explored two avenues for improving the state-of-the-art. First, we scaled the pre-training dataset to 116 million cells, which is larger than those used by previous models. Second, we leveraged the availability of large-scale biological annotations as a form of supervision during pre-training. We trained the TEDDY family of models comprising six transformer-based state-of-the-art single-cell foundation models with 70 million, 160 million, and 400 million parameters. We vetted our models on two downstream evaluation tasks -- identifying the underlying disease state of held-out donors not seen during training and distinguishing healthy cells from diseased ones for disease conditions and donors not seen during training. Scaling experiments showed that performance improved predictably with both data volume and parameter count. Our models showed substantial improvement over existing work on the first task and more muted improvements on the second.
Graph-Based Retriever Captures the Long Tail of Biomedical Knowledge
Feb 19, 2024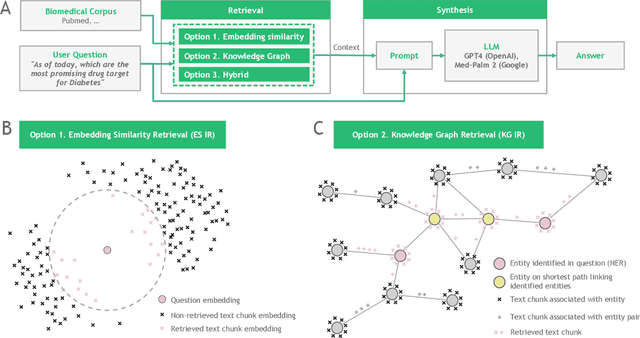
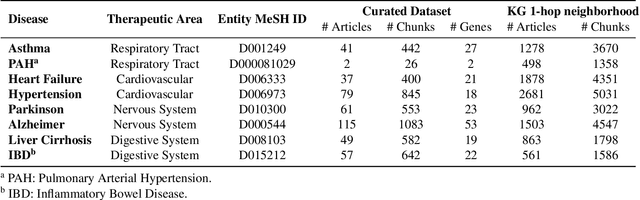
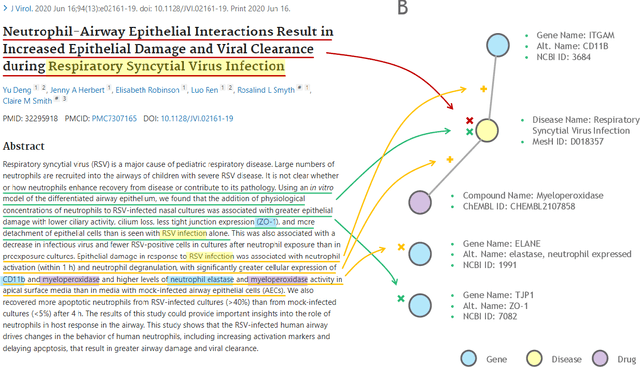
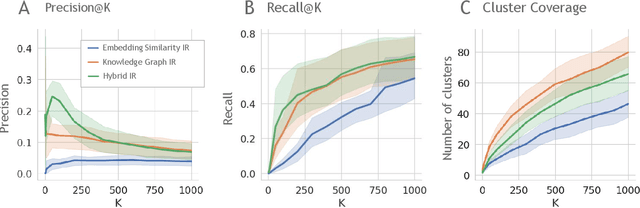
Large language models (LLMs) are transforming the way information is retrieved with vast amounts of knowledge being summarized and presented via natural language conversations. Yet, LLMs are prone to highlight the most frequently seen pieces of information from the training set and to neglect the rare ones. In the field of biomedical research, latest discoveries are key to academic and industrial actors and are obscured by the abundance of an ever-increasing literature corpus (the information overload problem). Surfacing new associations between biomedical entities, e.g., drugs, genes, diseases, with LLMs becomes a challenge of capturing the long-tail knowledge of the biomedical scientific production. To overcome this challenge, Retrieval Augmented Generation (RAG) has been proposed to alleviate some of the shortcomings of LLMs by augmenting the prompts with context retrieved from external datasets. RAG methods typically select the context via maximum similarity search over text embeddings. In this study, we show that RAG methods leave out a significant proportion of relevant information due to clusters of over-represented concepts in the biomedical literature. We introduce a novel information-retrieval method that leverages a knowledge graph to downsample these clusters and mitigate the information overload problem. Its retrieval performance is about twice better than embedding similarity alternatives on both precision and recall. Finally, we demonstrate that both embedding similarity and knowledge graph retrieval methods can be advantageously combined into a hybrid model that outperforms both, enabling potential improvements to biomedical question-answering models.
SensorSCAN: Self-Supervised Learning and Deep Clustering for Fault Diagnosis in Chemical Processes
Aug 17, 2022
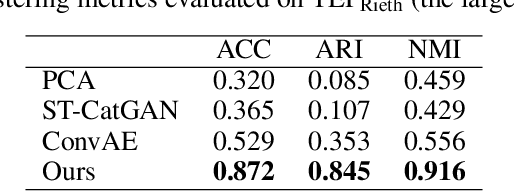
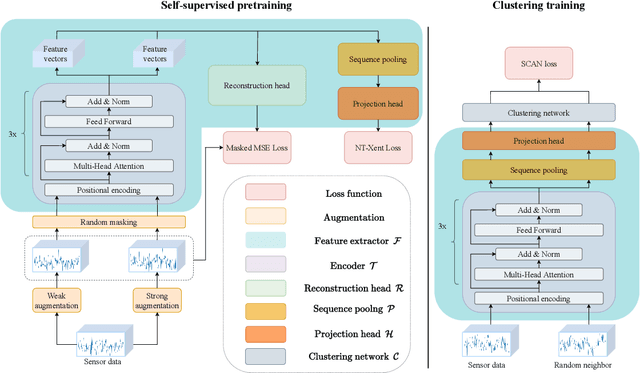
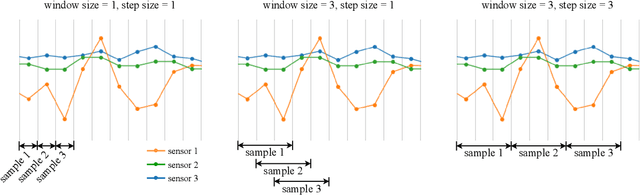
Modern industrial facilities generate large volumes of raw sensor data during production process. This data is used to monitor and control the processes and can be analyzed to detect and predict process abnormalities. Typically, the data has to be annotated by experts to be further used in predictive modeling. Most of today's research is focusing on either unsupervised anomaly detection algorithms or supervised methods, that require manually annotated data. The studies are often done using process simulator generated data for a narrow class of events and proposed algorithms are rarely verified on publicly available datasets. In this paper, we propose a novel method SensorSCAN for unsupervised fault detection and diagnosis designed for industrial chemical sensor data. We demonstrate our model performance on two publicly available datasets based on the Tennessee Eastman Process with various fault types. Results show that our method significantly outperforms existing approaches (+0.2-0.3 TPR for a fixed FPR) and detects most of the process faults without the use of expert annotation. In addition, we performed experiments to show that our method is suitable for real-world applications where the number of fault types is not known in advance.
New drugs and stock market: how to predict pharma market reaction to clinical trial announcements
Aug 16, 2022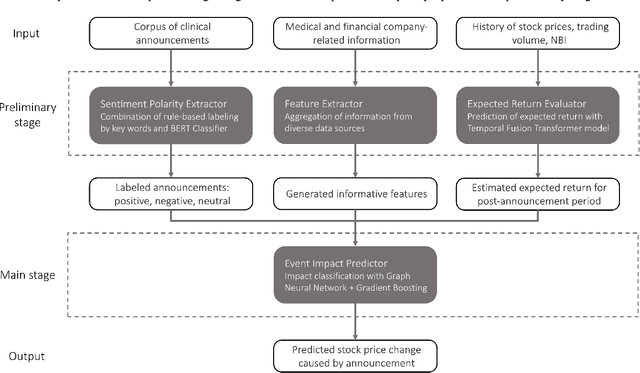


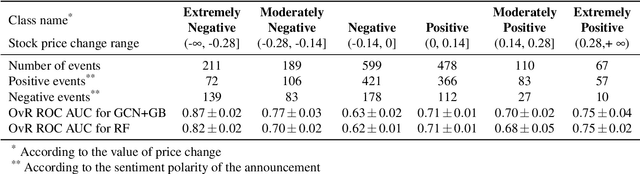
Pharmaceutical companies operate in a strictly regulated and highly risky environment in which a single slip can lead to serious financial implications. Accordingly, the announcements of clinical trial results tend to determine the future course of events, hence being closely monitored by the public. In this work, we provide statistical evidence for the result promulgation influence on the public pharma market value. Whereas most works focus on retrospective impact analysis, the present research aims to predict the numerical values of announcement-induced changes in stock prices. For this purpose, we develop a pipeline that includes a BERT-based model for extracting sentiment polarity of announcements, a Temporal Fusion Transformer for forecasting the expected return, a graph convolution network for capturing event relationships, and gradient boosting for predicting the price change. The challenge of the problem lies in inherently different patterns of responses to positive and negative announcements, reflected in a stronger and more pronounced reaction to the negative news. Moreover, such phenomenon as the drop in stocks after the positive announcements affirms the counterintuitiveness of the price behavior. Importantly, we discover two crucial factors that should be considered while working within a predictive framework. The first factor is the drug portfolio size of the company, indicating the greater susceptibility to an announcement in the case of small drug diversification. The second one is the network effect of the events related to the same company or nosology. All findings and insights are gained on the basis of one of the biggest FDA (the Food and Drug Administration) announcement datasets, consisting of 5436 clinical trial announcements from 681 companies over the last five years.
Anomaly segmentation model for defects detection in electroluminescence images of heterojunction solar cells
Aug 11, 2022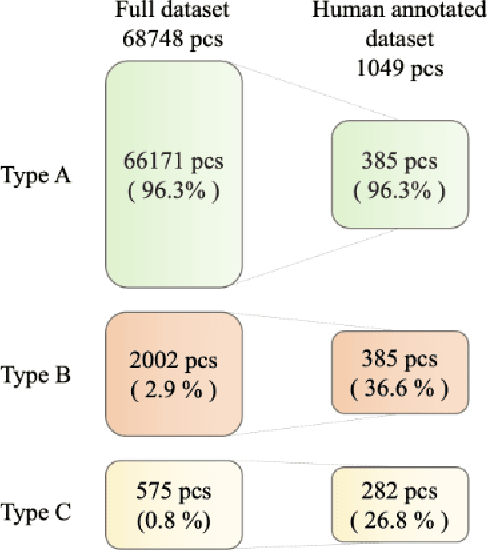
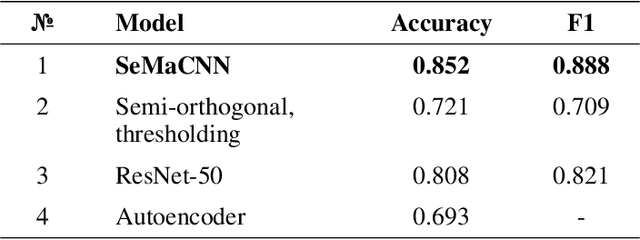

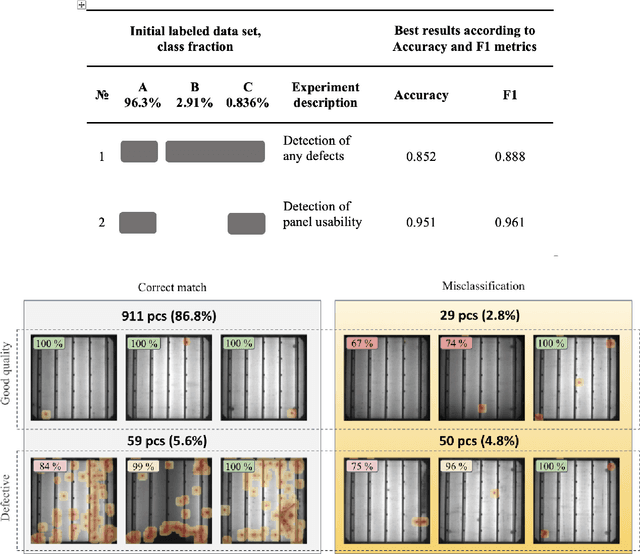
Efficient defect detection in solar cell manufacturing is crucial for stable green energy technology manufacturing. This paper presents a deep-learning-based automatic detection model SeMaCNN for classification and semantic segmentation of electroluminescent images for solar cell quality evaluation and anomalies detection. The core of the model is an anomaly detection algorithm based on Mahalanobis distance that can be trained in a semi-supervised manner on imbalanced data with small number of digital electroluminescence images with relevant defects. This is particularly valuable for prompt model integration into the industrial landscape. The model has been trained with the on-plant collected dataset consisting of 68 748 electroluminescent images of heterojunction solar cells with a busbar grid. Our model achieves the accuracy of 92.5%, F1 score 95.8%, recall 94.8%, and precision 96.9% within the validation subset consisting of 1049 manually annotated images. The model was also tested on the open ELPV dataset and demonstrates stable performance with accuracy 94.6% and F1 score 91.1%. The SeMaCNN model demonstrates a good balance between its performance and computational costs, which make it applicable for integrating into quality control systems of solar cell manufacturing.
Eco2AI: carbon emissions tracking of machine learning models as the first step towards sustainable AI
Aug 03, 2022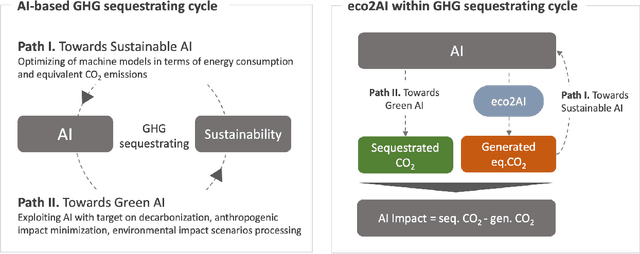
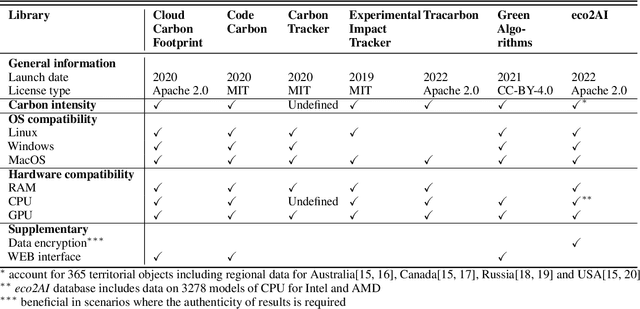


The size and complexity of deep neural networks continue to grow exponentially, significantly increasing energy consumption for training and inference by these models. We introduce an open-source package eco2AI to help data scientists and researchers to track energy consumption and equivalent CO2 emissions of their models in a straightforward way. In eco2AI we put emphasis on accuracy of energy consumption tracking and correct regional CO2 emissions accounting. We encourage research community to search for new optimal Artificial Intelligence (AI) architectures with a lower computational cost. The motivation also comes from the concept of AI-based green house gases sequestrating cycle with both Sustainable AI and Green AI pathways.
Towards Computationally Feasible Deep Active Learning
May 07, 2022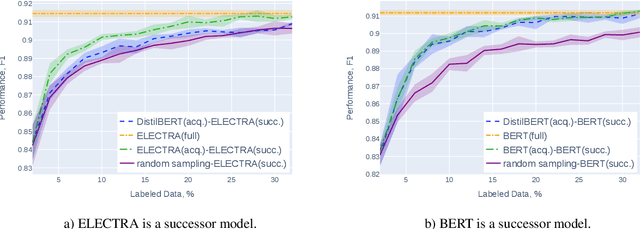
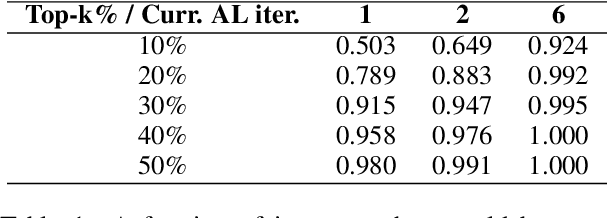
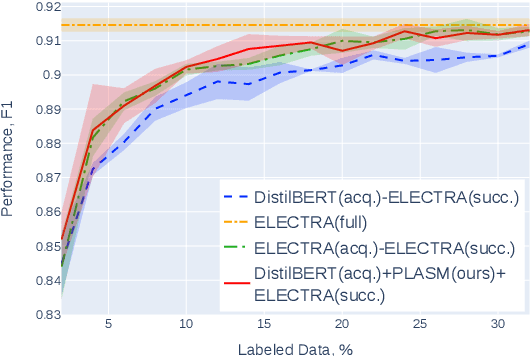
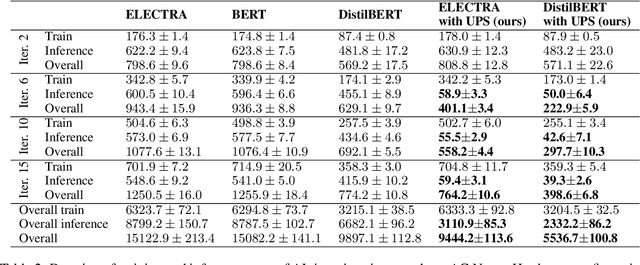
Active learning (AL) is a prominent technique for reducing the annotation effort required for training machine learning models. Deep learning offers a solution for several essential obstacles to deploying AL in practice but introduces many others. One of such problems is the excessive computational resources required to train an acquisition model and estimate its uncertainty on instances in the unlabeled pool. We propose two techniques that tackle this issue for text classification and tagging tasks, offering a substantial reduction of AL iteration duration and the computational overhead introduced by deep acquisition models in AL. We also demonstrate that our algorithm that leverages pseudo-labeling and distilled models overcomes one of the essential obstacles revealed previously in the literature. Namely, it was shown that due to differences between an acquisition model used to select instances during AL and a successor model trained on the labeled data, the benefits of AL can diminish. We show that our algorithm, despite using a smaller and faster acquisition model, is capable of training a more expressive successor model with higher performance.
Advanced service data provisioning in ROF-based mobile backhauls/fronthauls
Jan 31, 2022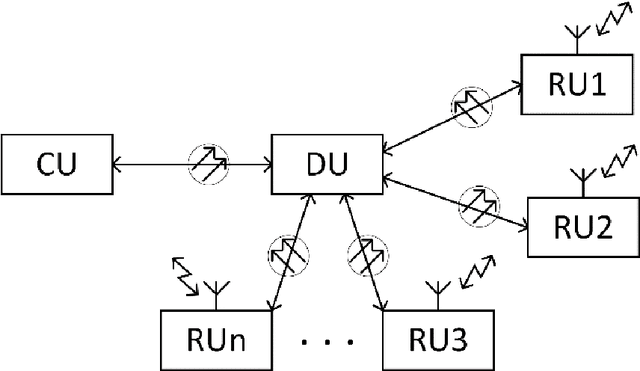
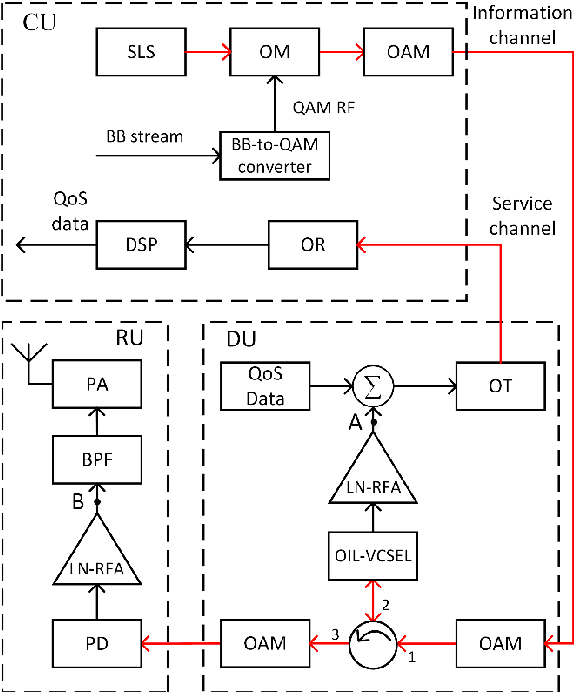
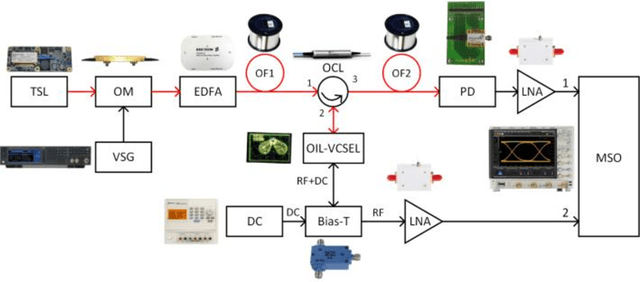
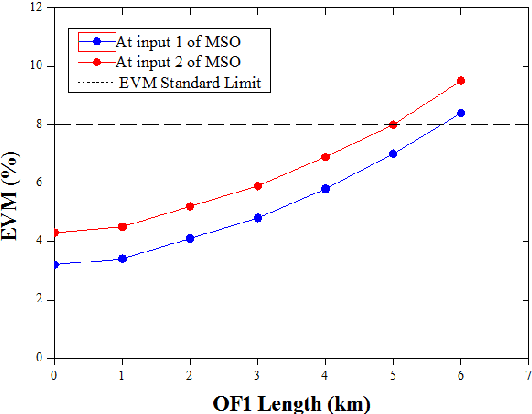
A new cost-efficient concept to realize a real-time monitoring of quality-of-service metrics and other service data in 5G and beyond access network using a separate return channel based on a vertical cavity surface emitting laser in the optical injection locked mode that simultaneously operates as an optical transmitter and as a resonant cavity enhanced photodetector, is proposed and discussed. The feasibility and efficiency of the proposed approach are confirmed by a proof-of-concept experiment when optically transceiving high-speed digital signal with multi-position quadrature amplitude modulation of a radio-frequency carrier.
Project Achoo: A Practical Model and Application for COVID-19 Detection from Recordings of Breath, Voice, and Cough
Jul 12, 2021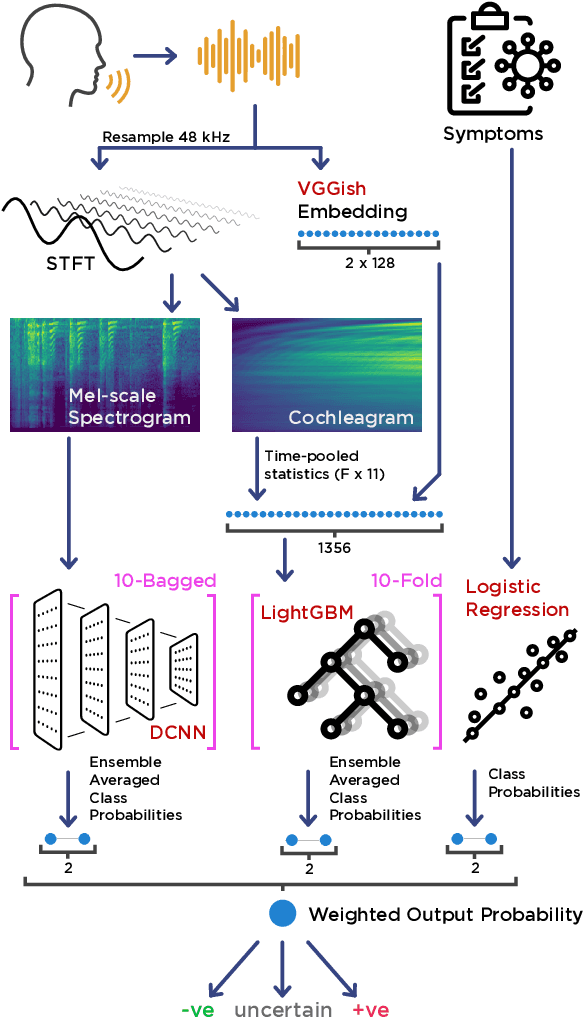
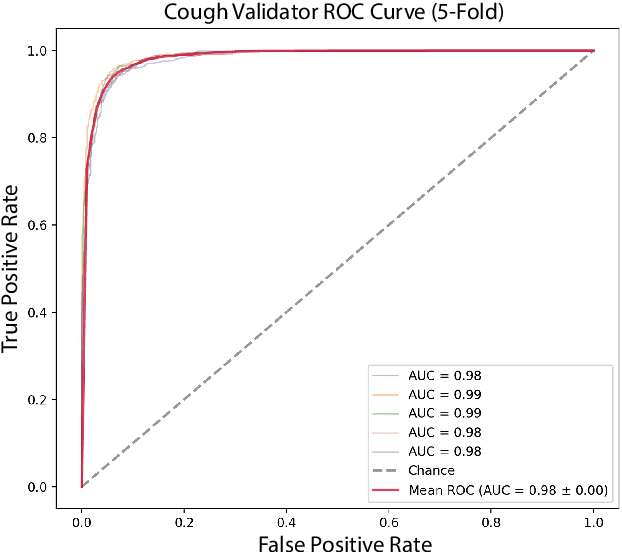
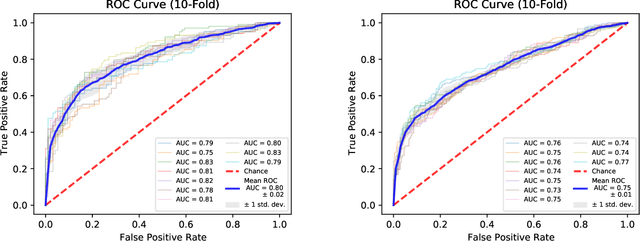
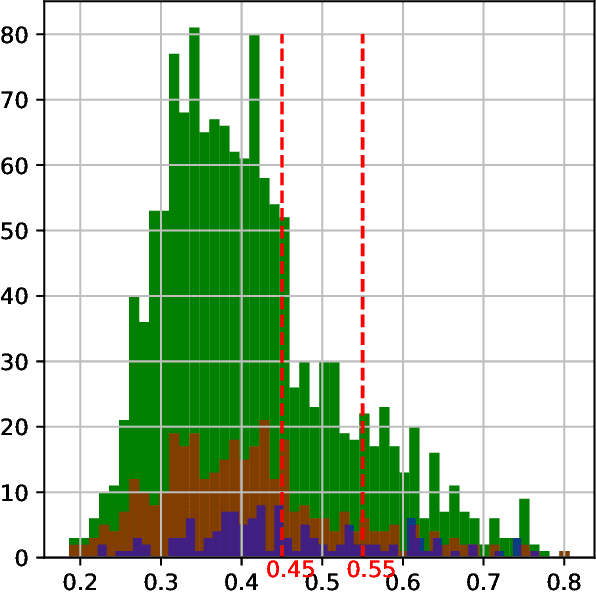
The COVID-19 pandemic created a significant interest and demand for infection detection and monitoring solutions. In this paper we propose a machine learning method to quickly triage COVID-19 using recordings made on consumer devices. The approach combines signal processing methods with fine-tuned deep learning networks and provides methods for signal denoising, cough detection and classification. We have also developed and deployed a mobile application that uses symptoms checker together with voice, breath and cough signals to detect COVID-19 infection. The application showed robust performance on both open sourced datasets and on the noisy data collected during beta testing by the end users.