 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Survival Analysis and Machine Learning for Mass Cancer Risk Prediction using EHR data
Sep 26, 2023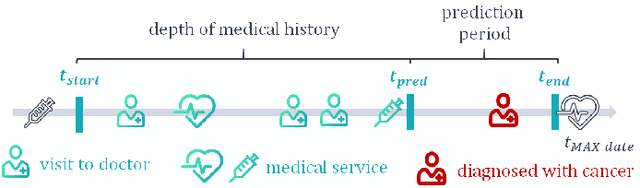



Purely medical cancer screening methods are often costly, time-consuming, and weakly applicable on a large scale. Advanced Artificial Intelligence (AI) methods greatly help cancer detection but require specific or deep medical data. These aspects affect the mass implementation of cancer screening methods. For these reasons, it is a disruptive change for healthcare to apply AI methods for mass personalized assessment of the cancer risk among patients based on the existing Electronic Health Records (EHR) volume. This paper presents a novel method for mass cancer risk prediction using EHR data. Among other methods, our one stands out by the minimum data greedy policy, requiring only a history of medical service codes and diagnoses from EHR. We formulate the problem as a binary classification. This dataset contains 175 441 de-identified patients (2 861 diagnosed with cancer). As a baseline, we implement a solution based on a recurrent neural network (RNN). We propose a method that combines machine learning and survival analysis since these approaches are less computationally heavy, can be combined into an ensemble (the Survival Ensemble), and can be reproduced in most medical institutions. We test the Survival Ensemble in some studies. Firstly, we obtain a significant difference between values of the primary metric (Average Precision) with 22.8% (ROC AUC 83.7%, F1 17.8%) for the Survival Ensemble versus 15.1% (ROC AUC 84.9%, F1 21.4%) for the Baseline. Secondly, the performance of the Survival Ensemble is also confirmed during the ablation study. Thirdly, our method exceeds age baselines by a significant margin. Fourthly, in the blind retrospective out-of-time experiment, the proposed method is reliable in cancer patient detection (9 out of 100 selected). Such results exceed the estimates of medical screenings, e.g., the best Number Needed to Screen (9 out of 1000 screenings).
Predicting COVID-19 and pneumonia complications from admission texts
May 05, 2023In this paper we present a novel approach to risk assessment for patients hospitalized with pneumonia or COVID-19 based on their admission reports. We applied a Longformer neural network to admission reports and other textual data available shortly after admission to compute risk scores for the patients. We used patient data of multiple European hospitals to demonstrate that our approach outperforms the Transformer baselines. Our experiments show that the proposed model generalises across institutions and diagnoses. Also, our method has several other advantages described in the paper.
Whole-body PET image denoising for reduced acquisition time
Mar 28, 2023

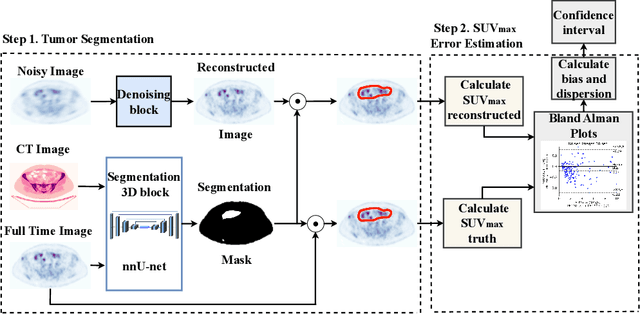
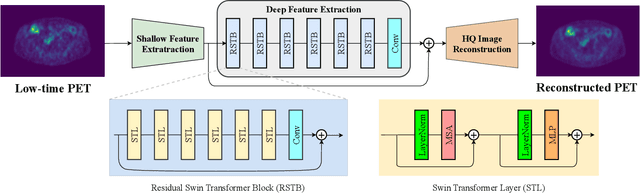
This paper evaluates the performance of supervised and unsupervised deep learning models for denoising positron emission tomography (PET) images in the presence of reduced acquisition times. Our experiments consider 212 studies (56908 images), and evaluate the models using 2D (RMSE, SSIM) and 3D (SUVpeak and SUVmax error for the regions of interest) metrics. It was shown that, in contrast to previous studies, supervised models (ResNet, Unet, SwinIR) outperform unsupervised models (pix2pix GAN and CycleGAN with ResNet backbone and various auxiliary losses) in the reconstruction of 2D PET images. Moreover, a hybrid approach of supervised CycleGAN shows the best results in SUVmax estimation for denoised images, and the SUVmax estimation error for denoised images is comparable with the PET reproducibility error.
NeuralSympCheck: A Symptom Checking and Disease Diagnostic Neural Model with Logic Regularization
Jun 02, 2022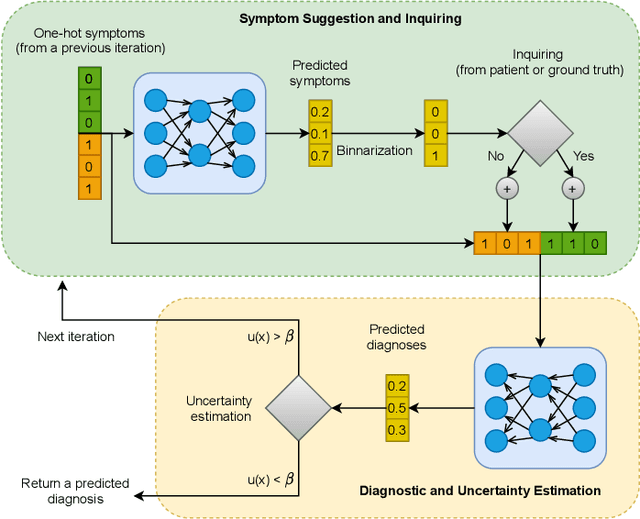
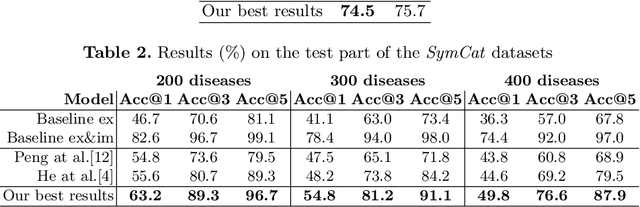
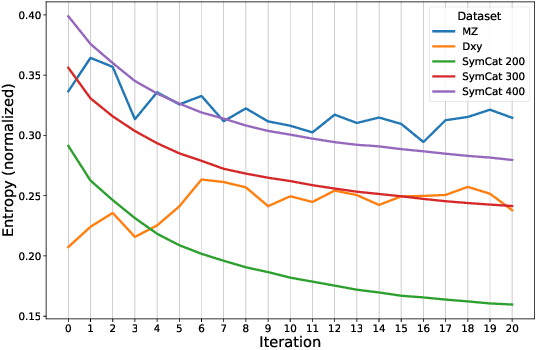
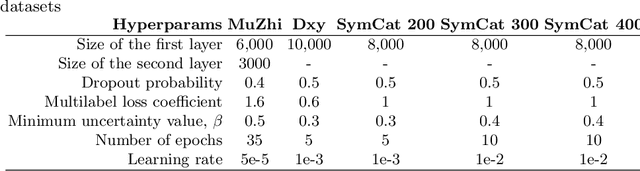
The symptom checking systems inquire users for their symptoms and perform a rapid and affordable medical assessment of their condition. The basic symptom checking systems based on Bayesian methods, decision trees, or information gain methods are easy to train and do not require significant computational resources. However, their drawbacks are low relevance of proposed symptoms and insufficient quality of diagnostics. The best results on these tasks are achieved by reinforcement learning models. Their weaknesses are the difficulty of developing and training such systems and limited applicability to cases with large and sparse decision spaces. We propose a new approach based on the supervised learning of neural models with logic regularization that combines the advantages of the different methods. Our experiments on real and synthetic data show that the proposed approach outperforms the best existing methods in the accuracy of diagnosis when the number of diagnoses and symptoms is large.
Abstractive summarization of hospitalisation histories with transformer networks
Apr 05, 2022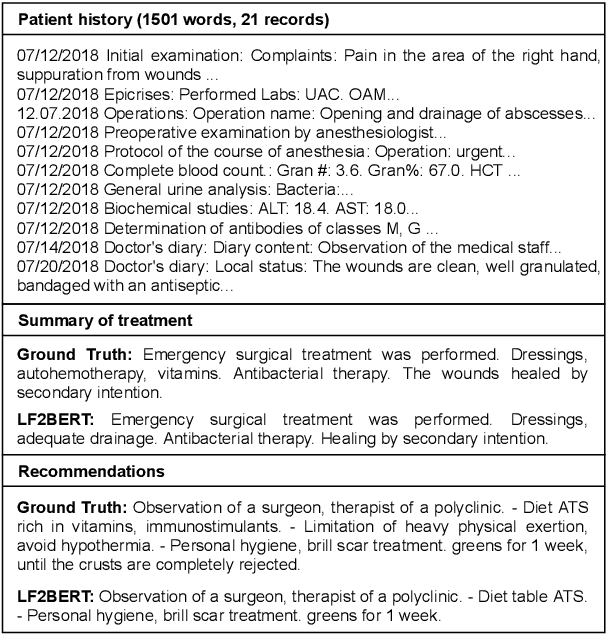
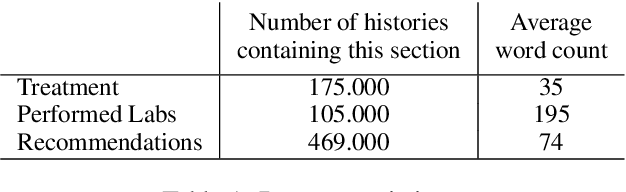
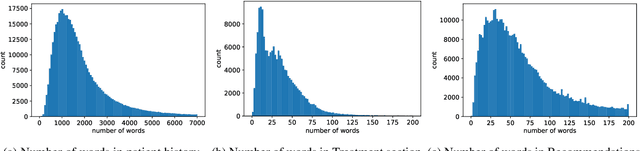
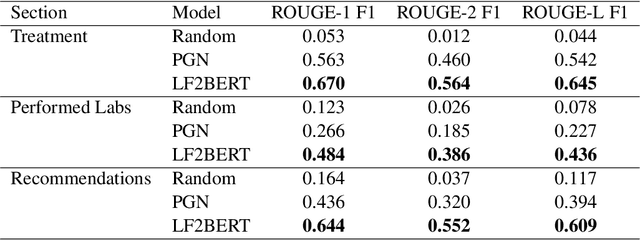
In this paper we present a novel approach to abstractive summarization of patient hospitalisation histories. We applied an encoder-decoder framework with Longformer neural network as an encoder and BERT as a decoder. Our experiments show improved quality on some summarization tasks compared with pointer-generator networks. We also conducted a study with experienced physicians evaluating the results of our model in comparison with PGN baseline and human-generated abstracts, which showed the effectiveness of our model.
RuMedBench: A Russian Medical Language Understanding Benchmark
Jan 17, 2022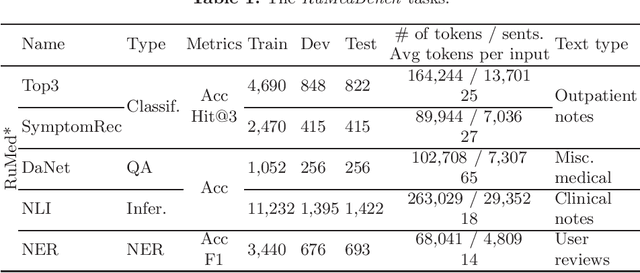


The paper describes the open Russian medical language understanding benchmark covering several task types (classification, question answering, natural language inference, named entity recognition) on a number of novel text sets. Given the sensitive nature of the data in healthcare, such a benchmark partially closes the problem of Russian medical dataset absence. We prepare the unified format labeling, data split, and evaluation metrics for new tasks. The remaining tasks are from existing datasets with a few modifications. A single-number metric expresses a model's ability to cope with the benchmark. Moreover, we implement several baseline models, from simple ones to neural networks with transformer architecture, and release the code. Expectedly, the more advanced models yield better performance, but even a simple model is enough for a decent result in some tasks. Furthermore, for all tasks, we provide a human evaluation. Interestingly the models outperform humans in the large-scale classification tasks. However, the advantage of natural intelligence remains in the tasks requiring more knowledge and reasoning.
Project Achoo: A Practical Model and Application for COVID-19 Detection from Recordings of Breath, Voice, and Cough
Jul 12, 2021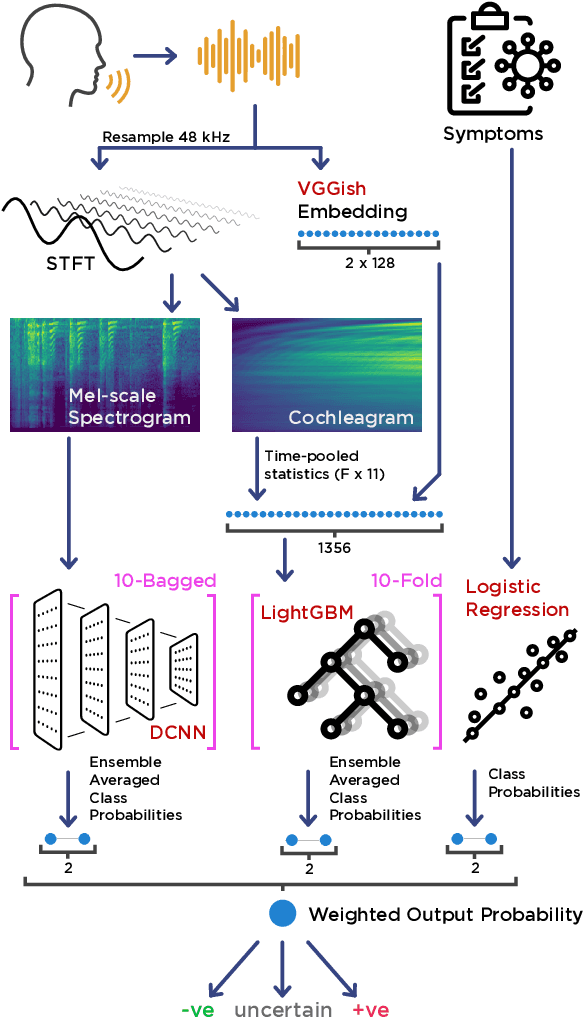
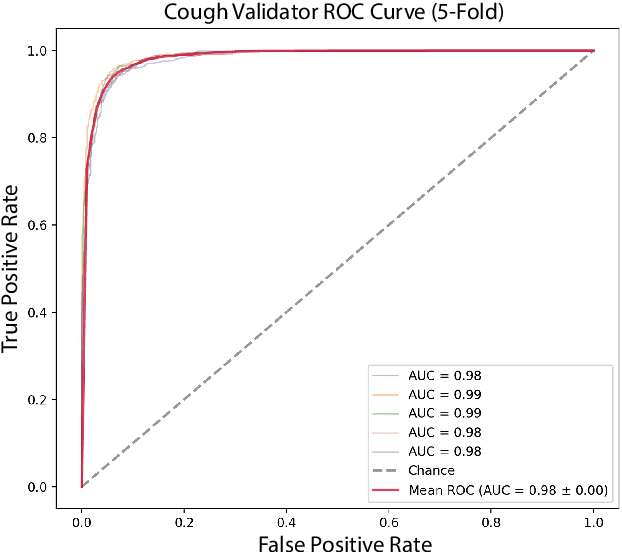
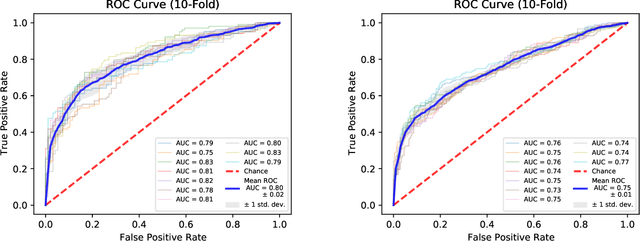
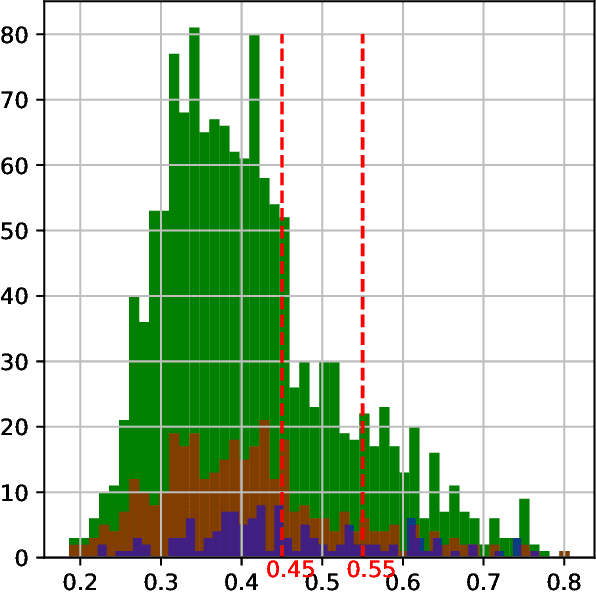
The COVID-19 pandemic created a significant interest and demand for infection detection and monitoring solutions. In this paper we propose a machine learning method to quickly triage COVID-19 using recordings made on consumer devices. The approach combines signal processing methods with fine-tuned deep learning networks and provides methods for signal denoising, cough detection and classification. We have also developed and deployed a mobile application that uses symptoms checker together with voice, breath and cough signals to detect COVID-19 infection. The application showed robust performance on both open sourced datasets and on the noisy data collected during beta testing by the end users.
Patient Embeddings in Healthcare and Insurance Applications
Jun 21, 2021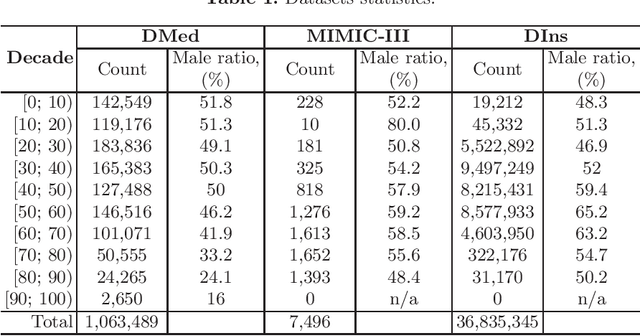

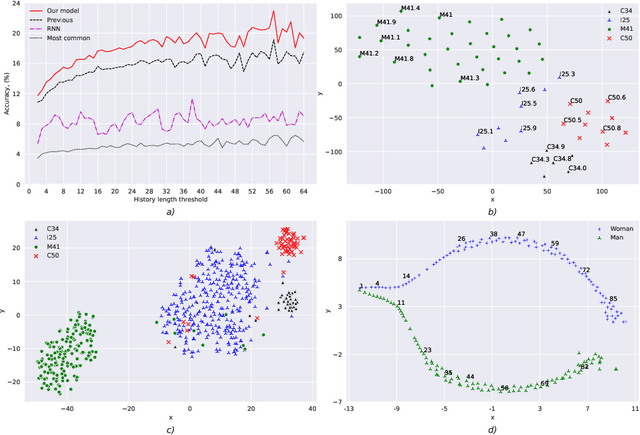

The paper researches the problem of concept and patient representations in the medical domain. We present the patient histories from Electronic Health Records (EHRs) as temporal sequences of ICD concepts for which embeddings are learned in an unsupervised setup with a transformer-based neural network model. The model training was performed on the collection of one million patients' histories in 6 years. The predictive power of such a model is assessed in comparison with several baseline methods. A series of experiments on the MIMIC-III data show the advantage of the presented model compared to a similar system. Further, we analyze the obtained embedding space with regards to concept relations and show how knowledge from the medical domain can be successfully transferred to the practical task of insurance scoring in the form of patient embeddings.
CoRSAI: A System for Robust Interpretation of CT Scans of COVID-19 Patients Using Deep Learning
May 25, 2021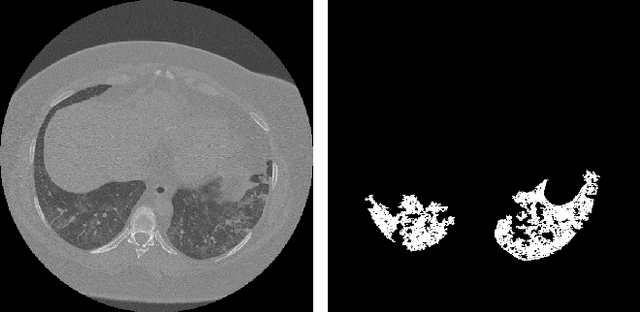

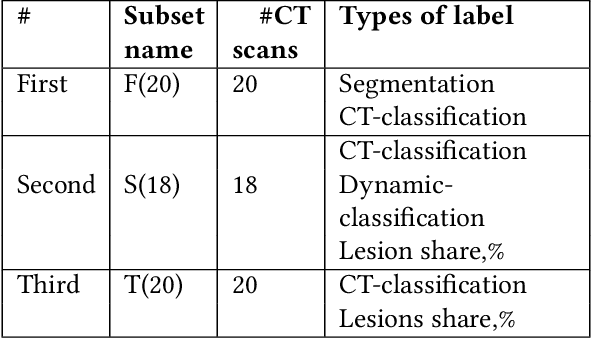

Analysis of chest CT scans can be used in detecting parts of lungs that are affected by infectious diseases such as COVID-19.Determining the volume of lungs affected by lesions is essential for formulating treatment recommendations and prioritizingpatients by severity of the disease. In this paper we adopted an approach based on using an ensemble of deep convolutionalneural networks for segmentation of slices of lung CT scans. Using our models we are able to segment the lesions, evaluatepatients dynamics, estimate relative volume of lungs affected by lesions and evaluate the lung damage stage. Our modelswere trained on data from different medical centers. We compared predictions of our models with those of six experiencedradiologists and our segmentation model outperformed most of them. On the task of classification of disease severity, ourmodel outperformed all the radiologists.
Predicting Clinical Diagnosis from Patients Electronic Health Records Using BERT-based Neural Networks
Jul 15, 2020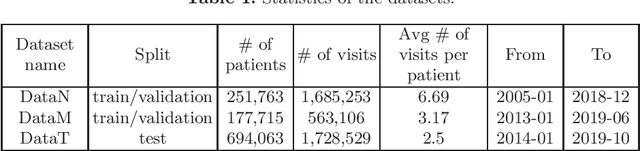
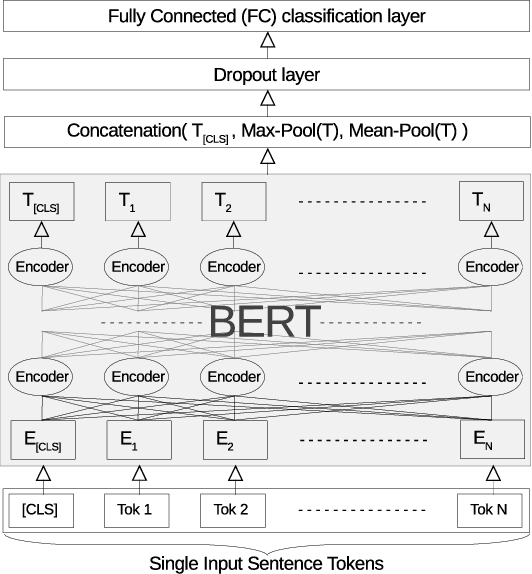
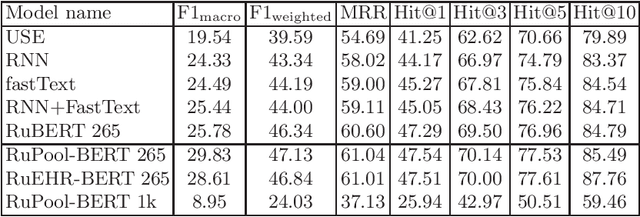
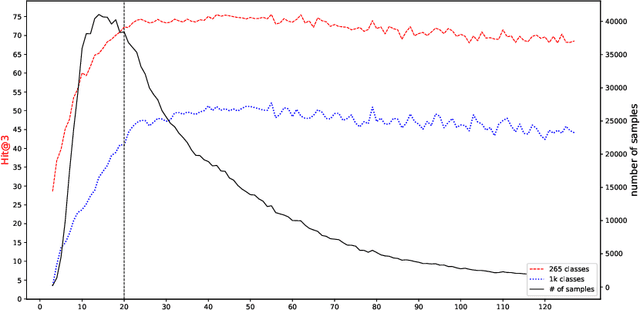
In this paper we study the problem of predicting clinical diagnoses from textual Electronic Health Records (EHR) data. We show the importance of this problem in medical community and present comprehensive historical review of the problem and proposed methods. As the main scientific contributions we present a modification of Bidirectional Encoder Representations from Transformers (BERT) model for sequence classification that implements a novel way of Fully-Connected (FC) layer composition and a BERT model pretrained only on domain data. To empirically validate our model, we use a large-scale Russian EHR dataset consisting of about 4 million unique patient visits. This is the largest such study for the Russian language and one of the largest globally. We performed a number of comparative experiments with other text representation models on the task of multiclass classification for 265 disease subset of ICD-10. The experiments demonstrate improved performance of our models compared to other baselines, including a fine-tuned Russian BERT (RuBERT) variant. We also show comparable performance of our model with a panel of experienced medical experts. This allows us to hope that implementation of this system will reduce misdiagnosis.