 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze into the Heart: A Multi-View Video Dataset for rPPG and Health Biomarkers Estimation
Aug 25, 2025Progress in remote PhotoPlethysmoGraphy (rPPG) is limited by the critical issues of existing publicly available datasets: small size, privacy concerns with facial videos, and lack of diversity in conditions. The paper introduces a novel comprehensive large-scale multi-view video dataset for rPPG and health biomarkers estimation. Our dataset comprises 3600 synchronized video recordings from 600 subjects, captured under varied conditions (resting and post-exercise) using multiple consumer-grade cameras at different angles. To enable multimodal analysis of physiological states, each recording is paired with a 100 Hz PPG signal and extended health metrics, such as electrocardiogram, arterial blood pressure, biomarkers, temperature, oxygen saturation, respiratory rate, and stress level. Using this data, we train an efficient rPPG model and compare its quality with existing approaches in cross-dataset scenarios. The public release of our dataset and model should significantly speed up the progress in the development of AI medical assistants.
MedSyn: LLM-based Synthetic Medical Text Generation Framework
Aug 04, 2024Generating synthetic text addresses the challenge of data availability in privacy-sensitive domains such as healthcare. This study explores the applicability of synthetic data in real-world medical settings. We introduce MedSyn, a novel medical text generation framework that integrates large language models with a Medical Knowledge Graph (MKG). We use MKG to sample prior medical information for the prompt and generate synthetic clinical notes with GPT-4 and fine-tuned LLaMA models. We assess the benefit of synthetic data through application in the ICD code prediction task. Our research indicates that synthetic data can increase the classification accuracy of vital and challenging codes by up to 17.8% compared to settings without synthetic data. Furthermore, to provide new data for further research in the healthcare domain, we present the largest open-source synthetic dataset of clinical notes for the Russian language, comprising over 41k samples covering 219 ICD-10 codes.
End-to-end SYNTAX score prediction: benchmark and methods
Jul 29, 2024
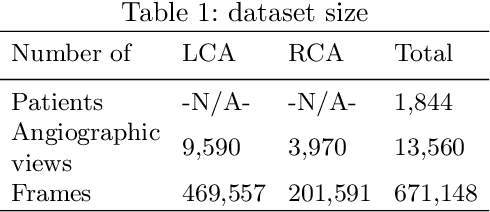
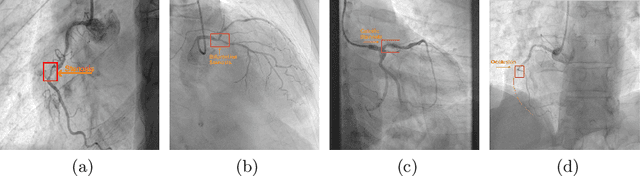
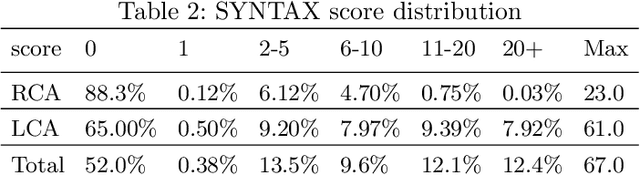
The SYNTAX score has become a widely used measure of coronary disease severity , crucial in selecting the optimal mode of revascularization. This paper introduces a new medical regression and classification problem - automatically estimating SYNTAX score from coronary angiography. Our study presents a comprehensive dataset of 1,844 patients, featuring a balanced distribution of individuals with zero and non-zero scores. This dataset includes a first-of-its-kind, complete coronary angiography samples captured through a multi-view X-ray video, allowing one to observe coronary arteries from multiple perspectives. Furthermore, we present a novel, fully automatic end-to-end method for estimating the SYNTAX. For such a difficult task, we have achieved a solid coefficient of determination R2 of 0.51 in score predictions.
GigaPevt: Multimodal Medical Assistant
Feb 26, 2024Building an intelligent and efficient medical assistant is still a challenging AI problem. The major limitation comes from the data modality scarceness, which reduces comprehensive patient perception. This demo paper presents the GigaPevt, the first multimodal medical assistant that combines the dialog capabilities of large language models with specialized medical models. Such an approach shows immediate advantages in dialog quality and metric performance, with a 1.18\% accuracy improvement in the question-answering task.
Combining Survival Analysis and Machine Learning for Mass Cancer Risk Prediction using EHR data
Sep 26, 2023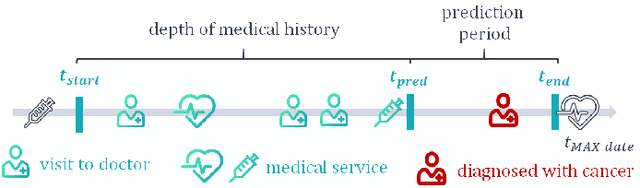



Purely medical cancer screening methods are often costly, time-consuming, and weakly applicable on a large scale. Advanced Artificial Intelligence (AI) methods greatly help cancer detection but require specific or deep medical data. These aspects affect the mass implementation of cancer screening methods. For these reasons, it is a disruptive change for healthcare to apply AI methods for mass personalized assessment of the cancer risk among patients based on the existing Electronic Health Records (EHR) volume. This paper presents a novel method for mass cancer risk prediction using EHR data. Among other methods, our one stands out by the minimum data greedy policy, requiring only a history of medical service codes and diagnoses from EHR. We formulate the problem as a binary classification. This dataset contains 175 441 de-identified patients (2 861 diagnosed with cancer). As a baseline, we implement a solution based on a recurrent neural network (RNN). We propose a method that combines machine learning and survival analysis since these approaches are less computationally heavy, can be combined into an ensemble (the Survival Ensemble), and can be reproduced in most medical institutions. We test the Survival Ensemble in some studies. Firstly, we obtain a significant difference between values of the primary metric (Average Precision) with 22.8% (ROC AUC 83.7%, F1 17.8%) for the Survival Ensemble versus 15.1% (ROC AUC 84.9%, F1 21.4%) for the Baseline. Secondly, the performance of the Survival Ensemble is also confirmed during the ablation study. Thirdly, our method exceeds age baselines by a significant margin. Fourthly, in the blind retrospective out-of-time experiment, the proposed method is reliable in cancer patient detection (9 out of 100 selected). Such results exceed the estimates of medical screenings, e.g., the best Number Needed to Screen (9 out of 1000 screenings).
RuMedBench: A Russian Medical Language Understanding Benchmark
Jan 17, 2022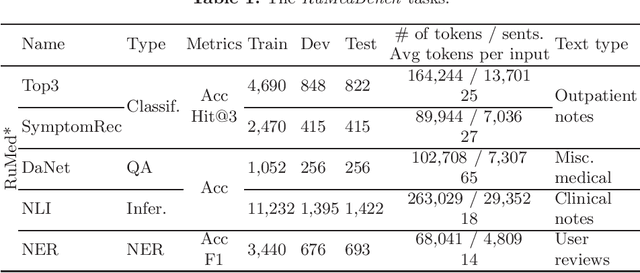


The paper describes the open Russian medical language understanding benchmark covering several task types (classification, question answering, natural language inference, named entity recognition) on a number of novel text sets. Given the sensitive nature of the data in healthcare, such a benchmark partially closes the problem of Russian medical dataset absence. We prepare the unified format labeling, data split, and evaluation metrics for new tasks. The remaining tasks are from existing datasets with a few modifications. A single-number metric expresses a model's ability to cope with the benchmark. Moreover, we implement several baseline models, from simple ones to neural networks with transformer architecture, and release the code. Expectedly, the more advanced models yield better performance, but even a simple model is enough for a decent result in some tasks. Furthermore, for all tasks, we provide a human evaluation. Interestingly the models outperform humans in the large-scale classification tasks. However, the advantage of natural intelligence remains in the tasks requiring more knowledge and reasoning.
Patient Embeddings in Healthcare and Insurance Applications
Jun 21, 2021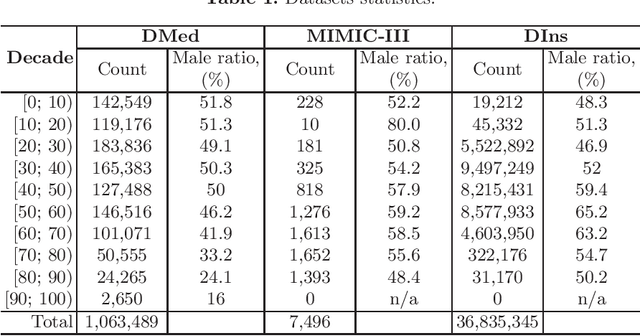

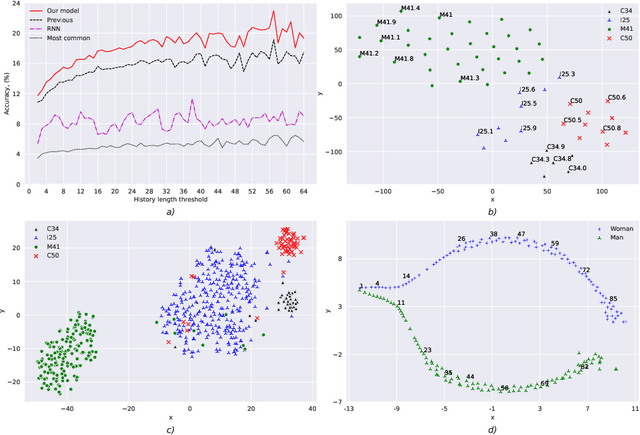

The paper researches the problem of concept and patient representations in the medical domain. We present the patient histories from Electronic Health Records (EHRs) as temporal sequences of ICD concepts for which embeddings are learned in an unsupervised setup with a transformer-based neural network model. The model training was performed on the collection of one million patients' histories in 6 years. The predictive power of such a model is assessed in comparison with several baseline methods. A series of experiments on the MIMIC-III data show the advantage of the presented model compared to a similar system. Further, we analyze the obtained embedding space with regards to concept relations and show how knowledge from the medical domain can be successfully transferred to the practical task of insurance scoring in the form of patient embeddings.
Predicting Clinical Diagnosis from Patients Electronic Health Records Using BERT-based Neural Networks
Jul 15, 2020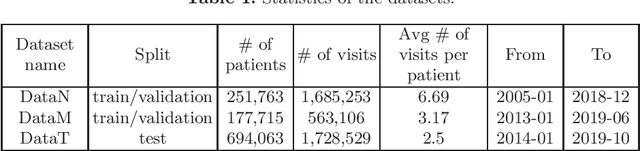
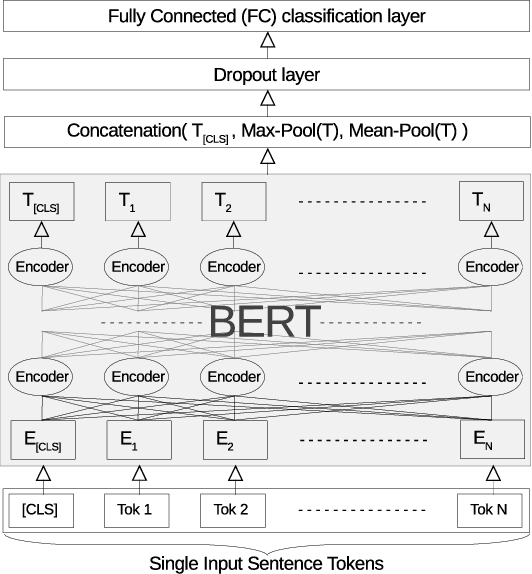
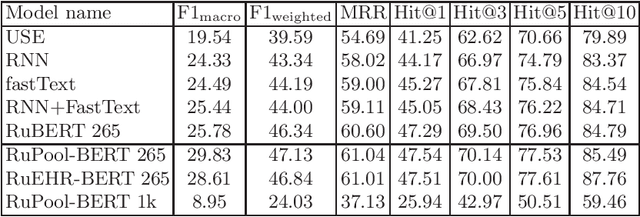
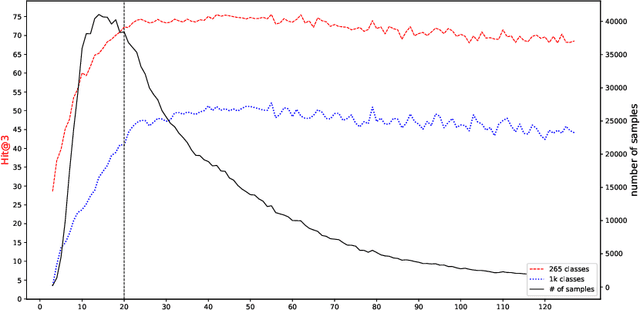
In this paper we study the problem of predicting clinical diagnoses from textual Electronic Health Records (EHR) data. We show the importance of this problem in medical community and present comprehensive historical review of the problem and proposed methods. As the main scientific contributions we present a modification of Bidirectional Encoder Representations from Transformers (BERT) model for sequence classification that implements a novel way of Fully-Connected (FC) layer composition and a BERT model pretrained only on domain data. To empirically validate our model, we use a large-scale Russian EHR dataset consisting of about 4 million unique patient visits. This is the largest such study for the Russian language and one of the largest globally. We performed a number of comparative experiments with other text representation models on the task of multiclass classification for 265 disease subset of ICD-10. The experiments demonstrate improved performance of our models compared to other baselines, including a fine-tuned Russian BERT (RuBERT) variant. We also show comparable performance of our model with a panel of experienced medical experts. This allows us to hope that implementation of this system will reduce misdiagnosis.