 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak-to-Strong 3D Object Detection with X-Ray Distillation
Mar 31, 2024This paper addresses the critical challenges of sparsity and occlusion in LiDAR-based 3D object detection. Current methods often rely on supplementary modules or specific architectural designs, potentially limiting their applicability to new and evolving architectures. To our knowledge, we are the first to propose a versatile technique that seamlessly integrates into any existing framework for 3D Object Detection, marking the first instance of Weak-to-Strong generalization in 3D computer vision. We introduce a novel framework, X-Ray Distillation with Object-Complete Frames, suitable for both supervised and semi-supervised settings, that leverages the temporal aspect of point cloud sequences. This method extracts crucial information from both previous and subsequent LiDAR frames, creating Object-Complete frames that represent objects from multiple viewpoints, thus addressing occlusion and sparsity. Given the limitation of not being able to generate Object-Complete frames during online inference, we utilize Knowledge Distillation within a Teacher-Student framework. This technique encourages the strong Student model to emulate the behavior of the weaker Teacher, which processes simple and informative Object-Complete frames, effectively offering a comprehensive view of objects as if seen through X-ray vision. Our proposed methods surpass state-of-the-art in semi-supervised learning by 1-1.5 mAP and enhance the performance of five established supervised models by 1-2 mAP on standard autonomous driving datasets, even with default hyperparameters. Code for Object-Complete frames is available here: https://github.com/sakharok13/X-Ray-Teacher-Patching-Tools.
Refining the ONCE Benchmark with Hyperparameter Tuning
Nov 10, 2023In response to the growing demand for 3D object detection in applications such as autonomous driving, robotics, and augmented reality, this work focuses on the evaluation of semi-supervised learning approaches for point cloud data. The point cloud representation provides reliable and consistent observations regardless of lighting conditions, thanks to advances in LiDAR sensors. Data annotation is of paramount importance in the context of LiDAR applications, and automating 3D data annotation with semi-supervised methods is a pivotal challenge that promises to reduce the associated workload and facilitate the emergence of cost-effective LiDAR solutions. Nevertheless, the task of semi-supervised learning in the context of unordered point cloud data remains formidable due to the inherent sparsity and incomplete shapes that hinder the generation of accurate pseudo-labels. In this study, we consider these challenges by posing the question: "To what extent does unlabelled data contribute to the enhancement of model performance?" We show that improvements from previous semi-supervised methods may not be as profound as previously thought. Our results suggest that simple grid search hyperparameter tuning applied to a supervised model can lead to state-of-the-art performance on the ONCE dataset, while the contribution of unlabelled data appears to be comparatively less exceptional.
SensorSCAN: Self-Supervised Learning and Deep Clustering for Fault Diagnosis in Chemical Processes
Aug 17, 2022
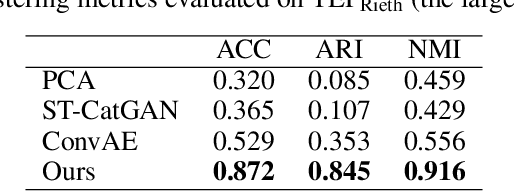
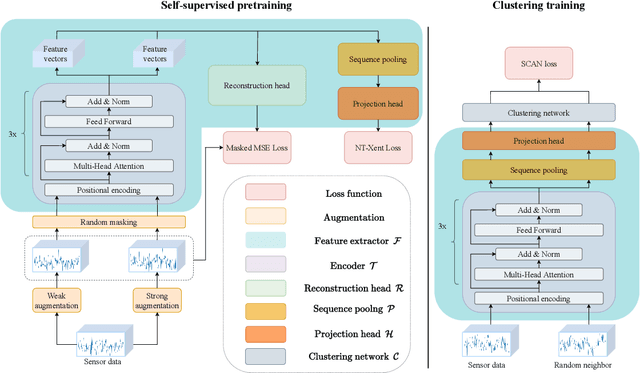
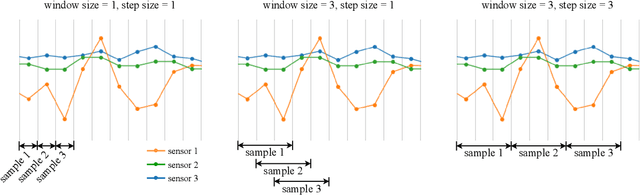
Modern industrial facilities generate large volumes of raw sensor data during production process. This data is used to monitor and control the processes and can be analyzed to detect and predict process abnormalities. Typically, the data has to be annotated by experts to be further used in predictive modeling. Most of today's research is focusing on either unsupervised anomaly detection algorithms or supervised methods, that require manually annotated data. The studies are often done using process simulator generated data for a narrow class of events and proposed algorithms are rarely verified on publicly available datasets. In this paper, we propose a novel method SensorSCAN for unsupervised fault detection and diagnosis designed for industrial chemical sensor data. We demonstrate our model performance on two publicly available datasets based on the Tennessee Eastman Process with various fault types. Results show that our method significantly outperforms existing approaches (+0.2-0.3 TPR for a fixed FPR) and detects most of the process faults without the use of expert annotation. In addition, we performed experiments to show that our method is suitable for real-world applications where the number of fault types is not known in advance.