 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Reasoning Through Visual Human Preferences with VLMs and Soft Rewards
Mar 25, 2025Can Visual Language Models (VLMs) effectively capture human visual preferences? This work addresses this question by training VLMs to think about preferences at test time, employing reinforcement learning methods inspired by DeepSeek R1 and OpenAI O1. Using datasets such as ImageReward and Human Preference Score v2 (HPSv2), our models achieve accuracies of 64.9% on the ImageReward test set (trained on ImageReward official split) and 65.4% on HPSv2 (trained on approximately 25% of its data). These results match traditional encoder-based models while providing transparent reasoning and enhanced generalization. This approach allows to use not only rich VLM world knowledge, but also its potential to think, yielding interpretable outcomes that help decision-making processes. By demonstrating that human visual preferences reasonable by current VLMs, we introduce efficient soft-reward strategies for image ranking, outperforming simplistic selection or scoring methods. This reasoning capability enables VLMs to rank arbitrary images-regardless of aspect ratio or complexity-thereby potentially amplifying the effectiveness of visual Preference Optimization. By reducing the need for extensive markup while improving reward generalization and explainability, our findings can be a strong mile-stone that will enhance text-to-vision models even further.
MaxInfo: A Training-Free Key-Frame Selection Method Using Maximum Volume for Enhanced Video Understanding
Feb 05, 2025Modern Video Large Language Models (VLLMs) often rely on uniform frame sampling for video understanding, but this approach frequently fails to capture critical information due to frame redundancy and variations in video content. We propose MaxInfo, a training-free method based on the maximum volume principle, which selects and retains the most representative frames from the input video. By maximizing the geometric volume formed by selected embeddings, MaxInfo ensures that the chosen frames cover the most informative regions of the embedding space, effectively reducing redundancy while preserving diversity. This method enhances the quality of input representations and improves long video comprehension performance across benchmarks. For instance, MaxInfo achieves a 3.28% improvement on LongVideoBench and a 6.4% improvement on EgoSchema for LLaVA-Video-7B. It also achieves a 3.47% improvement for LLaVA-Video-72B. The approach is simple to implement and works with existing VLLMs without the need for additional training, making it a practical and effective alternative to traditional uniform sampling methods.
Aligning Diffusion Models with Noise-Conditioned Perception
Jun 25, 2024
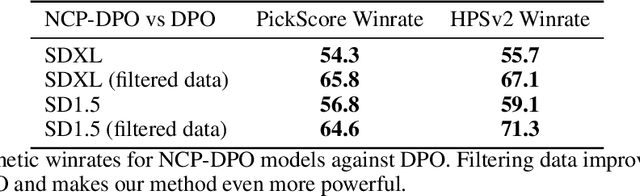


Recent advancements in human preference optimization, initially developed for Language Models (LMs), have shown promise for text-to-image Diffusion Models, enhancing prompt alignment, visual appeal, and user preference. Unlike LMs, Diffusion Models typically optimize in pixel or VAE space, which does not align well with human perception, leading to slower and less efficient training during the preference alignment stage. We propose using a perceptual objective in the U-Net embedding space of the diffusion model to address these issues. Our approach involves fine-tuning Stable Diffusion 1.5 and XL using Direct Preference Optimization (DPO), Contrastive Preference Optimization (CPO), and supervised fine-tuning (SFT) within this embedding space. This method significantly outperforms standard latent-space implementations across various metrics, including quality and computational cost. For SDXL, our approach provides 60.8\% general preference, 62.2\% visual appeal, and 52.1\% prompt following against original open-sourced SDXL-DPO on the PartiPrompts dataset, while significantly reducing compute. Our approach not only improves the efficiency and quality of human preference alignment for diffusion models but is also easily integrable with other optimization techniques. The training code and LoRA weights will be available here: https://huggingface.co/alexgambashidze/SDXL\_NCP-DPO\_v0.1
Weak-to-Strong 3D Object Detection with X-Ray Distillation
Mar 31, 2024This paper addresses the critical challenges of sparsity and occlusion in LiDAR-based 3D object detection. Current methods often rely on supplementary modules or specific architectural designs, potentially limiting their applicability to new and evolving architectures. To our knowledge, we are the first to propose a versatile technique that seamlessly integrates into any existing framework for 3D Object Detection, marking the first instance of Weak-to-Strong generalization in 3D computer vision. We introduce a novel framework, X-Ray Distillation with Object-Complete Frames, suitable for both supervised and semi-supervised settings, that leverages the temporal aspect of point cloud sequences. This method extracts crucial information from both previous and subsequent LiDAR frames, creating Object-Complete frames that represent objects from multiple viewpoints, thus addressing occlusion and sparsity. Given the limitation of not being able to generate Object-Complete frames during online inference, we utilize Knowledge Distillation within a Teacher-Student framework. This technique encourages the strong Student model to emulate the behavior of the weaker Teacher, which processes simple and informative Object-Complete frames, effectively offering a comprehensive view of objects as if seen through X-ray vision. Our proposed methods surpass state-of-the-art in semi-supervised learning by 1-1.5 mAP and enhance the performance of five established supervised models by 1-2 mAP on standard autonomous driving datasets, even with default hyperparameters. Code for Object-Complete frames is available here: https://github.com/sakharok13/X-Ray-Teacher-Patching-Tools.
Refining the ONCE Benchmark with Hyperparameter Tuning
Nov 10, 2023In response to the growing demand for 3D object detection in applications such as autonomous driving, robotics, and augmented reality, this work focuses on the evaluation of semi-supervised learning approaches for point cloud data. The point cloud representation provides reliable and consistent observations regardless of lighting conditions, thanks to advances in LiDAR sensors. Data annotation is of paramount importance in the context of LiDAR applications, and automating 3D data annotation with semi-supervised methods is a pivotal challenge that promises to reduce the associated workload and facilitate the emergence of cost-effective LiDAR solutions. Nevertheless, the task of semi-supervised learning in the context of unordered point cloud data remains formidable due to the inherent sparsity and incomplete shapes that hinder the generation of accurate pseudo-labels. In this study, we consider these challenges by posing the question: "To what extent does unlabelled data contribute to the enhancement of model performance?" We show that improvements from previous semi-supervised methods may not be as profound as previously thought. Our results suggest that simple grid search hyperparameter tuning applied to a supervised model can lead to state-of-the-art performance on the ONCE dataset, while the contribution of unlabelled data appears to be comparatively less exceptional.