 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdventures in Demand Analysis Using AI
Dec 31, 2024

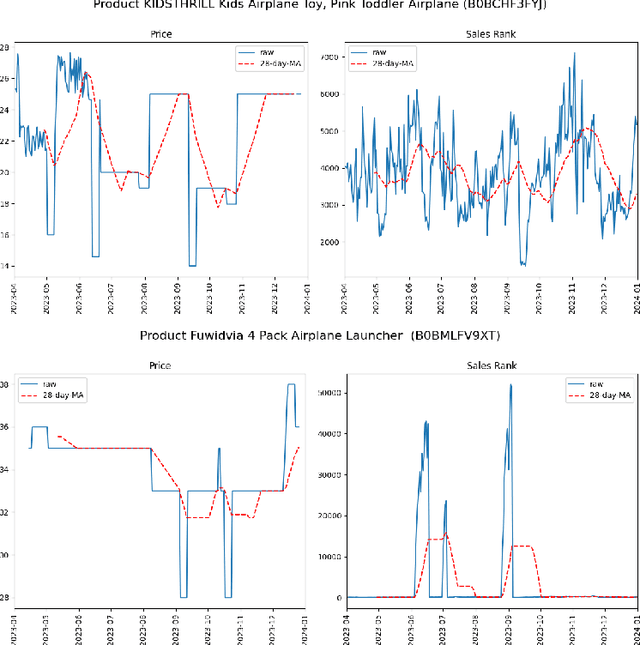

This paper advances empirical demand analysis by integrating multimodal product representations derived from artificial intelligence (AI). Using a detailed dataset of toy cars on \textit{Amazon.com}, we combine text descriptions, images, and tabular covariates to represent each product using transformer-based embedding models. These embeddings capture nuanced attributes, such as quality, branding, and visual characteristics, that traditional methods often struggle to summarize. Moreover, we fine-tune these embeddings for causal inference tasks. We show that the resulting embeddings substantially improve the predictive accuracy of sales ranks and prices and that they lead to more credible causal estimates of price elasticity. Notably, we uncover strong heterogeneity in price elasticity driven by these product-specific features. Our findings illustrate that AI-driven representations can enrich and modernize empirical demand analysis. The insights generated may also prove valuable for applied causal inference more broadly.
Collusion Detection with Graph Neural Networks
Oct 09, 2024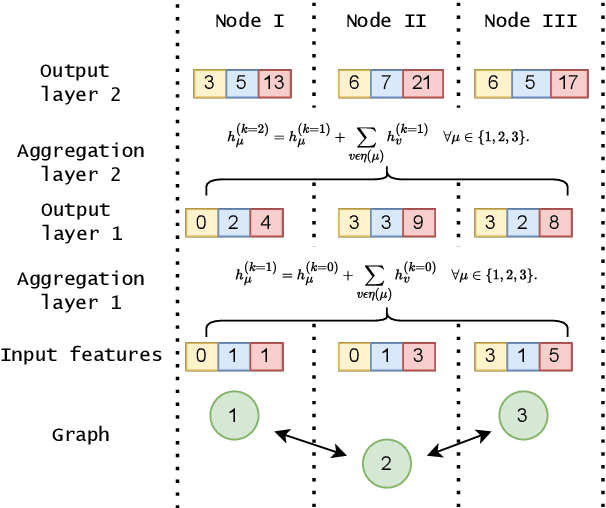

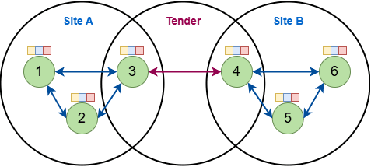

Collusion is a complex phenomenon in which companies secretly collaborate to engage in fraudulent practices. This paper presents an innovative methodology for detecting and predicting collusion patterns in different national markets using neural networks (NNs) and graph neural networks (GNNs). GNNs are particularly well suited to this task because they can exploit the inherent network structures present in collusion and many other economic problems. Our approach consists of two phases: In Phase I, we develop and train models on individual market datasets from Japan, the United States, two regions in Switzerland, Italy, and Brazil, focusing on predicting collusion in single markets. In Phase II, we extend the models' applicability through zero-shot learning, employing a transfer learning approach that can detect collusion in markets in which training data is unavailable. This phase also incorporates out-of-distribution (OOD) generalization to evaluate the models' performance on unseen datasets from other countries and regions. In our empirical study, we show that GNNs outperform NNs in detecting complex collusive patterns. This research contributes to the ongoing discourse on preventing collusion and optimizing detection methodologies, providing valuable guidance on the use of NNs and GNNs in economic applications to enhance market fairness and economic welfare.
Management Decisions in Manufacturing using Causal Machine Learning -- To Rework, or not to Rework?
Jun 17, 2024



In this paper, we present a data-driven model for estimating optimal rework policies in manufacturing systems. We consider a single production stage within a multistage, lot-based system that allows for optional rework steps. While the rework decision depends on an intermediate state of the lot and system, the final product inspection, and thus the assessment of the actual yield, is delayed until production is complete. Repair steps are applied uniformly to the lot, potentially improving some of the individual items while degrading others. The challenge is thus to balance potential yield improvement with the rework costs incurred. Given the inherently causal nature of this decision problem, we propose a causal model to estimate yield improvement. We apply methods from causal machine learning, in particular double/debiased machine learning (DML) techniques, to estimate conditional treatment effects from data and derive policies for rework decisions. We validate our decision model using real-world data from opto-electronic semiconductor manufacturing, achieving a yield improvement of 2 - 3% during the color-conversion process of white light-emitting diodes (LEDs).
Applied Causal Inference Powered by ML and AI
Mar 04, 2024



An introduction to the emerging fusion of machine learning and causal inference. The book presents ideas from classical structural equation models (SEMs) and their modern AI equivalent, directed acyclical graphs (DAGs) and structural causal models (SCMs), and covers Double/Debiased Machine Learning methods to do inference in such models using modern predictive tools.
Hyperparameter Tuning for Causal Inference with Double Machine Learning: A Simulation Study
Feb 07, 2024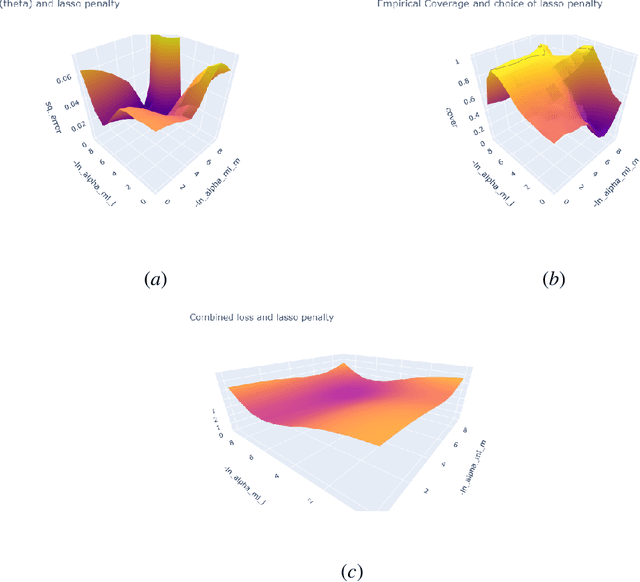

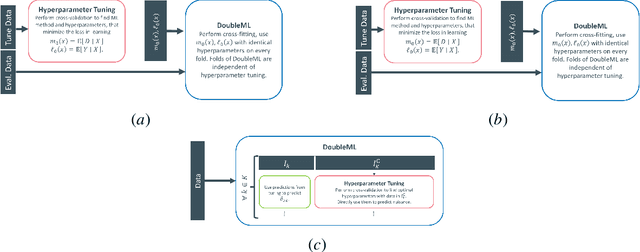
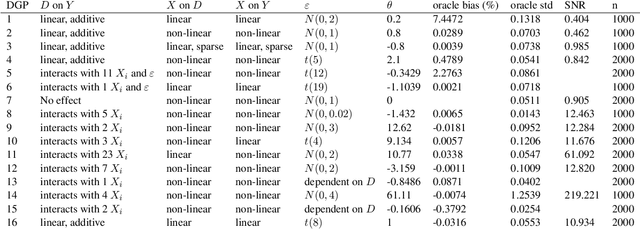
Proper hyperparameter tuning is essential for achieving optimal performance of modern machine learning (ML) methods in predictive tasks. While there is an extensive literature on tuning ML learners for prediction, there is only little guidance available on tuning ML learners for causal machine learning and how to select among different ML learners. In this paper, we empirically assess the relationship between the predictive performance of ML methods and the resulting causal estimation based on the Double Machine Learning (DML) approach by Chernozhukov et al. (2018). DML relies on estimating so-called nuisance parameters by treating them as supervised learning problems and using them as plug-in estimates to solve for the (causal) parameter. We conduct an extensive simulation study using data from the 2019 Atlantic Causal Inference Conference Data Challenge. We provide empirical insights on the role of hyperparameter tuning and other practical decisions for causal estimation with DML. First, we assess the importance of data splitting schemes for tuning ML learners within Double Machine Learning. Second, we investigate how the choice of ML methods and hyperparameters, including recent AutoML frameworks, impacts the estimation performance for a causal parameter of interest. Third, we assess to what extent the choice of a particular causal model, as characterized by incorporated parametric assumptions, can be based on predictive performance metrics.
DoubleMLDeep: Estimation of Causal Effects with Multimodal Data
Feb 01, 2024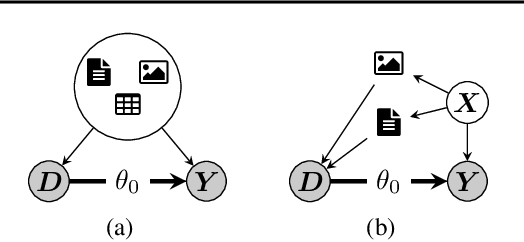
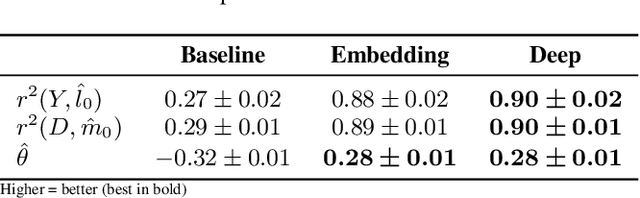
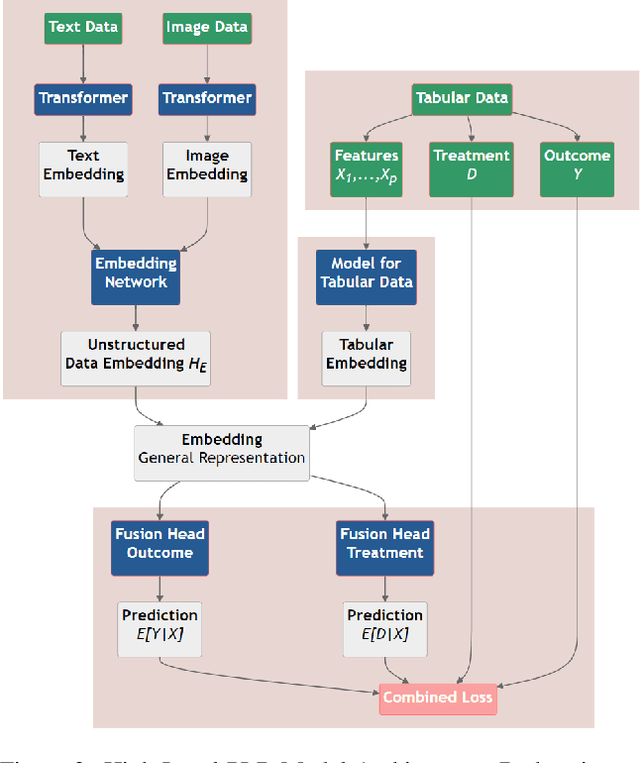
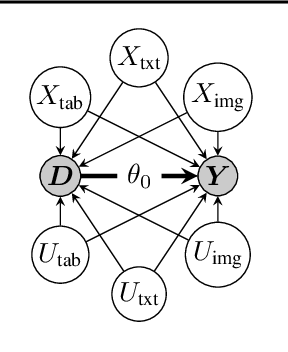
This paper explores the use of unstructured, multimodal data, namely text and images, in causal inference and treatment effect estimation. We propose a neural network architecture that is adapted to the double machine learning (DML) framework, specifically the partially linear model. An additional contribution of our paper is a new method to generate a semi-synthetic dataset which can be used to evaluate the performance of causal effect estimation in the presence of text and images as confounders. The proposed methods and architectures are evaluated on the semi-synthetic dataset and compared to standard approaches, highlighting the potential benefit of using text and images directly in causal studies. Our findings have implications for researchers and practitioners in economics, marketing, finance, medicine and data science in general who are interested in estimating causal quantities using non-traditional data.
Causally Learning an Optimal Rework Policy
Jun 07, 2023



In manufacturing, rework refers to an optional step of a production process which aims to eliminate errors or remedy products that do not meet the desired quality standards. Reworking a production lot involves repeating a previous production stage with adjustments to ensure that the final product meets the required specifications. While offering the chance to improve the yield and thus increase the revenue of a production lot, a rework step also incurs additional costs. Additionally, the rework of parts that already meet the target specifications may damage them and decrease the yield. In this paper, we apply double/debiased machine learning (DML) to estimate the conditional treatment effect of a rework step during the color conversion process in opto-electronic semiconductor manufacturing on the final product yield. We utilize the implementation DoubleML to develop policies for the rework of components and estimate their value empirically. From our causal machine learning analysis we derive implications for the coating of monochromatic LEDs with conversion layers.
Label Attention Network for sequential multi-label classification
Mar 01, 2023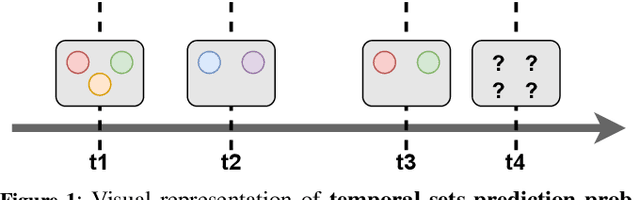
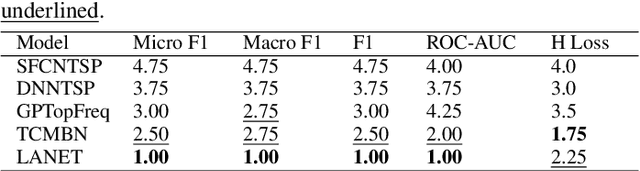
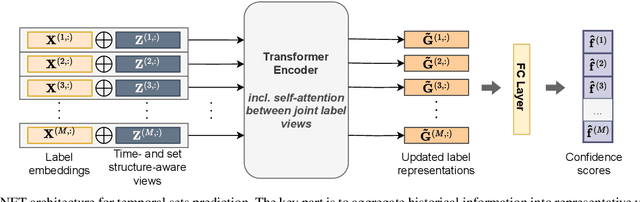
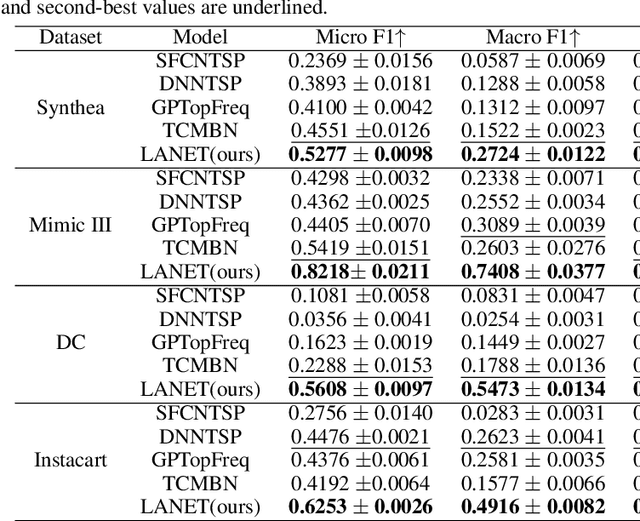
Multi-label classification is a natural problem statement for sequential data. We might be interested in the items of the next order by a customer, or types of financial transactions that will occur tomorrow. Most modern approaches focus on transformer architecture for multi-label classification, introducing self-attention for the elements of a sequence with each element being a multi-label vector and supplementary information. However, in this way we loose local information related to interconnections between particular labels. We propose instead to use a self-attention mechanism over labels preceding the predicted step. Conducted experiments suggest that such architecture improves the model performance and provides meaningful attention between labels. The metric such as micro-AUC of our label attention network is $0.9847$ compared to $0.7390$ for vanilla transformers benchmark.
Machine Learning for Financial Forecasting, Planning and Analysis: Recent Developments and Pitfalls
Jul 10, 2021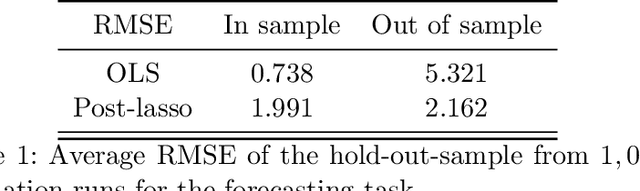
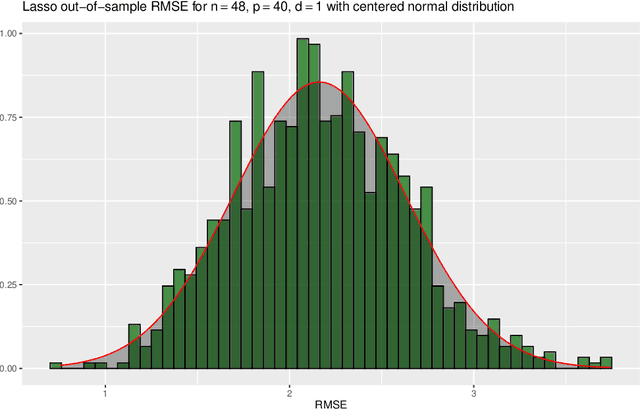

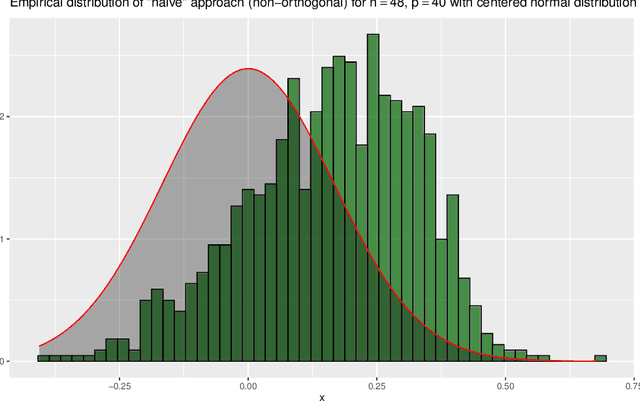
This article is an introduction to machine learning for financial forecasting, planning and analysis (FP\&A). Machine learning appears well suited to support FP\&A with the highly automated extraction of information from large amounts of data. However, because most traditional machine learning techniques focus on forecasting (prediction), we discuss the particular care that must be taken to avoid the pitfalls of using them for planning and resource allocation (causal inference). While the naive application of machine learning usually fails in this context, the recently developed double machine learning framework can address causal questions of interest. We review the current literature on machine learning in FP\&A and illustrate in a simulation study how machine learning can be used for both forecasting and planning. We also investigate how forecasting and planning improve as the number of data points increases.
DoubleML -- An Object-Oriented Implementation of Double Machine Learning in Python
Apr 07, 2021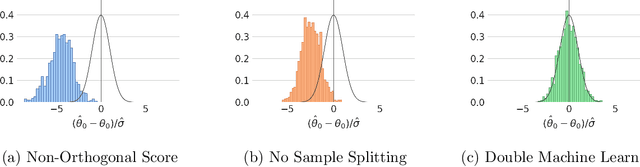
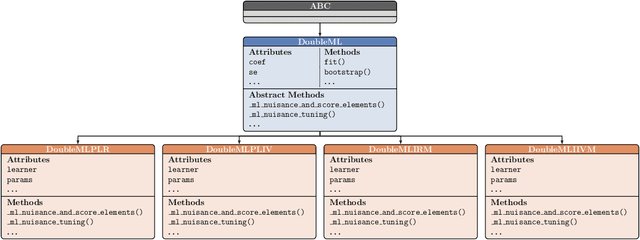
DoubleML is an open-source Python library implementing the double machine learning framework of Chernozhukov et al. (2018) for a variety of causal models. It contains functionalities for valid statistical inference on causal parameters when the estimation of nuisance parameters is based on machine learning methods. The object-oriented implementation of DoubleML provides a high flexibility in terms of model specifications and makes it easily extendable. The package is distributed under the MIT license and relies on core libraries from the scientific Python ecosystem: scikit-learn, numpy, pandas, scipy, statsmodels and joblib. Source code, documentation and an extensive user guide can be found at https://github.com/DoubleML/doubleml-for-py and https://docs.doubleml.org.