 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal explanations of outliers in systems with lagged time-dependencies
Feb 04, 2026Root-cause analysis in controlled time dependent systems poses a major challenge in applications. Especially energy systems are difficult to handle as they exhibit instantaneous as well as delayed effects and if equipped with storage, do have a memory. In this paper we adapt the causal root-cause analysis method of Budhathoki et al. [2022] to general time-dependent systems, as it can be regarded as a strictly causal definition of the term "root-cause". Particularly, we discuss two truncation approaches to handle the infinite dependency graphs present in time-dependent systems. While one leaves the causal mechanisms intact, the other approximates the mechanisms at the start nodes. The effectiveness of the different approaches is benchmarked using a challenging data generation process inspired by a problem in factory energy management: the avoidance of peaks in the power consumption. We show that given enough lags our extension is able to localize the root-causes in the feature and time domain. Further the effect of mechanism approximation is discussed.
Calibration Strategies for Robust Causal Estimation: Theoretical and Empirical Insights on Propensity Score Based Estimators
Mar 21, 2025The partitioning of data for estimation and calibration critically impacts the performance of propensity score based estimators like inverse probability weighting (IPW) and double/debiased machine learning (DML) frameworks. We extend recent advances in calibration techniques for propensity score estimation, improving the robustness of propensity scores in challenging settings such as limited overlap, small sample sizes, or unbalanced data. Our contributions are twofold: First, we provide a theoretical analysis of the properties of calibrated estimators in the context of DML. To this end, we refine existing calibration frameworks for propensity score models, with a particular emphasis on the role of sample-splitting schemes in ensuring valid causal inference. Second, through extensive simulations, we show that calibration reduces variance of inverse-based propensity score estimators while also mitigating bias in IPW, even in small-sample regimes. Notably, calibration improves stability for flexible learners (e.g., gradient boosting) while preserving the doubly robust properties of DML. A key insight is that, even when methods perform well without calibration, incorporating a calibration step does not degrade performance, provided that an appropriate sample-splitting approach is chosen.
Adventures in Demand Analysis Using AI
Dec 31, 2024

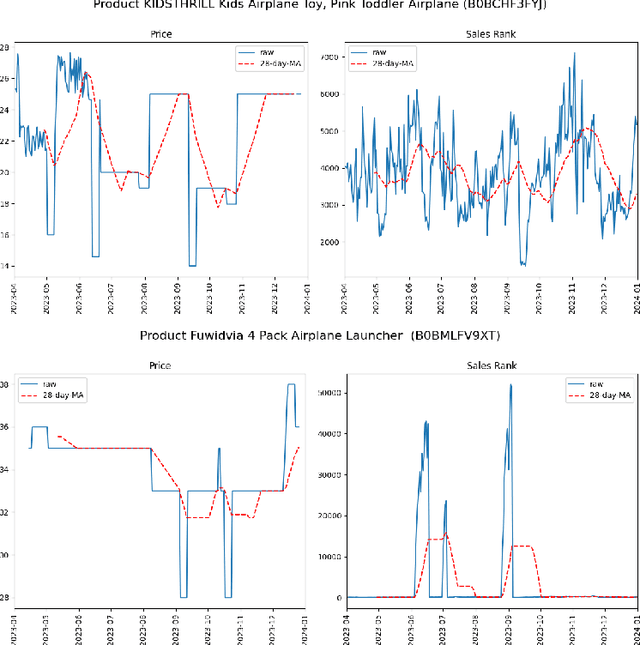

This paper advances empirical demand analysis by integrating multimodal product representations derived from artificial intelligence (AI). Using a detailed dataset of toy cars on \textit{Amazon.com}, we combine text descriptions, images, and tabular covariates to represent each product using transformer-based embedding models. These embeddings capture nuanced attributes, such as quality, branding, and visual characteristics, that traditional methods often struggle to summarize. Moreover, we fine-tune these embeddings for causal inference tasks. We show that the resulting embeddings substantially improve the predictive accuracy of sales ranks and prices and that they lead to more credible causal estimates of price elasticity. Notably, we uncover strong heterogeneity in price elasticity driven by these product-specific features. Our findings illustrate that AI-driven representations can enrich and modernize empirical demand analysis. The insights generated may also prove valuable for applied causal inference more broadly.
Management Decisions in Manufacturing using Causal Machine Learning -- To Rework, or not to Rework?
Jun 17, 2024



In this paper, we present a data-driven model for estimating optimal rework policies in manufacturing systems. We consider a single production stage within a multistage, lot-based system that allows for optional rework steps. While the rework decision depends on an intermediate state of the lot and system, the final product inspection, and thus the assessment of the actual yield, is delayed until production is complete. Repair steps are applied uniformly to the lot, potentially improving some of the individual items while degrading others. The challenge is thus to balance potential yield improvement with the rework costs incurred. Given the inherently causal nature of this decision problem, we propose a causal model to estimate yield improvement. We apply methods from causal machine learning, in particular double/debiased machine learning (DML) techniques, to estimate conditional treatment effects from data and derive policies for rework decisions. We validate our decision model using real-world data from opto-electronic semiconductor manufacturing, achieving a yield improvement of 2 - 3% during the color-conversion process of white light-emitting diodes (LEDs).
Hyperparameter Tuning for Causal Inference with Double Machine Learning: A Simulation Study
Feb 07, 2024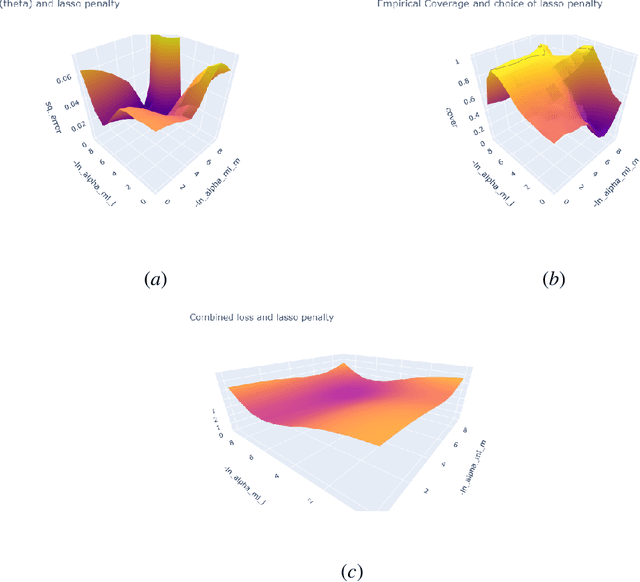

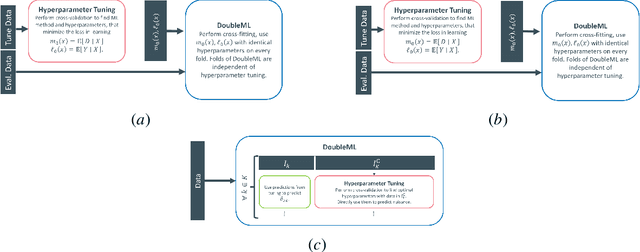
Proper hyperparameter tuning is essential for achieving optimal performance of modern machine learning (ML) methods in predictive tasks. While there is an extensive literature on tuning ML learners for prediction, there is only little guidance available on tuning ML learners for causal machine learning and how to select among different ML learners. In this paper, we empirically assess the relationship between the predictive performance of ML methods and the resulting causal estimation based on the Double Machine Learning (DML) approach by Chernozhukov et al. (2018). DML relies on estimating so-called nuisance parameters by treating them as supervised learning problems and using them as plug-in estimates to solve for the (causal) parameter. We conduct an extensive simulation study using data from the 2019 Atlantic Causal Inference Conference Data Challenge. We provide empirical insights on the role of hyperparameter tuning and other practical decisions for causal estimation with DML. First, we assess the importance of data splitting schemes for tuning ML learners within Double Machine Learning. Second, we investigate how the choice of ML methods and hyperparameters, including recent AutoML frameworks, impacts the estimation performance for a causal parameter of interest. Third, we assess to what extent the choice of a particular causal model, as characterized by incorporated parametric assumptions, can be based on predictive performance metrics.
DoubleMLDeep: Estimation of Causal Effects with Multimodal Data
Feb 01, 2024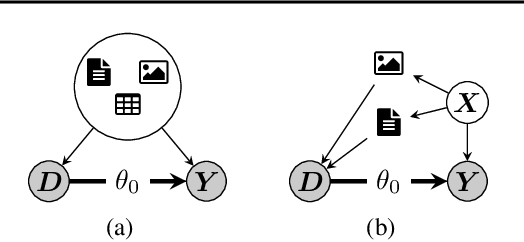
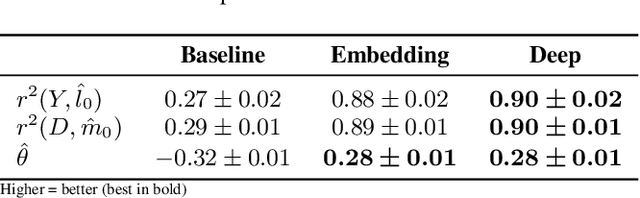
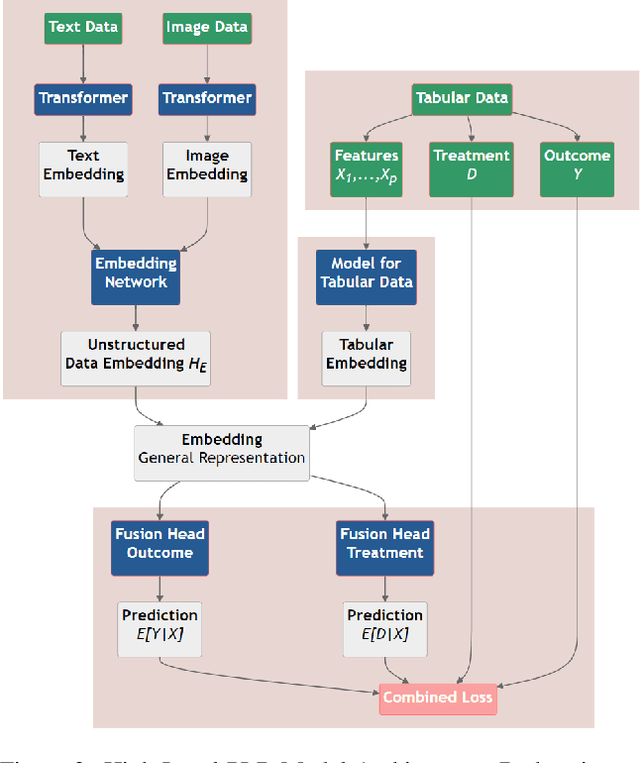
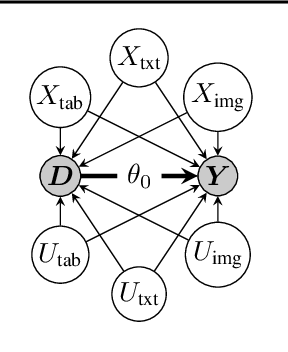
This paper explores the use of unstructured, multimodal data, namely text and images, in causal inference and treatment effect estimation. We propose a neural network architecture that is adapted to the double machine learning (DML) framework, specifically the partially linear model. An additional contribution of our paper is a new method to generate a semi-synthetic dataset which can be used to evaluate the performance of causal effect estimation in the presence of text and images as confounders. The proposed methods and architectures are evaluated on the semi-synthetic dataset and compared to standard approaches, highlighting the potential benefit of using text and images directly in causal studies. Our findings have implications for researchers and practitioners in economics, marketing, finance, medicine and data science in general who are interested in estimating causal quantities using non-traditional data.
Causally Learning an Optimal Rework Policy
Jun 07, 2023



In manufacturing, rework refers to an optional step of a production process which aims to eliminate errors or remedy products that do not meet the desired quality standards. Reworking a production lot involves repeating a previous production stage with adjustments to ensure that the final product meets the required specifications. While offering the chance to improve the yield and thus increase the revenue of a production lot, a rework step also incurs additional costs. Additionally, the rework of parts that already meet the target specifications may damage them and decrease the yield. In this paper, we apply double/debiased machine learning (DML) to estimate the conditional treatment effect of a rework step during the color conversion process in opto-electronic semiconductor manufacturing on the final product yield. We utilize the implementation DoubleML to develop policies for the rework of components and estimate their value empirically. From our causal machine learning analysis we derive implications for the coating of monochromatic LEDs with conversion layers.
Uniform Inference in High-Dimensional Generalized Additive Models
Apr 03, 2020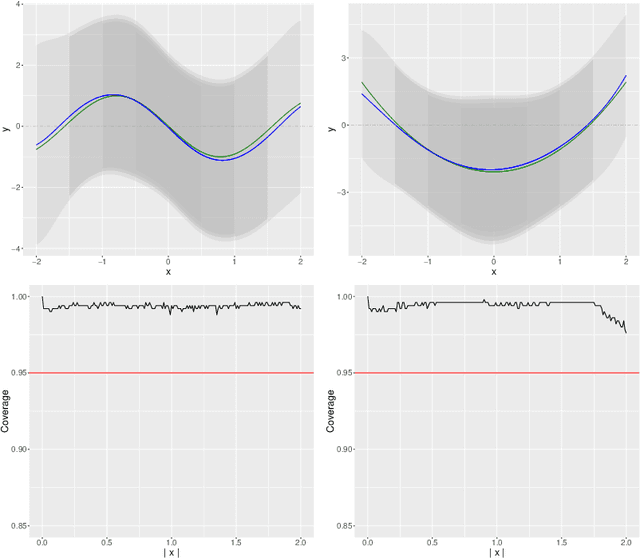
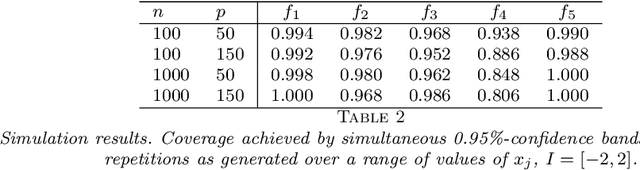

We develop a method for uniform valid confidence bands of a nonparametric component $f_1$ in the general additive model $Y=f_1(X_1)+\ldots + f_p(X_p) + \varepsilon$ in a high-dimensional setting. We employ sieve estimation and embed it in a high-dimensional Z-estimation framework allowing us to construct uniformly valid confidence bands for the first component $f_1$. As usual in high-dimensional settings where the number of regressors $p$ may increase with sample, a sparsity assumption is critical for the analysis. We also run simulations studies which show that our proposed method gives reliable results concerning the estimation properties and coverage properties even in small samples. Finally, we illustrate our procedure with an empirical application demonstrating the implementation and the use of the proposed method in practice.
Uniform Inference in High-Dimensional Gaussian Graphical Models
Aug 30, 2018


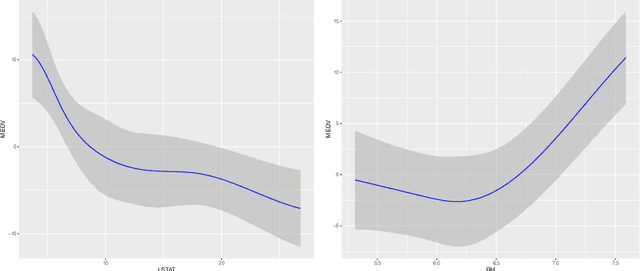
Graphical models have become a very popular tool for representing dependencies within a large set of variables and are key for representing causal structures. We provide results for uniform inference on high-dimensional graphical models with the number of target parameters being possible much larger than sample size. This is in particular important when certain features or structures of a causal model should be recovered. Our results highlight how in high-dimensional settings graphical models can be estimated and recovered with modern machine learning methods in complex data sets. We also demonstrate in simulation study that our procedure has good small sample properties.
Transformation Models in High-Dimensions
Dec 20, 2017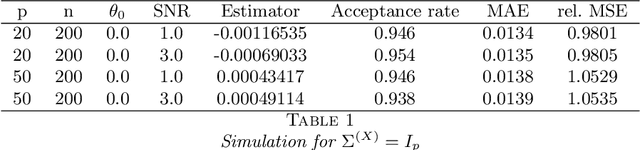
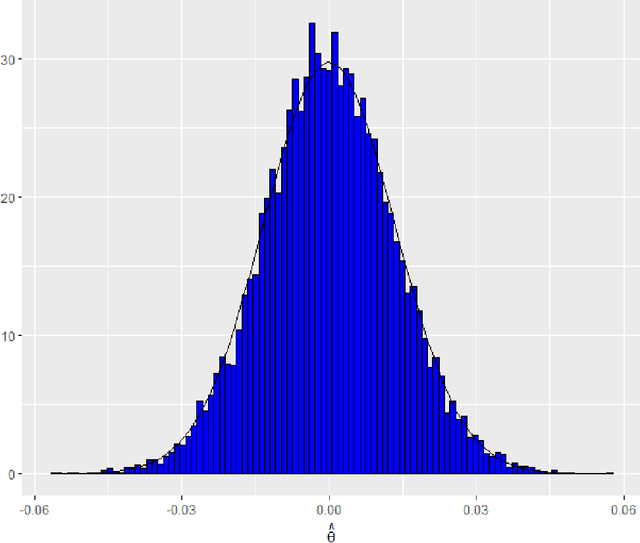

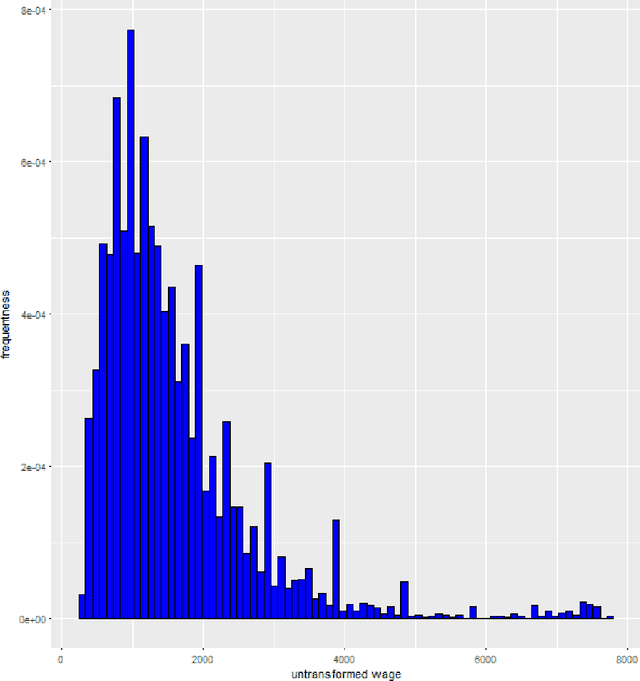
Transformation models are a very important tool for applied statisticians and econometricians. In many applications, the dependent variable is transformed so that homogeneity or normal distribution of the error holds. In this paper, we analyze transformation models in a high-dimensional setting, where the set of potential covariates is large. We propose an estimator for the transformation parameter and we show that it is asymptotically normally distributed using an orthogonalized moment condition where the nuisance functions depend on the target parameter. In a simulation study, we show that the proposed estimator works well in small samples. A common practice in labor economics is to transform wage with the log-function. In this study, we test if this transformation holds in CPS data from the United States.