 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Kernel-based Conditional Independence test with Application to Causal Discovery
May 16, 2025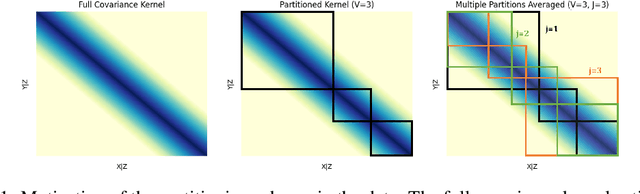
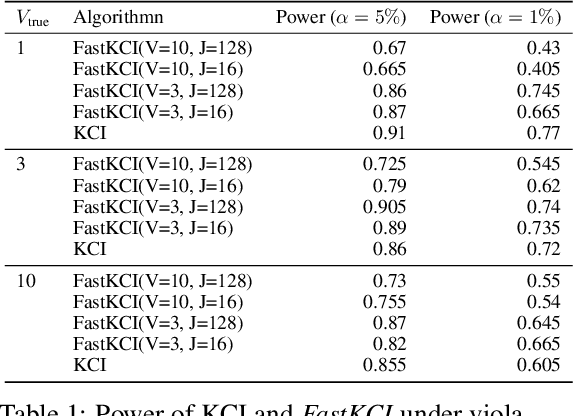
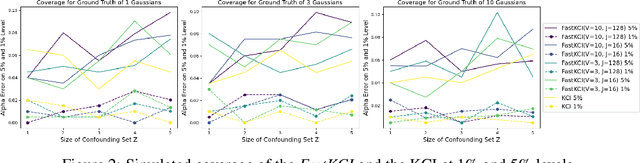
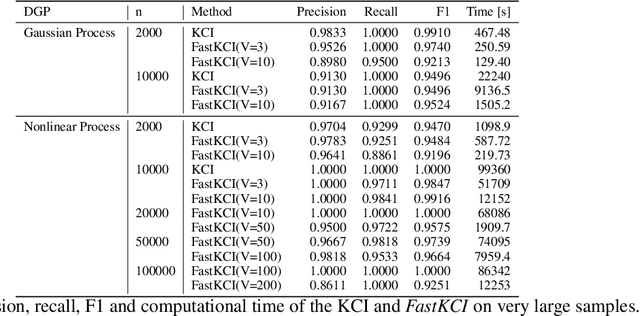
Kernel-based conditional independence (KCI) testing is a powerful nonparametric method commonly employed in causal discovery tasks. Despite its flexibility and statistical reliability, cubic computational complexity limits its application to large datasets. To address this computational bottleneck, we propose \textit{FastKCI}, a scalable and parallelizable kernel-based conditional independence test that utilizes a mixture-of-experts approach inspired by embarrassingly parallel inference techniques for Gaussian processes. By partitioning the dataset based on a Gaussian mixture model over the conditioning variables, FastKCI conducts local KCI tests in parallel, aggregating the results using an importance-weighted sampling scheme. Experiments on synthetic datasets and benchmarks on real-world production data validate that FastKCI maintains the statistical power of the original KCI test while achieving substantial computational speedups. FastKCI thus represents a practical and efficient solution for conditional independence testing in causal inference on large-scale data.
Management Decisions in Manufacturing using Causal Machine Learning -- To Rework, or not to Rework?
Jun 17, 2024



In this paper, we present a data-driven model for estimating optimal rework policies in manufacturing systems. We consider a single production stage within a multistage, lot-based system that allows for optional rework steps. While the rework decision depends on an intermediate state of the lot and system, the final product inspection, and thus the assessment of the actual yield, is delayed until production is complete. Repair steps are applied uniformly to the lot, potentially improving some of the individual items while degrading others. The challenge is thus to balance potential yield improvement with the rework costs incurred. Given the inherently causal nature of this decision problem, we propose a causal model to estimate yield improvement. We apply methods from causal machine learning, in particular double/debiased machine learning (DML) techniques, to estimate conditional treatment effects from data and derive policies for rework decisions. We validate our decision model using real-world data from opto-electronic semiconductor manufacturing, achieving a yield improvement of 2 - 3% during the color-conversion process of white light-emitting diodes (LEDs).
Hyperparameter Tuning for Causal Inference with Double Machine Learning: A Simulation Study
Feb 07, 2024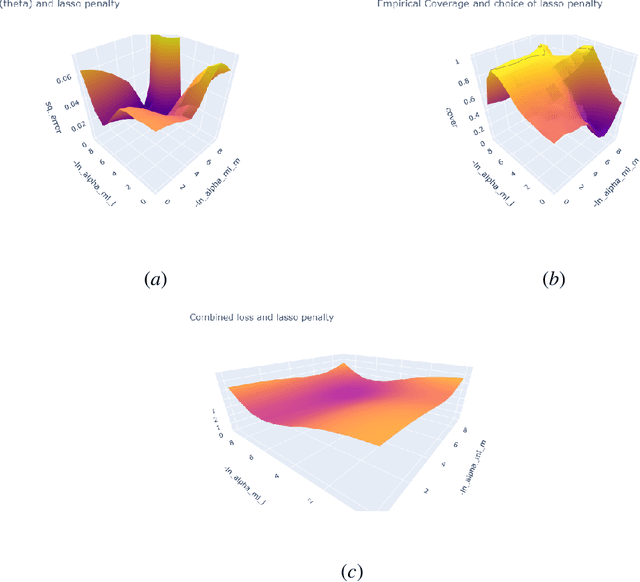

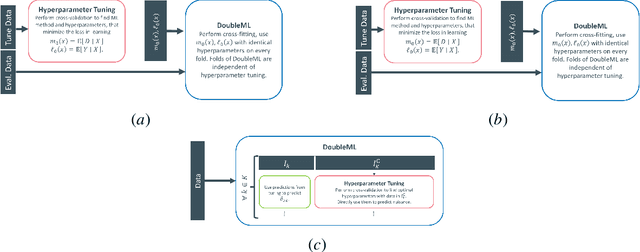
Proper hyperparameter tuning is essential for achieving optimal performance of modern machine learning (ML) methods in predictive tasks. While there is an extensive literature on tuning ML learners for prediction, there is only little guidance available on tuning ML learners for causal machine learning and how to select among different ML learners. In this paper, we empirically assess the relationship between the predictive performance of ML methods and the resulting causal estimation based on the Double Machine Learning (DML) approach by Chernozhukov et al. (2018). DML relies on estimating so-called nuisance parameters by treating them as supervised learning problems and using them as plug-in estimates to solve for the (causal) parameter. We conduct an extensive simulation study using data from the 2019 Atlantic Causal Inference Conference Data Challenge. We provide empirical insights on the role of hyperparameter tuning and other practical decisions for causal estimation with DML. First, we assess the importance of data splitting schemes for tuning ML learners within Double Machine Learning. Second, we investigate how the choice of ML methods and hyperparameters, including recent AutoML frameworks, impacts the estimation performance for a causal parameter of interest. Third, we assess to what extent the choice of a particular causal model, as characterized by incorporated parametric assumptions, can be based on predictive performance metrics.
Causally Learning an Optimal Rework Policy
Jun 07, 2023



In manufacturing, rework refers to an optional step of a production process which aims to eliminate errors or remedy products that do not meet the desired quality standards. Reworking a production lot involves repeating a previous production stage with adjustments to ensure that the final product meets the required specifications. While offering the chance to improve the yield and thus increase the revenue of a production lot, a rework step also incurs additional costs. Additionally, the rework of parts that already meet the target specifications may damage them and decrease the yield. In this paper, we apply double/debiased machine learning (DML) to estimate the conditional treatment effect of a rework step during the color conversion process in opto-electronic semiconductor manufacturing on the final product yield. We utilize the implementation DoubleML to develop policies for the rework of components and estimate their value empirically. From our causal machine learning analysis we derive implications for the coating of monochromatic LEDs with conversion layers.