 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
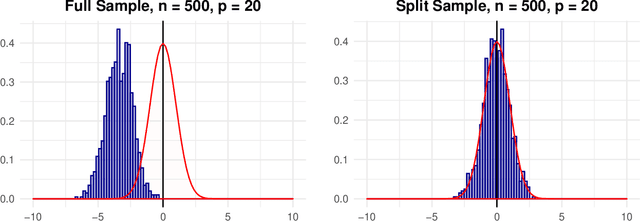
Add to EdgeCalibration Strategies for Robust Causal Estimation: Theoretical and Empirical Insights on Propensity Score Based Estimators
Mar 21, 2025The partitioning of data for estimation and calibration critically impacts the performance of propensity score based estimators like inverse probability weighting (IPW) and double/debiased machine learning (DML) frameworks. We extend recent advances in calibration techniques for propensity score estimation, improving the robustness of propensity scores in challenging settings such as limited overlap, small sample sizes, or unbalanced data. Our contributions are twofold: First, we provide a theoretical analysis of the properties of calibrated estimators in the context of DML. To this end, we refine existing calibration frameworks for propensity score models, with a particular emphasis on the role of sample-splitting schemes in ensuring valid causal inference. Second, through extensive simulations, we show that calibration reduces variance of inverse-based propensity score estimators while also mitigating bias in IPW, even in small-sample regimes. Notably, calibration improves stability for flexible learners (e.g., gradient boosting) while preserving the doubly robust properties of DML. A key insight is that, even when methods perform well without calibration, incorporating a calibration step does not degrade performance, provided that an appropriate sample-splitting approach is chosen.
Adventures in Demand Analysis Using AI
Dec 31, 2024

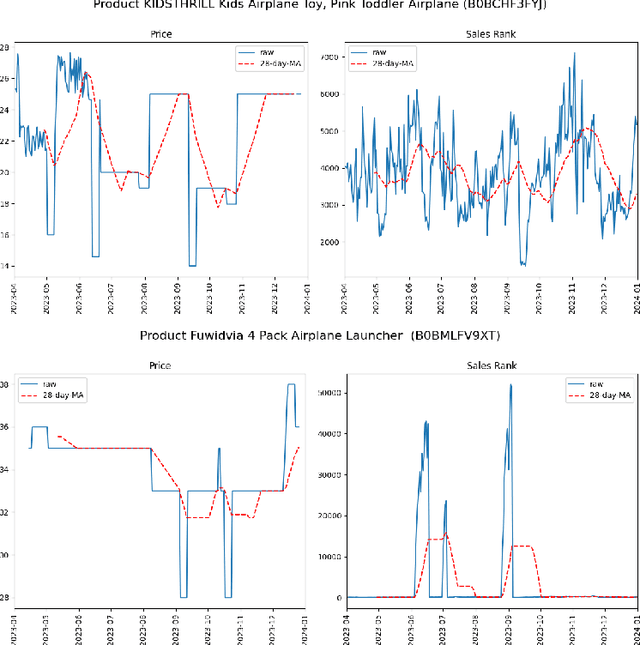

This paper advances empirical demand analysis by integrating multimodal product representations derived from artificial intelligence (AI). Using a detailed dataset of toy cars on \textit{Amazon.com}, we combine text descriptions, images, and tabular covariates to represent each product using transformer-based embedding models. These embeddings capture nuanced attributes, such as quality, branding, and visual characteristics, that traditional methods often struggle to summarize. Moreover, we fine-tune these embeddings for causal inference tasks. We show that the resulting embeddings substantially improve the predictive accuracy of sales ranks and prices and that they lead to more credible causal estimates of price elasticity. Notably, we uncover strong heterogeneity in price elasticity driven by these product-specific features. Our findings illustrate that AI-driven representations can enrich and modernize empirical demand analysis. The insights generated may also prove valuable for applied causal inference more broadly.
Hyperparameter Tuning for Causal Inference with Double Machine Learning: A Simulation Study
Feb 07, 2024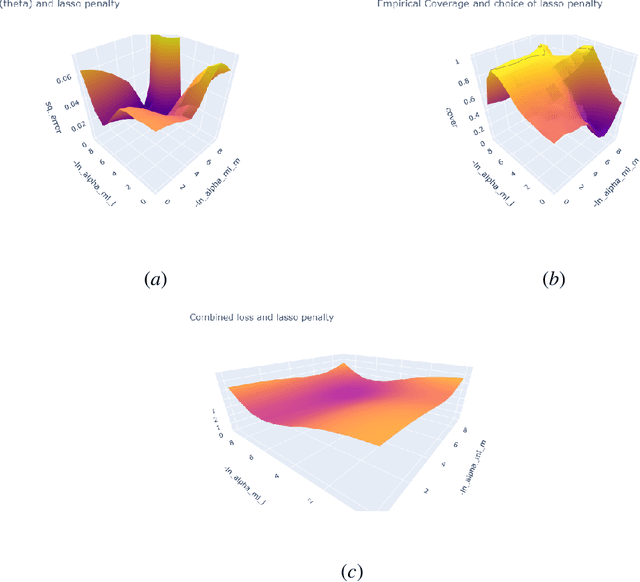

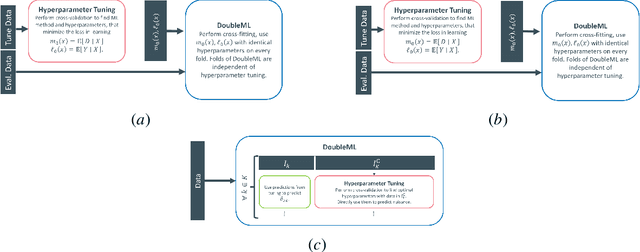
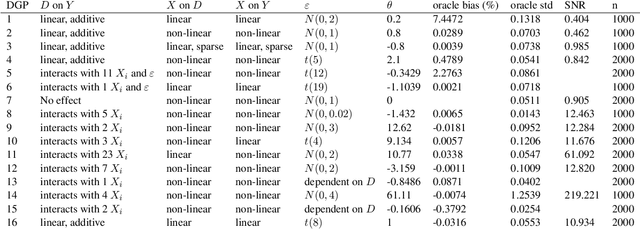
Proper hyperparameter tuning is essential for achieving optimal performance of modern machine learning (ML) methods in predictive tasks. While there is an extensive literature on tuning ML learners for prediction, there is only little guidance available on tuning ML learners for causal machine learning and how to select among different ML learners. In this paper, we empirically assess the relationship between the predictive performance of ML methods and the resulting causal estimation based on the Double Machine Learning (DML) approach by Chernozhukov et al. (2018). DML relies on estimating so-called nuisance parameters by treating them as supervised learning problems and using them as plug-in estimates to solve for the (causal) parameter. We conduct an extensive simulation study using data from the 2019 Atlantic Causal Inference Conference Data Challenge. We provide empirical insights on the role of hyperparameter tuning and other practical decisions for causal estimation with DML. First, we assess the importance of data splitting schemes for tuning ML learners within Double Machine Learning. Second, we investigate how the choice of ML methods and hyperparameters, including recent AutoML frameworks, impacts the estimation performance for a causal parameter of interest. Third, we assess to what extent the choice of a particular causal model, as characterized by incorporated parametric assumptions, can be based on predictive performance metrics.
DoubleMLDeep: Estimation of Causal Effects with Multimodal Data
Feb 01, 2024
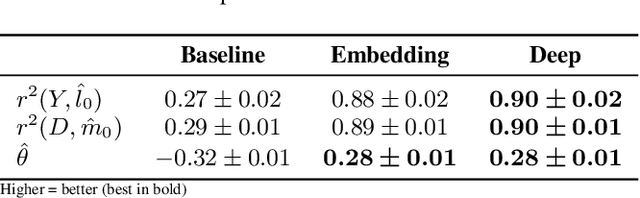
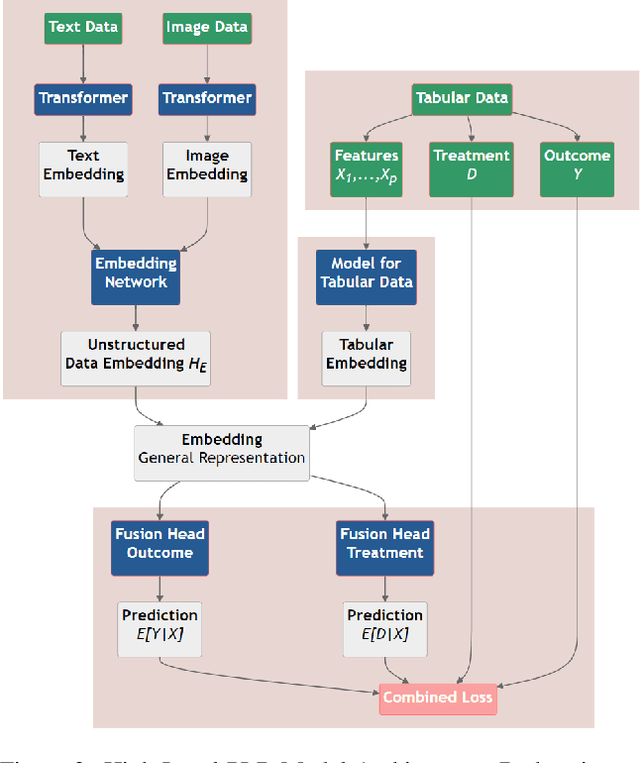
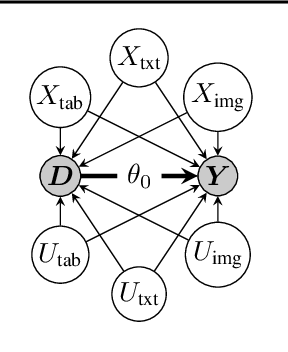
This paper explores the use of unstructured, multimodal data, namely text and images, in causal inference and treatment effect estimation. We propose a neural network architecture that is adapted to the double machine learning (DML) framework, specifically the partially linear model. An additional contribution of our paper is a new method to generate a semi-synthetic dataset which can be used to evaluate the performance of causal effect estimation in the presence of text and images as confounders. The proposed methods and architectures are evaluated on the semi-synthetic dataset and compared to standard approaches, highlighting the potential benefit of using text and images directly in causal studies. Our findings have implications for researchers and practitioners in economics, marketing, finance, medicine and data science in general who are interested in estimating causal quantities using non-traditional data.
DoubleML -- An Object-Oriented Implementation of Double Machine Learning in Python
Apr 07, 2021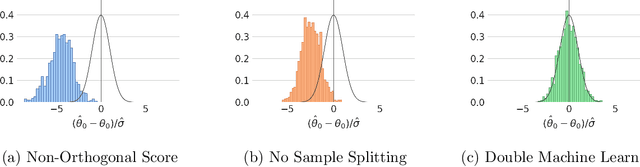
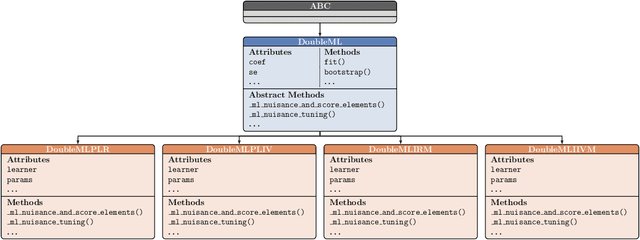
DoubleML is an open-source Python library implementing the double machine learning framework of Chernozhukov et al. (2018) for a variety of causal models. It contains functionalities for valid statistical inference on causal parameters when the estimation of nuisance parameters is based on machine learning methods. The object-oriented implementation of DoubleML provides a high flexibility in terms of model specifications and makes it easily extendable. The package is distributed under the MIT license and relies on core libraries from the scientific Python ecosystem: scikit-learn, numpy, pandas, scipy, statsmodels and joblib. Source code, documentation and an extensive user guide can be found at https://github.com/DoubleML/doubleml-for-py and https://docs.doubleml.org.
DoubleML -- An Object-Oriented Implementation of Double Machine Learning in R
Mar 17, 2021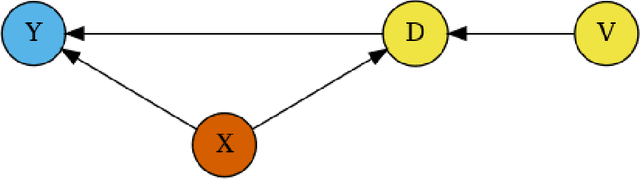
The R package DoubleML implements the double/debiased machine learning framework of Chernozhukov et al. (2018). It provides functionalities to estimate parameters in causal models based on machine learning methods. The double machine learning framework consist of three key ingredients: Neyman orthogonality, high-quality machine learning estimation and sample splitting. Estimation of nuisance components can be performed by various state-of-the-art machine learning methods that are available in the mlr3 ecosystem. DoubleML makes it possible to perform inference in a variety of causal models, including partially linear and interactive regression models and their extensions to instrumental variable estimation. The object-oriented implementation of DoubleML enables a high flexibility for the model specification and makes it easily extendable. This paper serves as an introduction to the double machine learning framework and the R package DoubleML. In reproducible code examples with simulated and real data sets, we demonstrate how DoubleML users can perform valid inference based on machine learning methods.
Uniform Inference in High-Dimensional Generalized Additive Models
Apr 03, 2020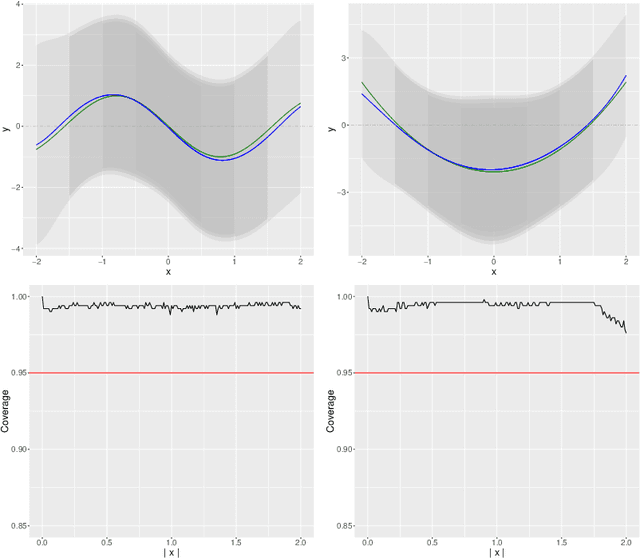
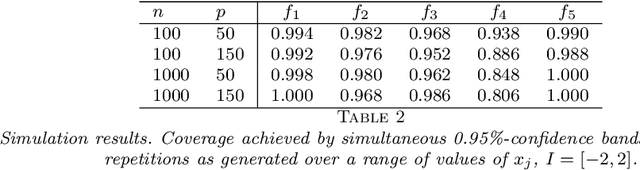
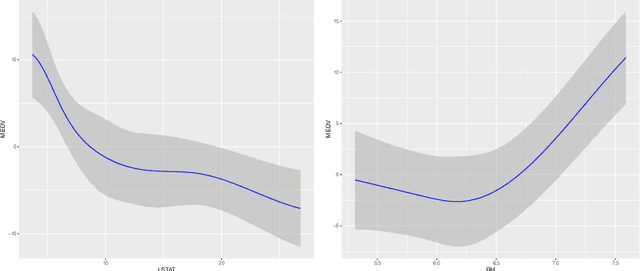

We develop a method for uniform valid confidence bands of a nonparametric component $f_1$ in the general additive model $Y=f_1(X_1)+\ldots + f_p(X_p) + \varepsilon$ in a high-dimensional setting. We employ sieve estimation and embed it in a high-dimensional Z-estimation framework allowing us to construct uniformly valid confidence bands for the first component $f_1$. As usual in high-dimensional settings where the number of regressors $p$ may increase with sample, a sparsity assumption is critical for the analysis. We also run simulations studies which show that our proposed method gives reliable results concerning the estimation properties and coverage properties even in small samples. Finally, we illustrate our procedure with an empirical application demonstrating the implementation and the use of the proposed method in practice.
Closing the U.S. gender wage gap requires understanding its heterogeneity
Dec 11, 2018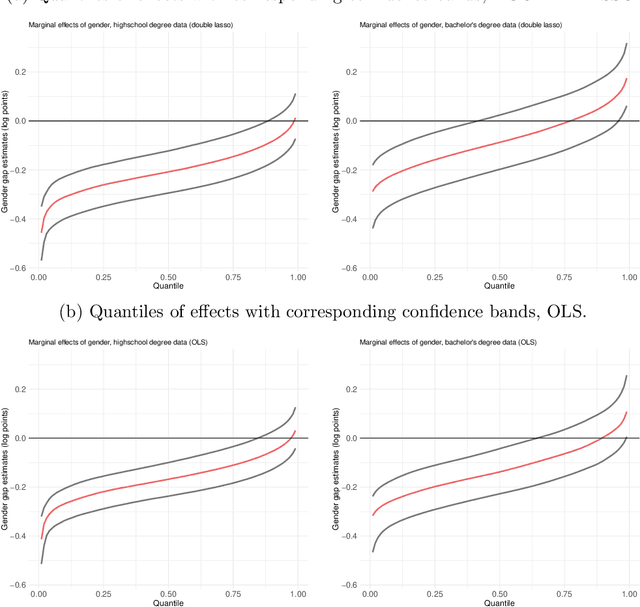
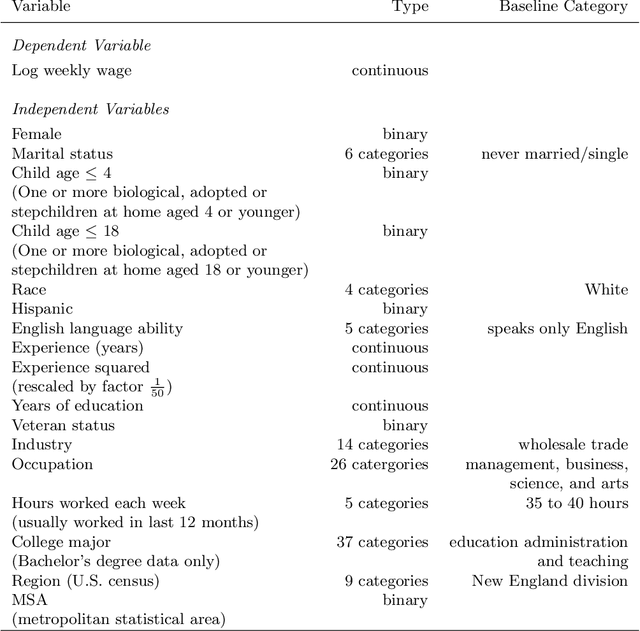
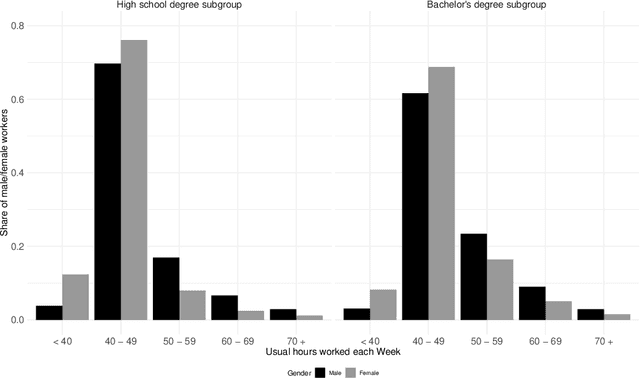
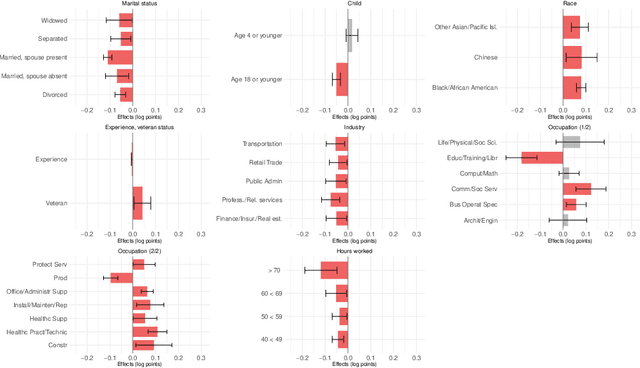
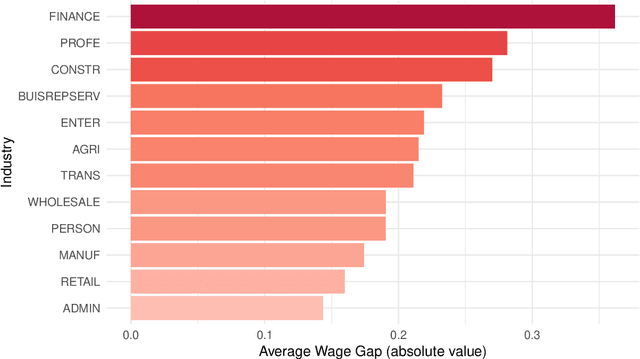
In 2016, the majority of full-time employed women in the U.S. earned significantly less than comparable men. The extent to which women were affected by gender inequality in earnings, however, depended greatly on socio-economic characteristics, such as marital status or educational attainment. In this paper, we analyzed data from the 2016 American Community Survey using a high-dimensional wage regression and applying double lasso to quantify heterogeneity in the gender wage gap. We found that the gap varied substantially across women and was driven primarily by marital status, having children at home, race, occupation, industry, and educational attainment. We recommend that policy makers use these insights to design policies that will reduce discrimination and unequal pay more effectively.
Valid Simultaneous Inference in High-Dimensional Settings (with the hdm package for R)
Sep 13, 2018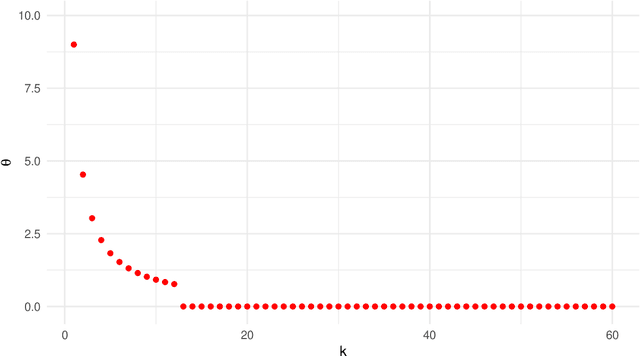
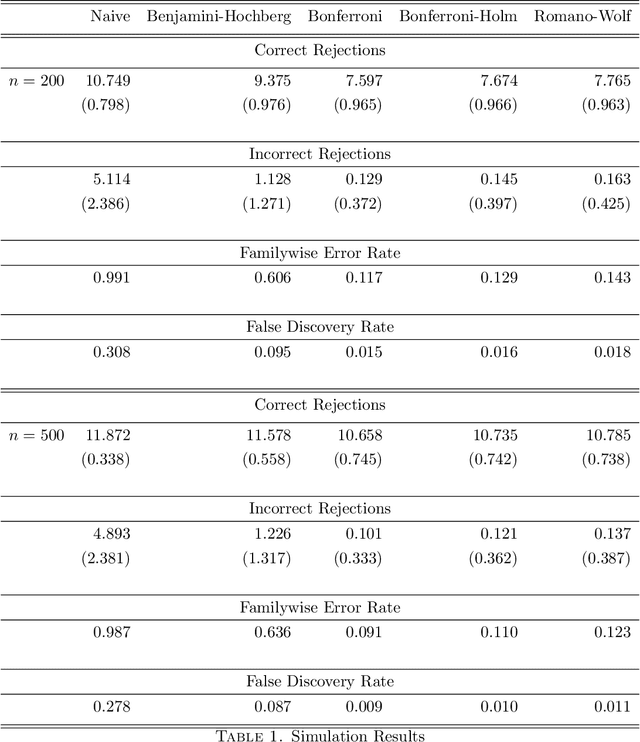
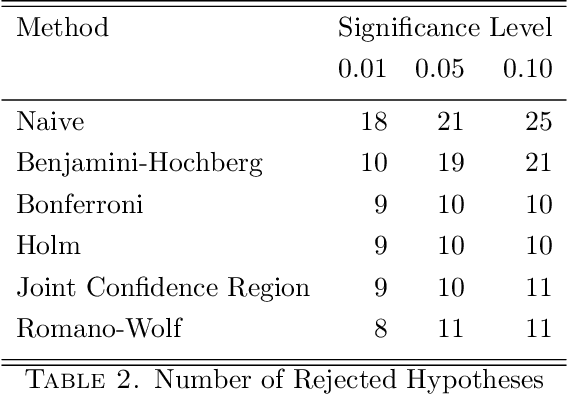
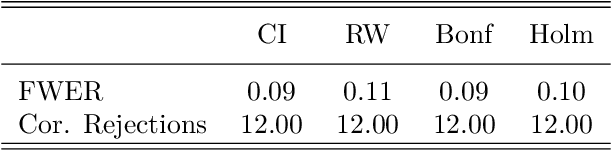
Due to the increasing availability of high-dimensional empirical applications in many research disciplines, valid simultaneous inference becomes more and more important. For instance, high-dimensional settings might arise in economic studies due to very rich data sets with many potential covariates or in the analysis of treatment heterogeneities. Also the evaluation of potentially more complicated (non-linear) functional forms of the regression relationship leads to many potential variables for which simultaneous inferential statements might be of interest. Here we provide a review of classical and modern methods for simultaneous inference in (high-dimensional) settings and illustrate their use by a case study using the R package hdm. The R package hdm implements valid joint powerful and efficient hypothesis tests for a potentially large number of coeffcients as well as the construction of simultaneous confidence intervals and, therefore, provides useful methods to perform valid post-selection inference based on the LASSO.