 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubleML -- An Object-Oriented Implementation of Double Machine Learning in Python
Apr 07, 2021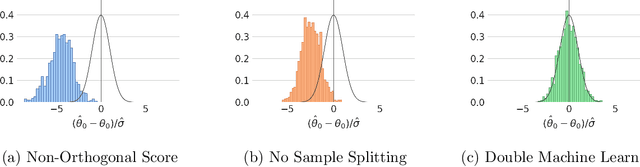
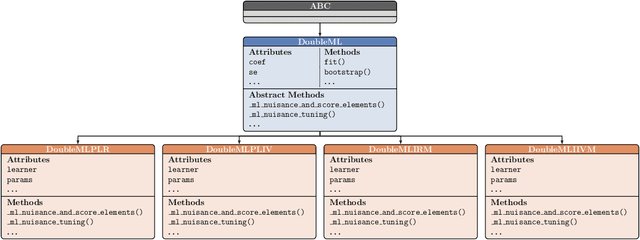
DoubleML is an open-source Python library implementing the double machine learning framework of Chernozhukov et al. (2018) for a variety of causal models. It contains functionalities for valid statistical inference on causal parameters when the estimation of nuisance parameters is based on machine learning methods. The object-oriented implementation of DoubleML provides a high flexibility in terms of model specifications and makes it easily extendable. The package is distributed under the MIT license and relies on core libraries from the scientific Python ecosystem: scikit-learn, numpy, pandas, scipy, statsmodels and joblib. Source code, documentation and an extensive user guide can be found at https://github.com/DoubleML/doubleml-for-py and https://docs.doubleml.org.
DoubleML -- An Object-Oriented Implementation of Double Machine Learning in R
Mar 17, 2021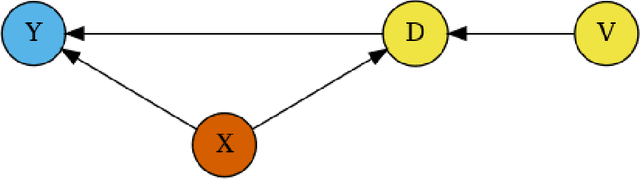
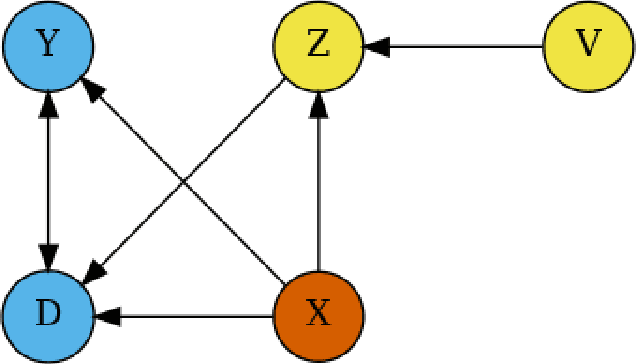
The R package DoubleML implements the double/debiased machine learning framework of Chernozhukov et al. (2018). It provides functionalities to estimate parameters in causal models based on machine learning methods. The double machine learning framework consist of three key ingredients: Neyman orthogonality, high-quality machine learning estimation and sample splitting. Estimation of nuisance components can be performed by various state-of-the-art machine learning methods that are available in the mlr3 ecosystem. DoubleML makes it possible to perform inference in a variety of causal models, including partially linear and interactive regression models and their extensions to instrumental variable estimation. The object-oriented implementation of DoubleML enables a high flexibility for the model specification and makes it easily extendable. This paper serves as an introduction to the double machine learning framework and the R package DoubleML. In reproducible code examples with simulated and real data sets, we demonstrate how DoubleML users can perform valid inference based on machine learning methods.
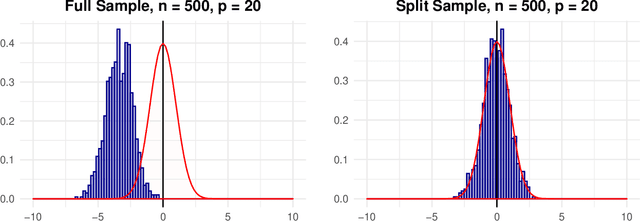
Distributed Double Machine Learning with a Serverless Architecture
Jan 11, 2021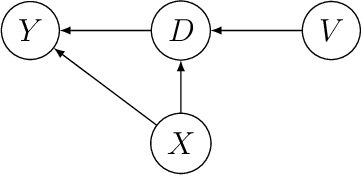
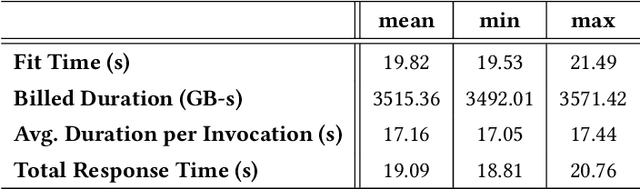

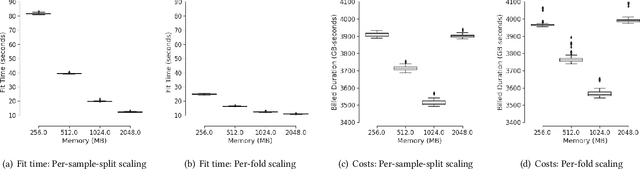
Serverless cloud computing is predicted to be the dominating and default architecture of cloud computing in the coming decade (Berkley View on Serverless Computing, 2019). In this paper we explore serverless cloud computing for double machine learning. Being based on repeated cross-fitting, double machine learning is particularly well suited to exploit the enormous elasticity of serverless computing. It allows to get fast on-demand estimations without additional cloud maintenance effort. We provide a prototype implementation DoubleML-Serverless written in Python that implements the estimation of double machine learning models with the serverless computing platform AWS Lambda and demonstrate its utility with a case study.