 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManagement Decisions in Manufacturing using Causal Machine Learning -- To Rework, or not to Rework?
Jun 17, 2024



In this paper, we present a data-driven model for estimating optimal rework policies in manufacturing systems. We consider a single production stage within a multistage, lot-based system that allows for optional rework steps. While the rework decision depends on an intermediate state of the lot and system, the final product inspection, and thus the assessment of the actual yield, is delayed until production is complete. Repair steps are applied uniformly to the lot, potentially improving some of the individual items while degrading others. The challenge is thus to balance potential yield improvement with the rework costs incurred. Given the inherently causal nature of this decision problem, we propose a causal model to estimate yield improvement. We apply methods from causal machine learning, in particular double/debiased machine learning (DML) techniques, to estimate conditional treatment effects from data and derive policies for rework decisions. We validate our decision model using real-world data from opto-electronic semiconductor manufacturing, achieving a yield improvement of 2 - 3% during the color-conversion process of white light-emitting diodes (LEDs).
Causally Learning an Optimal Rework Policy
Jun 07, 2023



In manufacturing, rework refers to an optional step of a production process which aims to eliminate errors or remedy products that do not meet the desired quality standards. Reworking a production lot involves repeating a previous production stage with adjustments to ensure that the final product meets the required specifications. While offering the chance to improve the yield and thus increase the revenue of a production lot, a rework step also incurs additional costs. Additionally, the rework of parts that already meet the target specifications may damage them and decrease the yield. In this paper, we apply double/debiased machine learning (DML) to estimate the conditional treatment effect of a rework step during the color conversion process in opto-electronic semiconductor manufacturing on the final product yield. We utilize the implementation DoubleML to develop policies for the rework of components and estimate their value empirically. From our causal machine learning analysis we derive implications for the coating of monochromatic LEDs with conversion layers.
Efficient aggregation of face embeddings for decentralized face recognition deployments (extended version)
Dec 20, 2022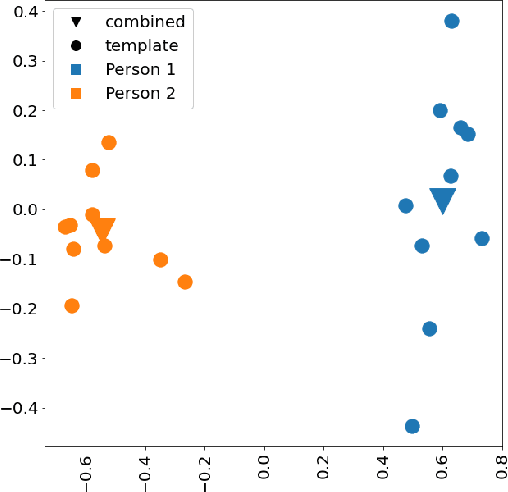
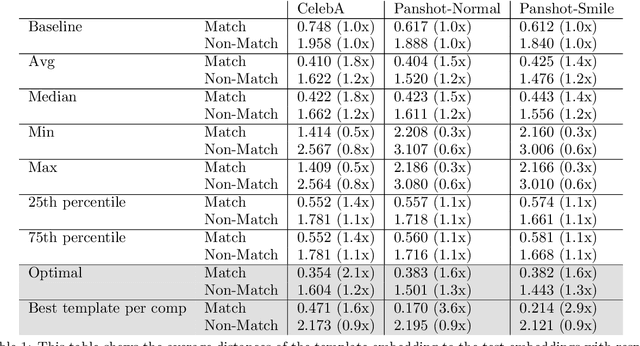
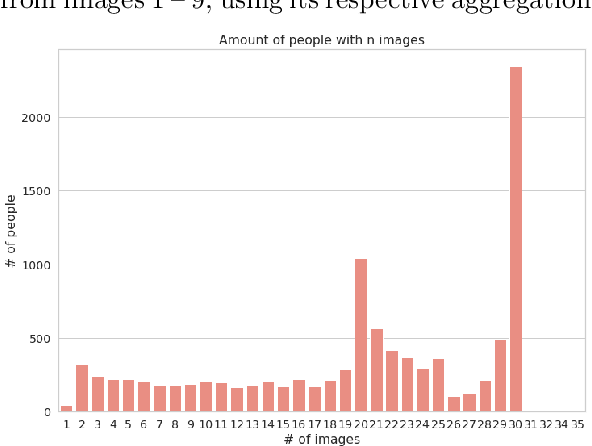
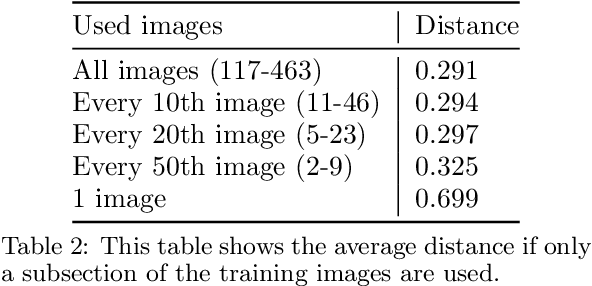
Biometrics are one of the most privacy-sensitive data. Ubiquitous authentication systems with a focus on privacy favor decentralized approaches as they reduce potential attack vectors, both on a technical and organizational level. The gold standard is to let the user be in control of where their own data is stored, which consequently leads to a high variety of devices used. Moreover, in comparison with a centralized system, designs with higher end-user freedom often incur additional network overhead. Therefore, when using face recognition for biometric authentication, an efficient way to compare faces is important in practical deployments, because it reduces both network and hardware requirements that are essential to encourage device diversity. This paper proposes an efficient way to aggregate embeddings used for face recognition based on an extensive analysis on different datasets and the use of different aggregation strategies. As part of this analysis, a new dataset has been collected, which is available for research purposes. Our proposed method supports the construction of massively scalable, decentralized face recognition systems with a focus on both privacy and long-term usability.