 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDA: A Context-Decoupled Hierarchical Agent with Reinforcement Learning
Dec 14, 2025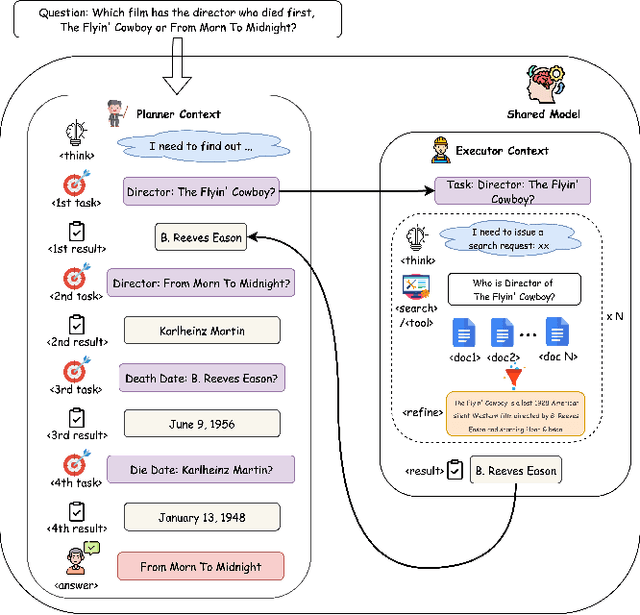
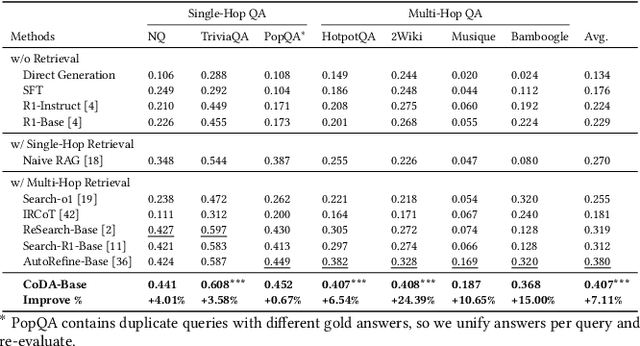
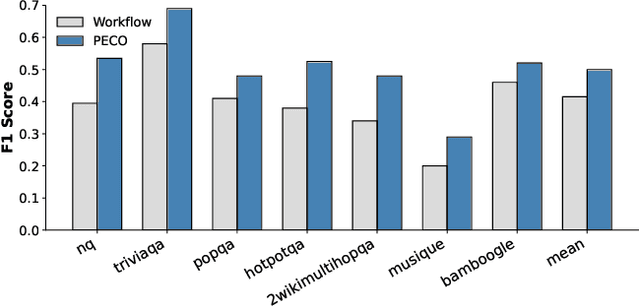
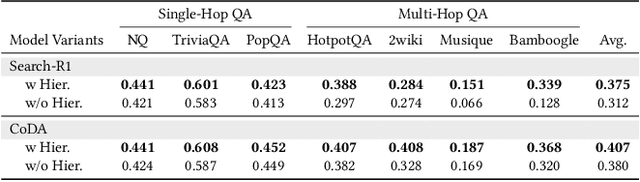
Large Language Model (LLM) agents trained with reinforcement learning (RL) show great promise for solving complex, multi-step tasks. However, their performance is often crippled by "Context Explosion", where the accumulation of long text outputs overwhelms the model's context window and leads to reasoning failures. To address this, we introduce CoDA, a Context-Decoupled hierarchical Agent, a simple but effective reinforcement learning framework that decouples high-level planning from low-level execution. It employs a single, shared LLM backbone that learns to operate in two distinct, contextually isolated roles: a high-level Planner that decomposes tasks within a concise strategic context, and a low-level Executor that handles tool interactions in an ephemeral, isolated workspace. We train this unified agent end-to-end using PECO (Planner-Executor Co-Optimization), a reinforcement learning methodology that applies a trajectory-level reward to jointly optimize both roles, fostering seamless collaboration through context-dependent policy updates. Extensive experiments demonstrate that CoDA achieves significant performance improvements over state-of-the-art baselines on complex multi-hop question-answering benchmarks, and it exhibits strong robustness in long-context scenarios, maintaining stable performance while all other baselines suffer severe degradation, thus further validating the effectiveness of our hierarchical design in mitigating context overload.
NAM: A Normalization Attention Model for Personalized Product Search In Fliggy
Jun 10, 2025Personalized product search provides significant benefits to e-commerce platforms by extracting more accurate user preferences from historical behaviors. Previous studies largely focused on the user factors when personalizing the search query, while ignoring the item perspective, which leads to the following two challenges that we summarize in this paper: First, previous approaches relying only on co-occurrence frequency tend to overestimate the conversion rates for popular items and underestimate those for long-tail items, resulting in inaccurate item similarities; Second, user purchasing propensity is highly heterogeneous according to the popularity of the target item: it is less correlated with the user's historical behavior for a popular item and more correlated for a long-tail item. To address these challenges, in this paper we propose NAM, a Normalization Attention Model, which optimizes ''when to personalize'' by utilizing Inverse Item Frequency (IIF) and employing a gating mechanism, as well as optimizes ''how to personalize'' by normalizing the attention mechanism from a global perspective. Through comprehensive experiments, we demonstrate that our proposed NAM model significantly outperforms state-of-the-art baseline models. Furthermore, we conducted an online A/B test at Fliggy, and obtained a significant improvement of 0.8% over the latest production system in conversion rate.
Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks
Jun 07, 2023To promote the development of Vision-Language Pre-training (VLP) and multimodal Large Language Model (LLM) in the Chinese community, we firstly release the largest public Chinese high-quality video-language dataset named Youku-mPLUG, which is collected from Youku, a well-known Chinese video-sharing website, with strict criteria of safety, diversity, and quality. Youku-mPLUG contains 10 million Chinese video-text pairs filtered from 400 million raw videos across a wide range of 45 diverse categories for large-scale pre-training. In addition, to facilitate a comprehensive evaluation of video-language models, we carefully build the largest human-annotated Chinese benchmarks covering three popular video-language tasks of cross-modal retrieval, video captioning, and video category classification. Youku-mPLUG can enable researchers to conduct more in-depth multimodal research and develop better applications in the future. Furthermore, we release popular video-language pre-training models, ALPRO and mPLUG-2, and our proposed modularized decoder-only model mPLUG-video pre-trained on Youku-mPLUG. Experiments show that models pre-trained on Youku-mPLUG gain up to 23.1% improvement in video category classification. Besides, mPLUG-video achieves a new state-of-the-art result on these benchmarks with 80.5% top-1 accuracy in video category classification and 68.9 CIDEr score in video captioning, respectively. Finally, we scale up mPLUG-video based on the frozen Bloomz with only 1.7% trainable parameters as Chinese multimodal LLM, and demonstrate impressive instruction and video understanding ability. The zero-shot instruction understanding experiment indicates that pretraining with Youku-mPLUG can enhance the ability to comprehend overall and detailed visual semantics, recognize scene text, and leverage open-domain knowledge.
PURS: Personalized Unexpected Recommender System for Improving User Satisfaction
Jun 05, 2021
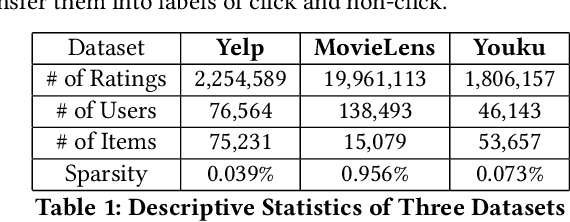
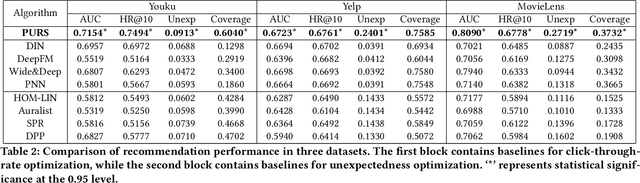
Classical recommender system methods typically face the filter bubble problem when users only receive recommendations of their familiar items, making them bored and dissatisfied. To address the filter bubble problem, unexpected recommendations have been proposed to recommend items significantly deviating from user's prior expectations and thus surprising them by presenting "fresh" and previously unexplored items to the users. In this paper, we describe a novel Personalized Unexpected Recommender System (PURS) model that incorporates unexpectedness into the recommendation process by providing multi-cluster modeling of user interests in the latent space and personalized unexpectedness via the self-attention mechanism and via selection of an appropriate unexpected activation function. Extensive offline experiments on three real-world datasets illustrate that the proposed PURS model significantly outperforms the state-of-the-art baseline approaches in terms of both accuracy and unexpectedness measures. In addition, we conduct an online A/B test at a major video platform Alibaba-Youku, where our model achieves over 3\% increase in the average video view per user metric. The proposed model is in the process of being deployed by the company.
Dual Attentive Sequential Learning for Cross-Domain Click-Through Rate Prediction
Jun 05, 2021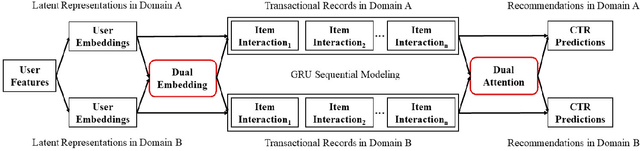
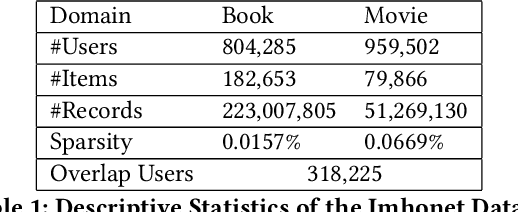
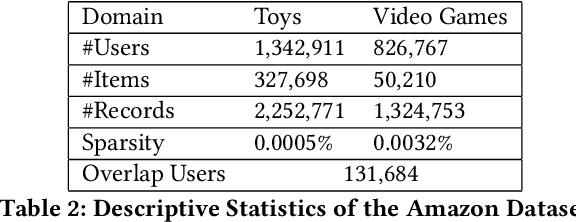
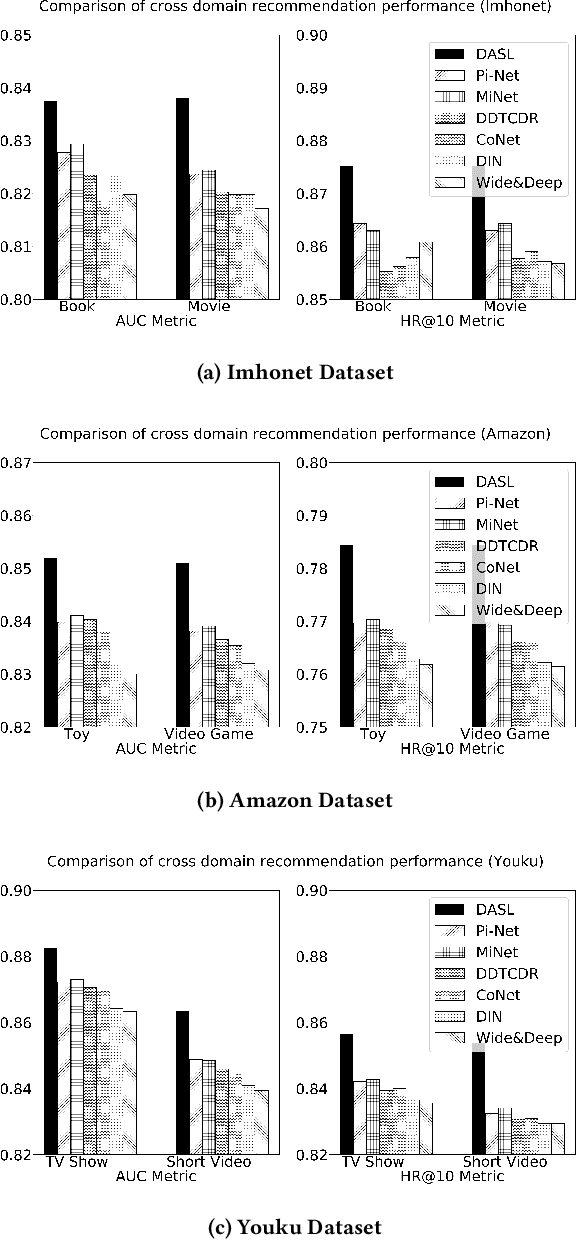
Cross domain recommender system constitutes a powerful method to tackle the cold-start and sparsity problem by aggregating and transferring user preferences across multiple category domains. Therefore, it has great potential to improve click-through-rate prediction performance in online commerce platforms having many domains of products. While several cross domain sequential recommendation models have been proposed to leverage information from a source domain to improve CTR predictions in a target domain, they did not take into account bidirectional latent relations of user preferences across source-target domain pairs. As such, they cannot provide enhanced cross-domain CTR predictions for both domains simultaneously. In this paper, we propose a novel approach to cross-domain sequential recommendations based on the dual learning mechanism that simultaneously transfers information between two related domains in an iterative manner until the learning process stabilizes. In particular, the proposed Dual Attentive Sequential Learning (DASL) model consists of two novel components Dual Embedding and Dual Attention, which jointly establish the two-stage learning process: we first construct dual latent embeddings that extract user preferences in both domains simultaneously, and subsequently provide cross-domain recommendations by matching the extracted latent embeddings with candidate items through dual-attention learning mechanism. We conduct extensive offline experiments on three real-world datasets to demonstrate the superiority of our proposed model, which significantly and consistently outperforms several state-of-the-art baselines across all experimental settings. We also conduct an online A/B test at a major video streaming platform Alibaba-Youku, where our proposed model significantly improves business performance over the latest production system in the company.