 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Information Silo: Semantic Personas for Cross-Domain Recommendation
Jun 01, 2026Digital platforms increasingly operate as isolated information silos, limiting their ability to construct comprehensive user representations across domains. Cross-domain recommender systems seek to overcome this limitation by transferring knowledge from a source domain to a target domain, yet most existing approaches depend on shared users, shared items, or structurally similar interaction graphs. These assumptions are often unrealistic across independent platforms. We propose SPHERE (Semantic Personas for Heterogeneous cross-domain Recommendation), a design artifact that enables recommendation knowledge transfer across strictly disjoint domains with no shared users or items. Rather than aligning domains through identity or graph structure, SPHERE uses large language models to induce a shared behavioral vocabulary, generate structured semantic personas for users, and retrieve behaviorally similar source-domain communities that form a Community Source Persona. This semantic signal is integrated with collaborative signals through a dual-tower architecture and dynamic fusion gate, allowing SPHERE to augment standard recommender backbones. Empirical evaluation across Amazon Books, Goodreads, and Steam demonstrates consistent improvements over NCF, SVD++, and LightGCN baselines under full-ranking evaluation. The results show that cross-domain transfer effectiveness is not determined solely by semantic proximity between domains; rather, it depends critically on the structural density and native predictive strength of the target domain. The study contributes to information systems research by reframing cross-domain personalization as behavior-based semantic alignment, offering a practical mechanism for overcoming information silos while preserving interpretability and modularity.
STARE: Predicting Decision Making Based on Spatio-Temporal Eye Movements
Aug 06, 2025
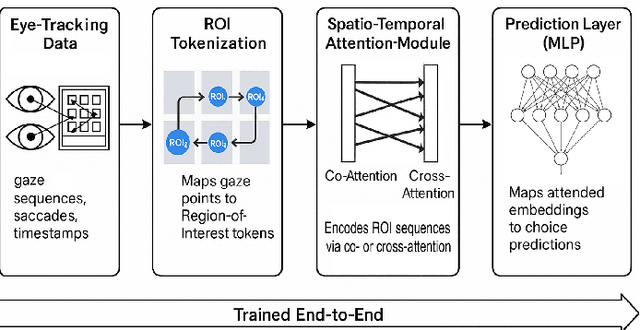


The present work proposes a Deep Learning architecture for the prediction of various consumer choice behaviors from time series of raw gaze or eye fixations on images of the decision environment, for which currently no foundational models are available. The architecture, called STARE (Spatio-Temporal Attention Representation for Eye Tracking), uses a new tokenization strategy, which involves mapping the x- and y- pixel coordinates of eye-movement time series on predefined, contiguous Regions of Interest. That tokenization makes the spatio-temporal eye-movement data available to the Chronos, a time-series foundation model based on the T5 architecture, to which co-attention and/or cross-attention is added to capture directional and/or interocular influences of eye movements. We compare STARE with several state-of-the art alternatives on multiple datasets with the purpose of predicting consumer choice behaviors from eye movements. We thus make a first step towards developing and testing DL architectures that represent visual attention dynamics rooted in the neurophysiology of eye movements.
Sequence Preserving Network Traffic Generation
Feb 23, 2020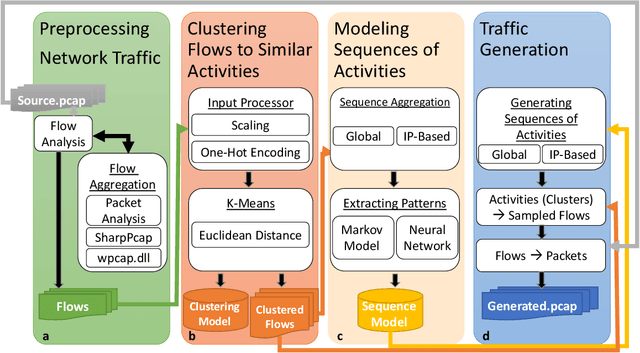


We present the Network Traffic Generator (NTG), a framework for perturbing recorded network traffic with the purpose of generating diverse but realistic background traffic for network simulation and what-if analysis in enterprise environments. The framework preserves many characteristics of the original traffic recorded in an enterprise, as well as sequences of network activities. Using the proposed framework, the original traffic flows are profiled using 200 cross-protocol features. The traffic is aggregated into flows of packets between IP pairs and clustered into groups of similar network activities. Sequences of network activities are then extracted. We examined two methods for extracting sequences of activities: a Markov model and a neural language model. Finally, new traffic is generated using the extracted model. We developed a prototype of the framework and conducted extensive experiments based on two real network traffic collections. Hypothesis testing was used to examine the difference between the distribution of original and generated features, showing that 30-100\% of the extracted features were preserved. Small differences between n-gram perplexities in sequences of network activities in the original and generated traffic, indicate that sequences of network activities were well preserved.
Deep Context-Aware Recommender System Utilizing Sequential Latent Context
Sep 09, 2019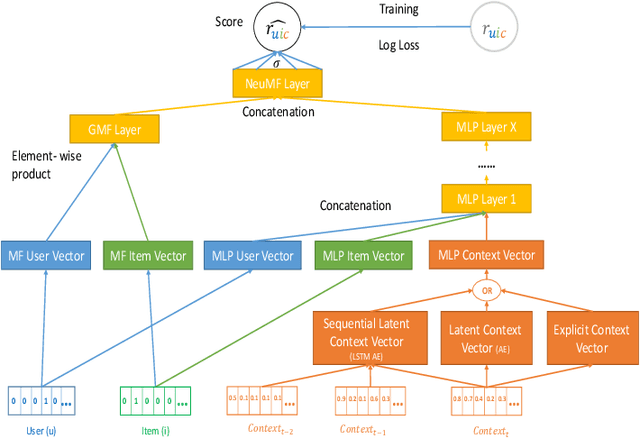

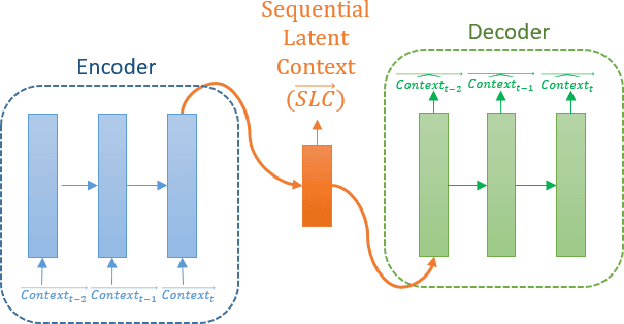
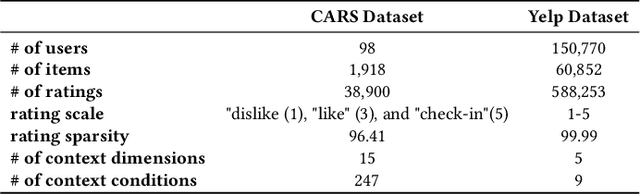
Context-aware recommender systems (CARSs) apply sensing and analysis of user context in order to provide personalized services. Adding context to a recommendation model is challenging, since the addition of context may increases both the dimensionality and sparsity of the model. Recent research has shown that modeling contextual information as a latent vector may address the sparsity and dimensionality challenges. We suggest a new latent modeling of sequential context by generating sequences of contextual information and reducing their contextual space to a compressed latent space.We train a long short-term memory (LSTM) encoder-decoder network on sequences of contextual information and extract sequential latent context from the hidden layer of the network in order to represent a compressed representation of sequential data. We propose new context-aware recommendation models that extend the neural collaborative filtering approach and learn nonlinear interactions between latent features of users, items, and contexts which take into account the sequential latent context representation as part of the recommendation process. We deployed our approach using two context-aware datasets with different context dimensions. Empirical analysis of our results validates that our proposed sequential latent context-aware model (SLCM), surpasses state of the art CARS models.