 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivGen: Preserving Privacy of Sequences Through Data Generation
Feb 23, 2020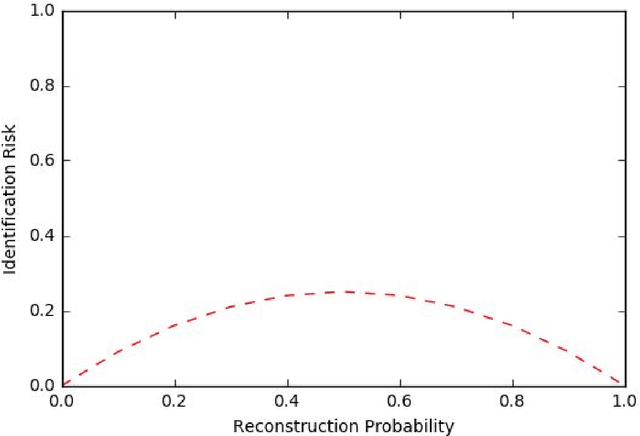

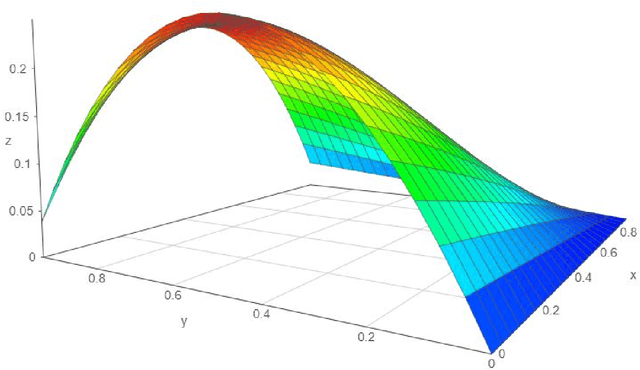
Sequential data is everywhere, and it can serve as a basis for research that will lead to improved processes. For example, road infrastructure can be improved by identifying bottlenecks in GPS data, or early diagnosis can be improved by analyzing patterns of disease progression in medical data. The main obstacle is that access and use of such data is usually limited or not permitted at all due to concerns about violating user privacy, and rightly so. Anonymizing sequence data is not a simple task, since a user creates an almost unique signature over time. Existing anonymization methods reduce the quality of information in order to maintain the level of anonymity required. Damage to quality may disrupt patterns that appear in the original data and impair the preservation of various characteristics. Since in many cases the researcher does not need the data as is and instead is only interested in the patterns that exist in the data, we propose PrivGen, an innovative method for generating data that maintains patterns and characteristics of the source data. We demonstrate that the data generation mechanism significantly limits the risk of privacy infringement. Evaluating our method with real-world datasets shows that its generated data preserves many characteristics of the data, including the sequential model, as trained based on the source data. This suggests that the data generated by our method could be used in place of actual data for various types of analysis, maintaining user privacy and the data's integrity at the same time.
Sequence Preserving Network Traffic Generation
Feb 23, 2020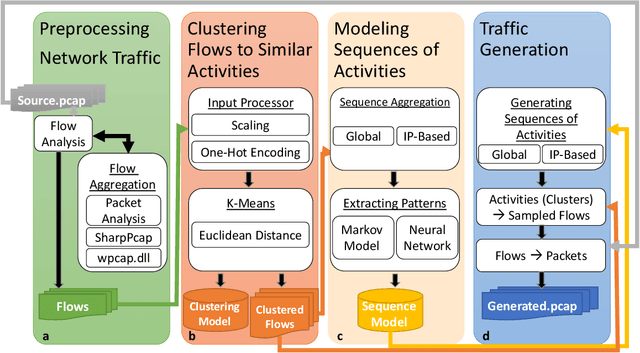


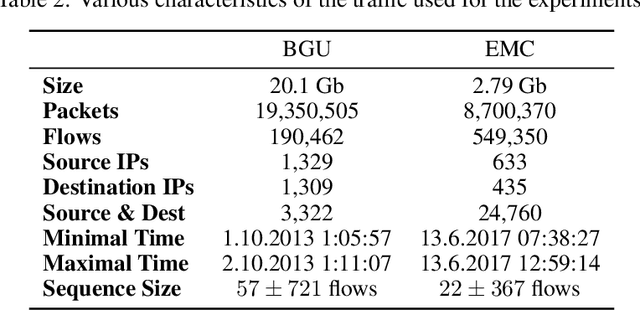
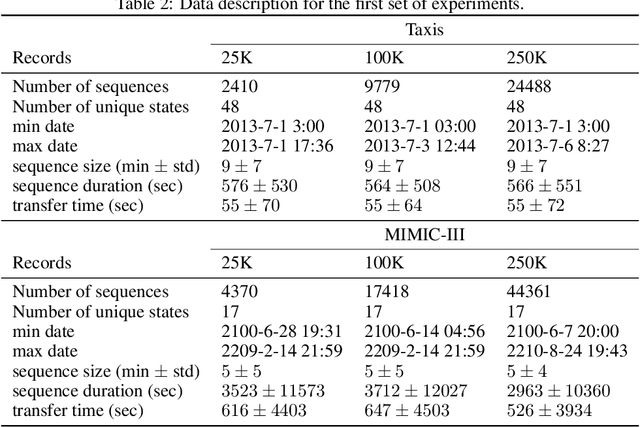
We present the Network Traffic Generator (NTG), a framework for perturbing recorded network traffic with the purpose of generating diverse but realistic background traffic for network simulation and what-if analysis in enterprise environments. The framework preserves many characteristics of the original traffic recorded in an enterprise, as well as sequences of network activities. Using the proposed framework, the original traffic flows are profiled using 200 cross-protocol features. The traffic is aggregated into flows of packets between IP pairs and clustered into groups of similar network activities. Sequences of network activities are then extracted. We examined two methods for extracting sequences of activities: a Markov model and a neural language model. Finally, new traffic is generated using the extracted model. We developed a prototype of the framework and conducted extensive experiments based on two real network traffic collections. Hypothesis testing was used to examine the difference between the distribution of original and generated features, showing that 30-100\% of the extracted features were preserved. Small differences between n-gram perplexities in sequences of network activities in the original and generated traffic, indicate that sequences of network activities were well preserved.