 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorized Embedding Layers for Efficient Model Compression
Paper and Code
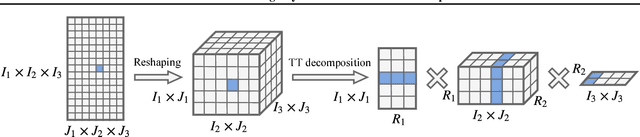

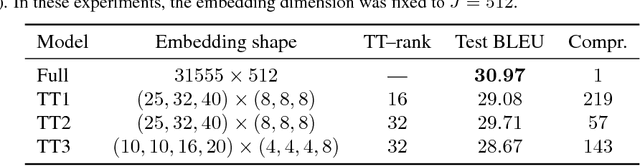
The embedding layers transforming input words into real vectors are the key components of deep neural networks used in natural language processing. However, when the vocabulary is large (e.g., 800k unique words in the One-Billion-Word dataset), the corresponding weight matrices can be enormous, which precludes their deployment in a limited resource setting. We introduce a novel way of parametrizing embedding layers based on the Tensor Train (TT) decomposition, which allows compressing the model significantly at the cost of a negligible drop or even a slight gain in performance. Importantly, our method does not take the pre-trained model and compress its weights but rather supplants the standard embedding layers with their TT-based counterparts. The resulting model is then trained end-to-end, however, it can capitalize on larger batches due to the reduced memory requirements. We evaluate our method on a wide range of benchmarks in sentiment analysis, neural machine translation, and language modeling, and analyze the trade-off between performance and compression ratios for a wide range of architectures, from MLPs to LSTMs and Transformers.