 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDehallu3D: Hallucination-Mitigated 3D Generation from Single Image via Cyclic View Consistency Refinement
Mar 02, 2026Large 3D reconstruction models have revolutionized the 3D content generation field, enabling broad applications in virtual reality and gaming. Just like other large models, large 3D reconstruction models suffer from hallucinations as well, introducing structural outliers (e.g., odd holes or protrusions) that deviate from the input data. However, unlike other large models, hallucinations in large 3D reconstruction models remain severely underexplored, leading to malformed 3D-printed objects or insufficient immersion in virtual scenes. Such hallucinations majorly originate from that existing methods reconstruct 3D content from sparsely generated multi-view images which suffer from large viewpoint gaps and discontinuities. To mitigate hallucinations by eliminating the outliers, we propose Dehallu3D for 3D mesh generation. Our key idea is to design a balanced multi-view continuity constraint to enforce smooth transitions across dense intermediate viewpoints, while avoiding over-smoothing that could erase sharp geometric features. Therefore, Dehallu3D employs a plug-and-play optimization module with two key constraints: (i) adjacent consistency to ensure geometric continuity across views, and (ii) adaptive smoothness to retain fine details.We further propose the Outlier Risk Measure (ORM) metric to quantify geometric fidelity in 3D generation from the perspective of outliers. Extensive experiments show that Dehallu3D achieves high-fidelity 3D generation by effectively preserving structural details while removing hallucinated outliers.
QEMesh: Employing A Quadric Error Metrics-Based Representation for Mesh Generation
Apr 08, 2025Mesh generation plays a crucial role in 3D content creation, as mesh is widely used in various industrial applications. Recent works have achieved impressive results but still face several issues, such as unrealistic patterns or pits on surfaces, thin parts missing, and incomplete structures. Most of these problems stem from the choice of shape representation or the capabilities of the generative network. To alleviate these, we extend PoNQ, a Quadric Error Metrics (QEM)-based representation, and propose a novel model, QEMesh, for high-quality mesh generation. PoNQ divides the shape surface into tiny patches, each represented by a point with its normal and QEM matrix, which preserves fine local geometry information. In our QEMesh, we regard these elements as generable parameters and design a unique latent diffusion model containing a novel multi-decoder VAE for PoNQ parameters generation. Given the latent code generated by the diffusion model, three parameter decoders produce several PoNQ parameters within each voxel cell, and an occupancy decoder predicts which voxel cells containing parameters to form the final shape. Extensive evaluations demonstrate that our method generates results with watertight surfaces and is comparable to state-of-the-art methods in several main metrics.
MTFusion: Reconstructing Any 3D Object from Single Image Using Multi-word Textual Inversion
Nov 19, 2024Reconstructing 3D models from single-view images is a long-standing problem in computer vision. The latest advances for single-image 3D reconstruction extract a textual description from the input image and further utilize it to synthesize 3D models. However, existing methods focus on capturing a single key attribute of the image (e.g., object type, artistic style) and fail to consider the multi-perspective information required for accurate 3D reconstruction, such as object shape and material properties. Besides, the reliance on Neural Radiance Fields hinders their ability to reconstruct intricate surfaces and texture details. In this work, we propose MTFusion, which leverages both image data and textual descriptions for high-fidelity 3D reconstruction. Our approach consists of two stages. First, we adopt a novel multi-word textual inversion technique to extract a detailed text description capturing the image's characteristics. Then, we use this description and the image to generate a 3D model with FlexiCubes. Additionally, MTFusion enhances FlexiCubes by employing a special decoder network for Signed Distance Functions, leading to faster training and finer surface representation. Extensive evaluations demonstrate that our MTFusion surpasses existing image-to-3D methods on a wide range of synthetic and real-world images. Furthermore, the ablation study proves the effectiveness of our network designs.
* PRCV 2024
GenUDC: High Quality 3D Mesh Generation with Unsigned Dual Contouring Representation
Oct 23, 2024Generating high-quality meshes with complex structures and realistic surfaces is the primary goal of 3D generative models. Existing methods typically employ sequence data or deformable tetrahedral grids for mesh generation. However, sequence-based methods have difficulty producing complex structures with many faces due to memory limits. The deformable tetrahedral grid-based method MeshDiffusion fails to recover realistic surfaces due to the inherent ambiguity in deformable grids. We propose the GenUDC framework to address these challenges by leveraging the Unsigned Dual Contouring (UDC) as the mesh representation. UDC discretizes a mesh in a regular grid and divides it into the face and vertex parts, recovering both complex structures and fine details. As a result, the one-to-one mapping between UDC and mesh resolves the ambiguity problem. In addition, GenUDC adopts a two-stage, coarse-to-fine generative process for 3D mesh generation. It first generates the face part as a rough shape and then the vertex part to craft a detailed shape. Extensive evaluations demonstrate the superiority of UDC as a mesh representation and the favorable performance of GenUDC in mesh generation. The code and trained models are available at https://github.com/TrepangCat/GenUDC.
Generating 3D House Wireframes with Semantics
Jul 17, 2024We present a new approach for generating 3D house wireframes with semantic enrichment using an autoregressive model. Unlike conventional generative models that independently process vertices, edges, and faces, our approach employs a unified wire-based representation for improved coherence in learning 3D wireframe structures. By re-ordering wire sequences based on semantic meanings, we facilitate seamless semantic integration during sequence generation. Our two-phase technique merges a graph-based autoencoder with a transformer-based decoder to learn latent geometric tokens and generate semantic-aware wireframes. Through iterative prediction and decoding during inference, our model produces detailed wireframes that can be easily segmented into distinct components, such as walls, roofs, and rooms, reflecting the semantic essence of the shape. Empirical results on a comprehensive house dataset validate the superior accuracy, novelty, and semantic fidelity of our model compared to existing generative models. More results and details can be found on https://vcc.tech/research/2024/3DWire.
3D Semantic Subspace Traverser: Empowering 3D Generative Model with Shape Editing Capability
Aug 16, 2023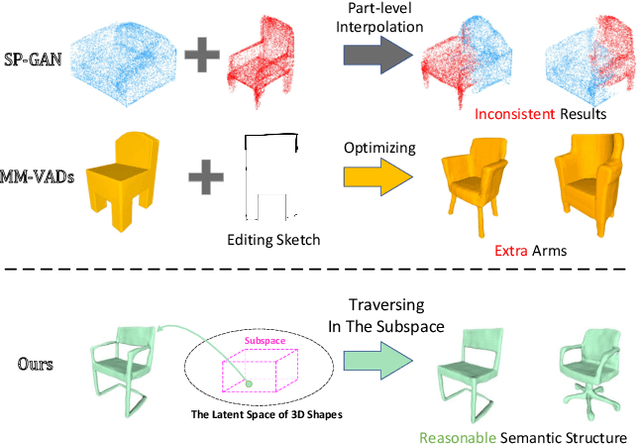

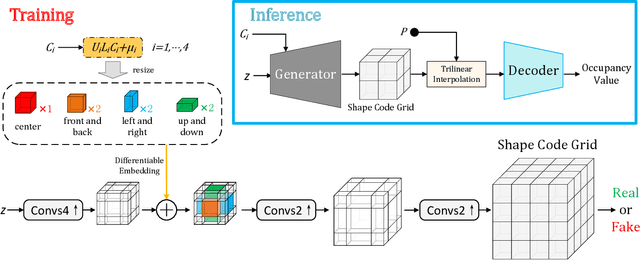

Shape generation is the practice of producing 3D shapes as various representations for 3D content creation. Previous studies on 3D shape generation have focused on shape quality and structure, without or less considering the importance of semantic information. Consequently, such generative models often fail to preserve the semantic consistency of shape structure or enable manipulation of the semantic attributes of shapes during generation. In this paper, we proposed a novel semantic generative model named 3D Semantic Subspace Traverser that utilizes semantic attributes for category-specific 3D shape generation and editing. Our method utilizes implicit functions as the 3D shape representation and combines a novel latent-space GAN with a linear subspace model to discover semantic dimensions in the local latent space of 3D shapes. Each dimension of the subspace corresponds to a particular semantic attribute, and we can edit the attributes of generated shapes by traversing the coefficients of those dimensions. Experimental results demonstrate that our method can produce plausible shapes with complex structures and enable the editing of semantic attributes. The code and trained models are available at https://github.com/TrepangCat/3D_Semantic_Subspace_Traverser
Watermark Faker: Towards Forgery of Digital Image Watermarking
Mar 23, 2021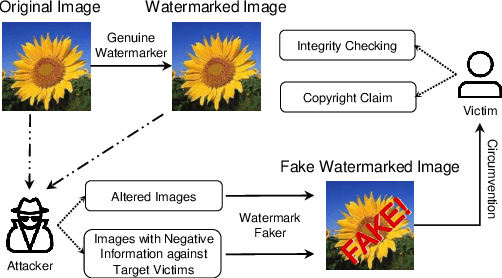
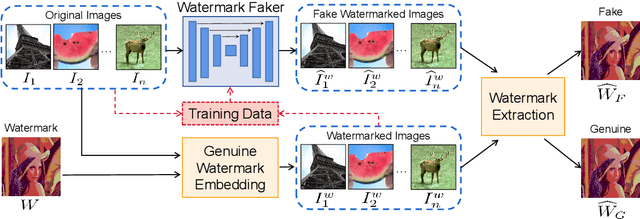
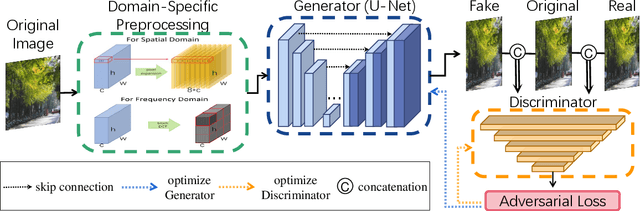
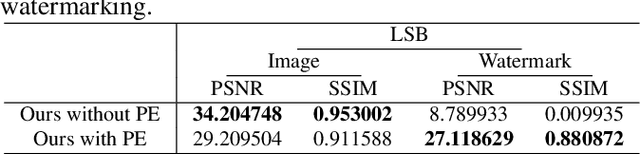
Digital watermarking has been widely used to protect the copyright and integrity of multimedia data. Previous studies mainly focus on designing watermarking techniques that are robust to attacks of destroying the embedded watermarks. However, the emerging deep learning based image generation technology raises new open issues that whether it is possible to generate fake watermarked images for circumvention. In this paper, we make the first attempt to develop digital image watermark fakers by using generative adversarial learning. Suppose that a set of paired images of original and watermarked images generated by the targeted watermarker are available, we use them to train a watermark faker with U-Net as the backbone, whose input is an original image, and after a domain-specific preprocessing, it outputs a fake watermarked image. Our experiments show that the proposed watermark faker can effectively crack digital image watermarkers in both spatial and frequency domains, suggesting the risk of such forgery attacks.