 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Jun 05, 2025We introduce PartCrafter, the first structured 3D generative model that jointly synthesizes multiple semantically meaningful and geometrically distinct 3D meshes from a single RGB image. Unlike existing methods that either produce monolithic 3D shapes or follow two-stage pipelines, i.e., first segmenting an image and then reconstructing each segment, PartCrafter adopts a unified, compositional generation architecture that does not rely on pre-segmented inputs. Conditioned on a single image, it simultaneously denoises multiple 3D parts, enabling end-to-end part-aware generation of both individual objects and complex multi-object scenes. PartCrafter builds upon a pretrained 3D mesh diffusion transformer (DiT) trained on whole objects, inheriting the pretrained weights, encoder, and decoder, and introduces two key innovations: (1) A compositional latent space, where each 3D part is represented by a set of disentangled latent tokens; (2) A hierarchical attention mechanism that enables structured information flow both within individual parts and across all parts, ensuring global coherence while preserving part-level detail during generation. To support part-level supervision, we curate a new dataset by mining part-level annotations from large-scale 3D object datasets. Experiments show that PartCrafter outperforms existing approaches in generating decomposable 3D meshes, including parts that are not directly visible in input images, demonstrating the strength of part-aware generative priors for 3D understanding and synthesis. Code and training data will be released.
Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
Mar 15, 2025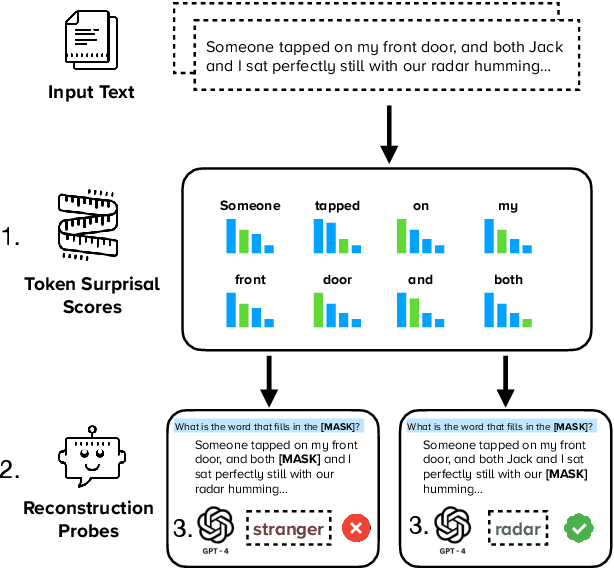

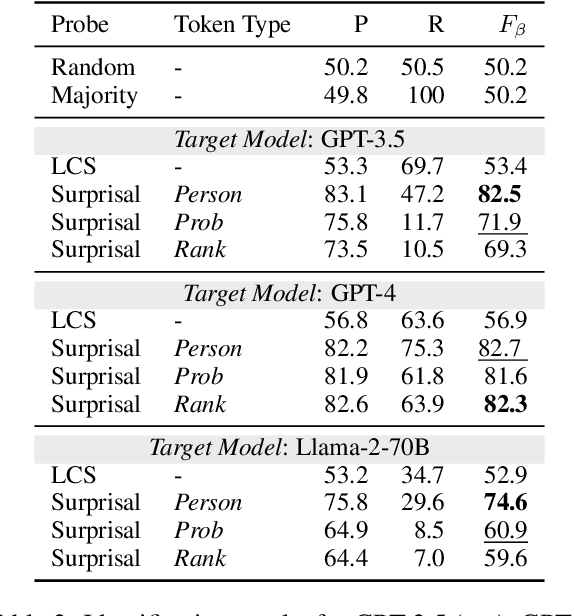
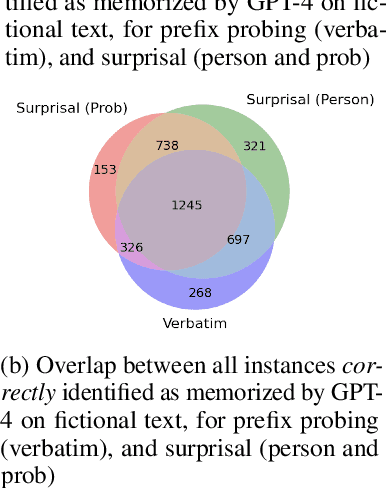
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. This lack of transparency creates multiple challenges: it limits external oversight and inspection of LLMs for issues such as copyright infringement, it undermines the agency of data authors, and it hinders scientific research on critical issues such as data contamination and data selection. How can we recover what training data is known to LLMs? In this work, we demonstrate a new method to identify training data known to proprietary LLMs like GPT-4 without requiring any access to model weights or token probabilities, by using information-guided probes. Our work builds on a key observation: text passages with high surprisal are good search material for memorization probes. By evaluating a model's ability to successfully reconstruct high-surprisal tokens in text, we can identify a surprising number of texts memorized by LLMs.
OmniPhysGS: 3D Constitutive Gaussians for General Physics-Based Dynamics Generation
Jan 31, 2025



Recently, significant advancements have been made in the reconstruction and generation of 3D assets, including static cases and those with physical interactions. To recover the physical properties of 3D assets, existing methods typically assume that all materials belong to a specific predefined category (e.g., elasticity). However, such assumptions ignore the complex composition of multiple heterogeneous objects in real scenarios and tend to render less physically plausible animation given a wider range of objects. We propose OmniPhysGS for synthesizing a physics-based 3D dynamic scene composed of more general objects. A key design of OmniPhysGS is treating each 3D asset as a collection of constitutive 3D Gaussians. For each Gaussian, its physical material is represented by an ensemble of 12 physical domain-expert sub-models (rubber, metal, honey, water, etc.), which greatly enhances the flexibility of the proposed model. In the implementation, we define a scene by user-specified prompts and supervise the estimation of material weighting factors via a pretrained video diffusion model. Comprehensive experiments demonstrate that OmniPhysGS achieves more general and realistic physical dynamics across a broader spectrum of materials, including elastic, viscoelastic, plastic, and fluid substances, as well as interactions between different materials. Our method surpasses existing methods by approximately 3% to 16% in metrics of visual quality and text alignment.
An Analysis Framework for Understanding Deep Neural Networks Based on Network Dynamics
Jan 05, 2025



Advancing artificial intelligence demands a deeper understanding of the mechanisms underlying deep learning. Here, we propose a straightforward analysis framework based on the dynamics of learning models. Neurons are categorized into two modes based on whether their transformation functions preserve order. This categorization reveals how deep neural networks (DNNs) maximize information extraction by rationally allocating the proportion of neurons in different modes across deep layers. We further introduce the attraction basins of the training samples in both the sample vector space and the weight vector space to characterize the generalization ability of DNNs. This framework allows us to identify optimal depth and width configurations, providing a unified explanation for fundamental DNN behaviors such as the "flat minima effect," "grokking," and double descent phenomena. Our analysis extends to networks with depths up to 100 layers.
InstructLayout: Instruction-Driven 2D and 3D Layout Synthesis with Semantic Graph Prior
Jul 11, 2024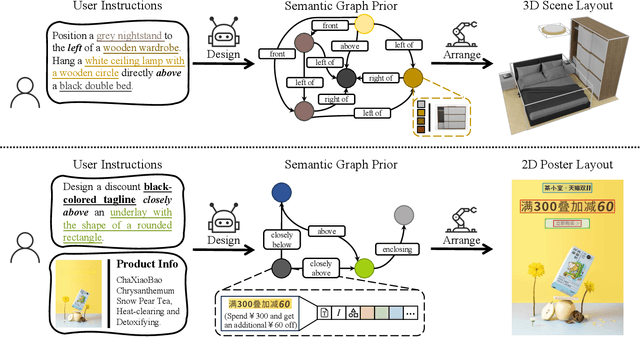
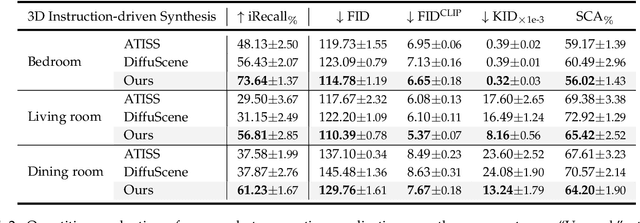
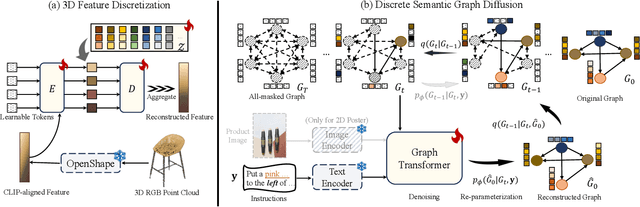
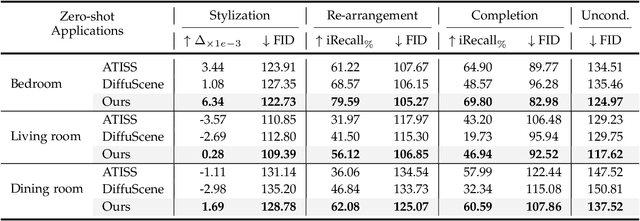
Comprehending natural language instructions is a charming property for both 2D and 3D layout synthesis systems. Existing methods implicitly model object joint distributions and express object relations, hindering generation's controllability. We introduce InstructLayout, a novel generative framework that integrates a semantic graph prior and a layout decoder to improve controllability and fidelity for 2D and 3D layout synthesis. The proposed semantic graph prior learns layout appearances and object distributions simultaneously, demonstrating versatility across various downstream tasks in a zero-shot manner. To facilitate the benchmarking for text-driven 2D and 3D scene synthesis, we respectively curate two high-quality datasets of layout-instruction pairs from public Internet resources with large language and multimodal models. Extensive experimental results reveal that the proposed method outperforms existing state-of-the-art approaches by a large margin in both 2D and 3D layout synthesis tasks. Thorough ablation studies confirm the efficacy of crucial design components.
CATP: Context-Aware Trajectory Prediction with Competition Symbiosis
Jul 10, 2024



Contextual information is vital for accurate trajectory prediction. For instance, the intricate flying behavior of migratory birds hinges on their analysis of environmental cues such as wind direction and air pressure. However, the diverse and dynamic nature of contextual information renders it an arduous task for AI models to comprehend its impact on trajectories and consequently predict them accurately. To address this issue, we propose a ``manager-worker'' framework to unleash the full potential of contextual information and construct CATP model, an implementation of the framework for Context-Aware Trajectory Prediction. The framework comprises a manager model, several worker models, and a tailored training mechanism inspired by competition symbiosis in nature. Taking CATP as an example, each worker needs to compete against others for training data and develop an advantage in predicting specific moving patterns. The manager learns the workers' performance in different contexts and selects the best one in the given context to predict trajectories, enabling CATP as a whole to operate in a symbiotic manner. We conducted two comparative experiments and an ablation study to quantitatively evaluate the proposed framework and CATP model. The results showed that CATP could outperform SOTA models, and the framework could be generalized to different context-aware tasks.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024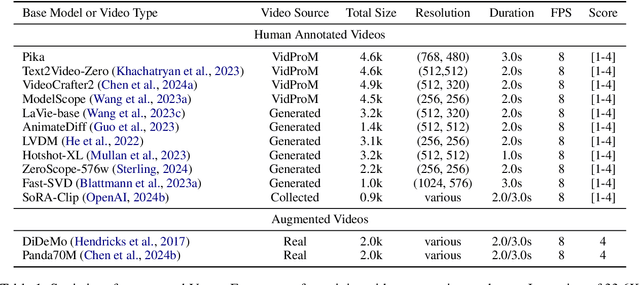

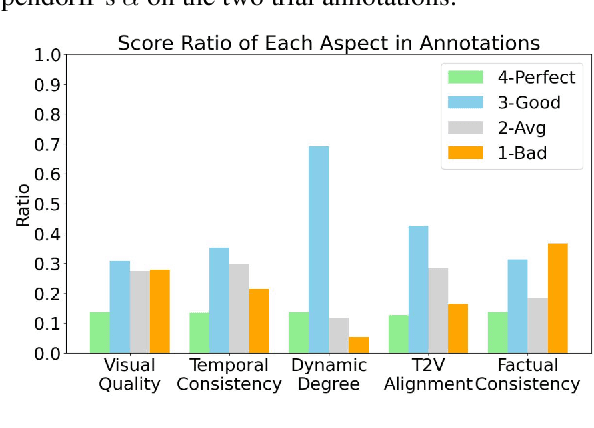

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
L3GO: Language Agents with Chain-of-3D-Thoughts for Generating Unconventional Objects
Feb 14, 2024Diffusion-based image generation models such as DALL-E 3 and Stable Diffusion-XL demonstrate remarkable capabilities in generating images with realistic and unique compositions. Yet, these models are not robust in precisely reasoning about physical and spatial configurations of objects, especially when instructed with unconventional, thereby out-of-distribution descriptions, such as "a chair with five legs". In this paper, we propose a language agent with chain-of-3D-thoughts (L3GO), an inference-time approach that can reason about part-based 3D mesh generation of unconventional objects that current data-driven diffusion models struggle with. More concretely, we use large language models as agents to compose a desired object via trial-and-error within the 3D simulation environment. To facilitate our investigation, we develop a new benchmark, Unconventionally Feasible Objects (UFO), as well as SimpleBlenv, a wrapper environment built on top of Blender where language agents can build and compose atomic building blocks via API calls. Human and automatic GPT-4V evaluations show that our approach surpasses the standard GPT-4 and other language agents (e.g., ReAct and Reflexion) for 3D mesh generation on ShapeNet. Moreover, when tested on our UFO benchmark, our approach outperforms other state-of-the-art text-to-2D image and text-to-3D models based on human evaluation.