 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis Framework for Understanding Deep Neural Networks Based on Network Dynamics
Jan 05, 2025



Advancing artificial intelligence demands a deeper understanding of the mechanisms underlying deep learning. Here, we propose a straightforward analysis framework based on the dynamics of learning models. Neurons are categorized into two modes based on whether their transformation functions preserve order. This categorization reveals how deep neural networks (DNNs) maximize information extraction by rationally allocating the proportion of neurons in different modes across deep layers. We further introduce the attraction basins of the training samples in both the sample vector space and the weight vector space to characterize the generalization ability of DNNs. This framework allows us to identify optimal depth and width configurations, providing a unified explanation for fundamental DNN behaviors such as the "flat minima effect," "grokking," and double descent phenomena. Our analysis extends to networks with depths up to 100 layers.
Unsupervised Machine Learning for Detecting and Locating Human-Made Objects in 3D Point Cloud
Oct 25, 2024A 3D point cloud is an unstructured, sparse, and irregular dataset, typically collected by airborne LiDAR systems over a geological region. Laser pulses emitted from these systems reflect off objects both on and above the ground, resulting in a dataset containing the longitude, latitude, and elevation of each point, as well as information about the corresponding laser pulse strengths. A widely studied research problem, addressed in many previous works, is ground filtering, which involves partitioning the points into ground and non-ground subsets. This research introduces a novel task: detecting and identifying human-made objects amidst natural tree structures. This task is performed on the subset of non-ground points derived from the ground filtering stage. Marked Point Fields (MPFs) are used as models well-suited to these tasks. The proposed methodology consists of three stages: ground filtering, local information extraction (LIE), and clustering. In the ground filtering stage, a statistical method called One-Sided Regression (OSR) is introduced, addressing the limitations of prior ground filtering methods on uneven terrains. In the LIE stage, unsupervised learning methods are lacking. To mitigate this, a kernel-based method for the Hessian matrix of the MPF is developed. In the clustering stage, the Gaussian Mixture Model (GMM) is applied to the results of the LIE stage to partition the non-ground points into trees and human-made objects. The underlying assumption is that LiDAR points from trees exhibit a three-dimensional distribution, while those from human-made objects follow a two-dimensional distribution. The Hessian matrix of the MPF effectively captures this distinction. Experimental results demonstrate that the proposed ground filtering method outperforms previous techniques, and the LIE method successfully distinguishes between points representing trees and human-made objects.
Exploring a Physics-Informed Decision Transformer for Distribution System Restoration: Methodology and Performance Analysis
Jun 30, 2024



Driven by advancements in sensing and computing, deep reinforcement learning (DRL)-based methods have demonstrated significant potential in effectively tackling distribution system restoration (DSR) challenges under uncertain operational scenarios. However, the data-intensive nature of DRL poses obstacles in achieving satisfactory DSR solutions for large-scale, complex distribution systems. Inspired by the transformative impact of emerging foundation models, including large language models (LLMs), across various domains, this paper explores an innovative approach harnessing LLMs' powerful computing capabilities to address scalability challenges inherent in conventional DRL methods for solving DSR. To our knowledge, this study represents the first exploration of foundation models, including LLMs, in revolutionizing conventional DRL applications in power system operations. Our contributions are twofold: 1) introducing a novel LLM-powered Physics-Informed Decision Transformer (PIDT) framework that leverages LLMs to transform conventional DRL methods for DSR operations, and 2) conducting comparative studies to assess the performance of the proposed LLM-powered PIDT framework at its initial development stage for solving DSR problems. While our primary focus in this paper is on DSR operations, the proposed PIDT framework can be generalized to optimize sequential decision-making across various power system operations.
Methodology and Real-World Applications of Dynamic Uncertain Causality Graph for Clinical Diagnosis with Explainability and Invariance
Jun 09, 2024AI-aided clinical diagnosis is desired in medical care. Existing deep learning models lack explainability and mainly focus on image analysis. The recently developed Dynamic Uncertain Causality Graph (DUCG) approach is causality-driven, explainable, and invariant across different application scenarios, without problems of data collection, labeling, fitting, privacy, bias, generalization, high cost and high energy consumption. Through close collaboration between clinical experts and DUCG technicians, 46 DUCG models covering 54 chief complaints were constructed. Over 1,000 diseases can be diagnosed without triage. Before being applied in real-world, the 46 DUCG models were retrospectively verified by third-party hospitals. The verified diagnostic precisions were no less than 95%, in which the diagnostic precision for every disease including uncommon ones was no less than 80%. After verifications, the 46 DUCG models were applied in the real-world in China. Over one million real diagnosis cases have been performed, with only 17 incorrect diagnoses identified. Due to DUCG's transparency, the mistakes causing the incorrect diagnoses were found and corrected. The diagnostic abilities of the clinicians who applied DUCG frequently were improved significantly. Following the introduction to the earlier presented DUCG methodology, the recommendation algorithm for potential medical checks is presented and the key idea of DUCG is extracted.
Multi-scale Alternated Attention Transformer for Generalized Stereo Matching
Aug 06, 2023Recent stereo matching networks achieves dramatic performance by introducing epipolar line constraint to limit the matching range of dual-view. However, in complicated real-world scenarios, the feature information based on intra-epipolar line alone is too weak to facilitate stereo matching. In this paper, we present a simple but highly effective network called Alternated Attention U-shaped Transformer (AAUformer) to balance the impact of epipolar line in dual and single view respectively for excellent generalization performance. Compared to other models, our model has several main designs: 1) to better liberate the local semantic features of the single-view at pixel level, we introduce window self-attention to break the limits of intra-row self-attention and completely replace the convolutional network for denser features before cross-matching; 2) the multi-scale alternated attention backbone network was designed to extract invariant features in order to achieves the coarse-to-fine matching process for hard-to-discriminate regions. We performed a series of both comparative studies and ablation studies on several mainstream stereo matching datasets. The results demonstrate that our model achieves state-of-the-art on the Scene Flow dataset, and the fine-tuning performance is competitive on the KITTI 2015 dataset. In addition, for cross generalization experiments on synthetic and real-world datasets, our model outperforms several state-of-the-art works.
Faithful Question Answering with Monte-Carlo Planning
May 04, 2023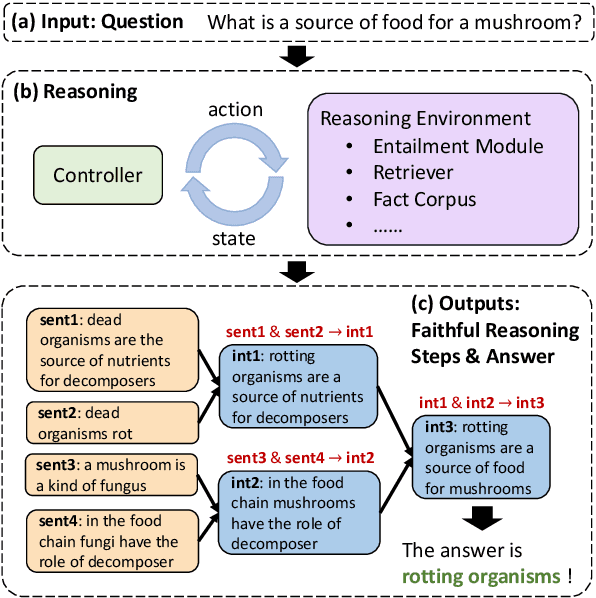

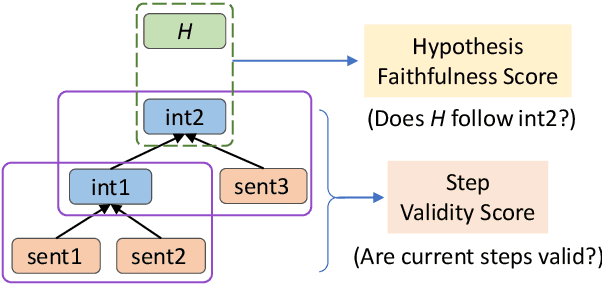
Although large language models demonstrate remarkable question-answering performances, revealing the intermediate reasoning steps that the models faithfully follow remains challenging. In this paper, we propose FAME (FAithful question answering with MontE-carlo planning) to answer questions based on faithful reasoning steps. The reasoning steps are organized as a structured entailment tree, which shows how premises are used to produce intermediate conclusions that can prove the correctness of the answer. We formulate the task as a discrete decision-making problem and solve it through the interaction of a reasoning environment and a controller. The environment is modular and contains several basic task-oriented modules, while the controller proposes actions to assemble the modules. Since the search space could be large, we introduce a Monte-Carlo planning algorithm to do a look-ahead search and select actions that will eventually lead to high-quality steps. FAME achieves state-of-the-art performance on the standard benchmark. It can produce valid and faithful reasoning steps compared with large language models with a much smaller model size.
How and what to learn:The modes of machine learning
Feb 28, 2022
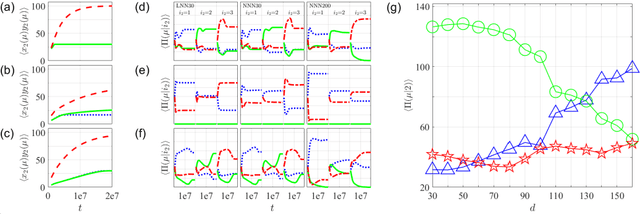
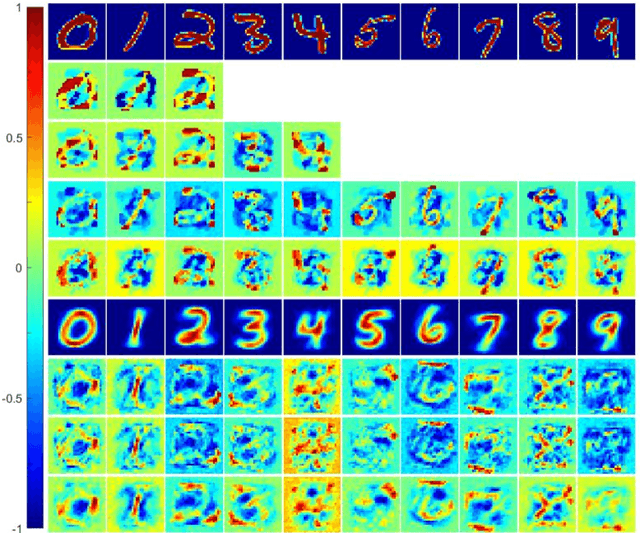
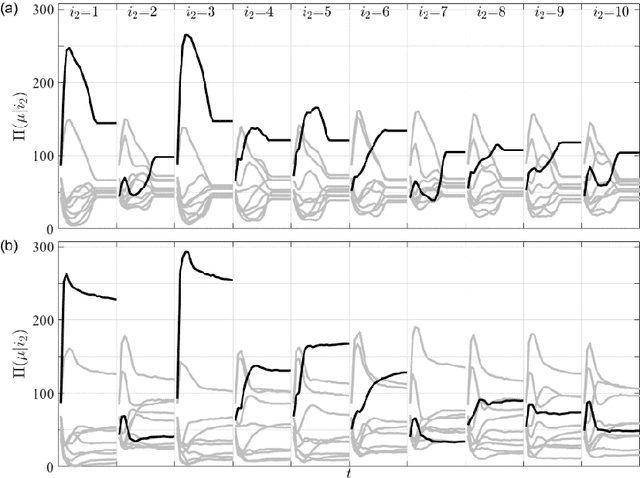
We proposal a new approach, namely the weight pathway analysis (WPA), to study the mechanism of multilayer neural networks. The weight pathways linking neurons longitudinally from input neurons to output neurons are considered as the basic units of a neural network. We decompose a neural network into a series of subnetworks of weight pathways, and establish characteristic maps for these subnetworks. The parameters of a characteristic map can be visualized, providing a longitudinal perspective of the network and making the neural network explainable. Using WPA, we discover that a neural network stores and utilizes information in a "holographic" way, that is, the network encodes all training samples in a coherent structure. An input vector interacts with this "holographic" structure to enhance or suppress each subnetwork which working together to produce the correct activities in the output neurons to recognize the input sample. Furthermore, with WPA, we reveal fundamental learning modes of a neural network: the linear learning mode and the nonlinear learning mode. The former extracts linearly separable features while the latter extracts linearly inseparable features. It is found that hidden-layer neurons self-organize into different classes in the later stages of the learning process. It is further discovered that the key strategy to improve the performance of a neural network is to control the ratio of the two learning modes to match that of the linear and the nonlinear features, and that increasing the width or the depth of a neural network helps this ratio controlling process. This provides theoretical ground for the practice of optimizing a neural network via increasing its width or its depth. The knowledge gained with WPA enables us to understand the fundamental questions such as what to learn, how to learn, and how can learn well.
Channel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation
Dec 24, 2021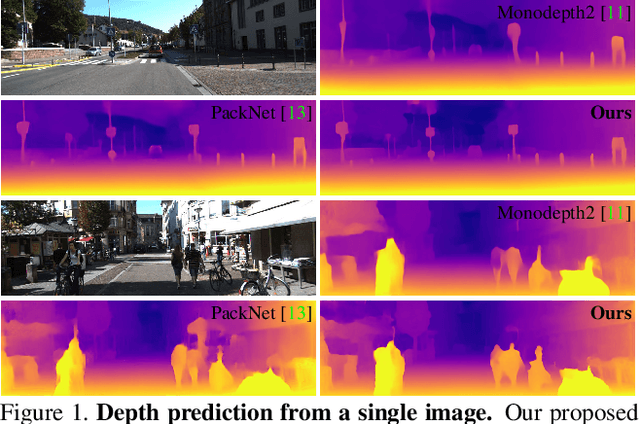
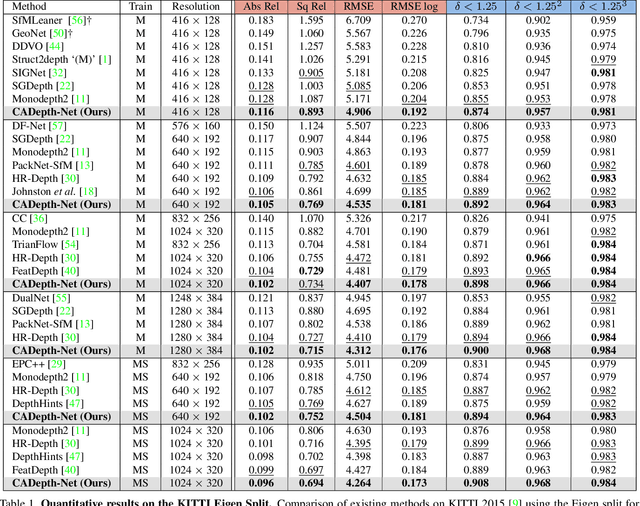
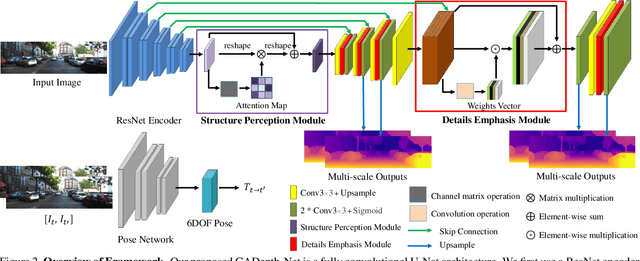
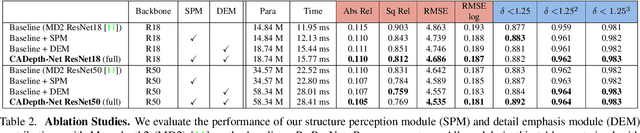
Self-supervised learning has shown very promising results for monocular depth estimation. Scene structure and local details both are significant clues for high-quality depth estimation. Recent works suffer from the lack of explicit modeling of scene structure and proper handling of details information, which leads to a performance bottleneck and blurry artefacts in predicted results. In this paper, we propose the Channel-wise Attention-based Depth Estimation Network (CADepth-Net) with two effective contributions: 1) The structure perception module employs the self-attention mechanism to capture long-range dependencies and aggregates discriminative features in channel dimensions, explicitly enhances the perception of scene structure, obtains the better scene understanding and rich feature representation. 2) The detail emphasis module re-calibrates channel-wise feature maps and selectively emphasizes the informative features, aiming to highlight crucial local details information and fuse different level features more efficiently, resulting in more precise and sharper depth prediction. Furthermore, the extensive experiments validate the effectiveness of our method and show that our model achieves the state-of-the-art results on the KITTI benchmark and Make3D datasets.
Inferring Global Dynamics Using a Learning Machine
Sep 28, 2020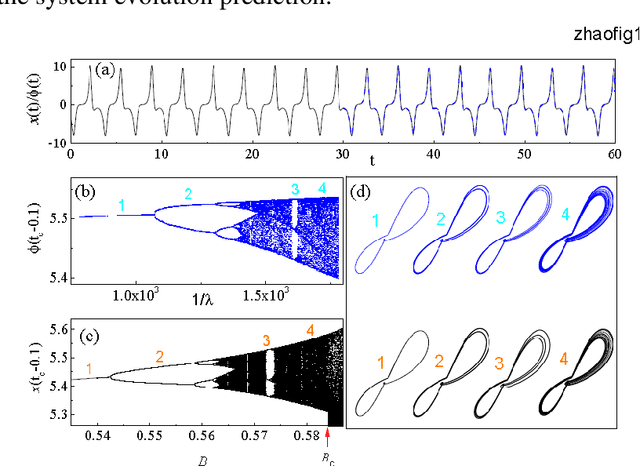
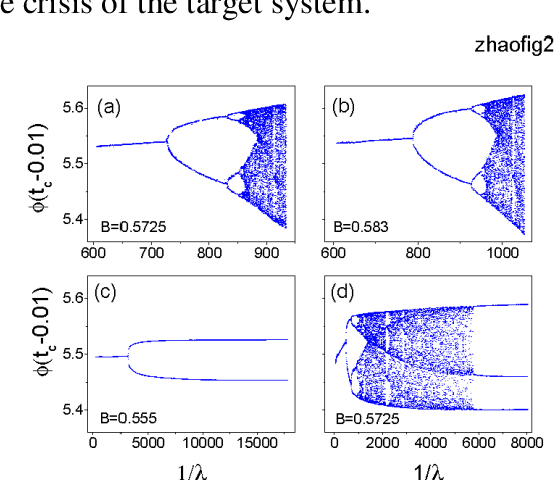
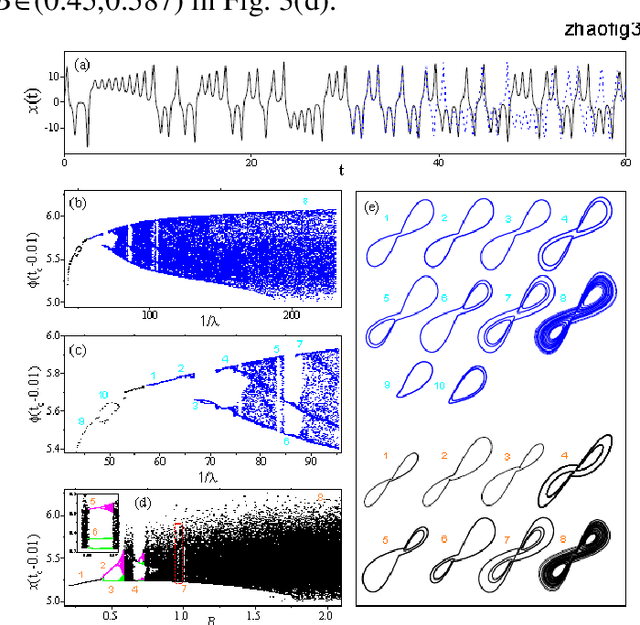
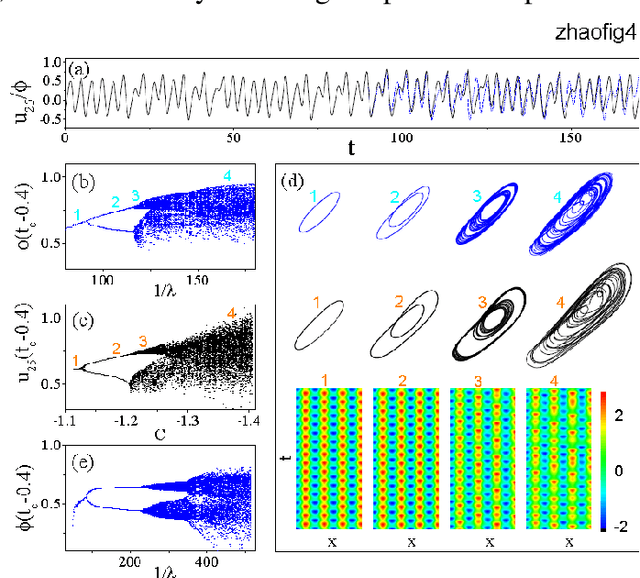
Given a segment of time series of a system at a particular set of parameter values, can one infers the global behavior of the system in its parameter space? Here we show that by using a learning machine we can achieve such a goal to a certain extent. It is found that following an appropriate training strategy that monotonously decreases the cost function, the learning machine in different training stage can mimic the system at different parameter set. Consequently, the global dynamical properties of the system is subsequently revealed, usually in the simple-to-complex order. The underlying mechanism is attributed to the training strategy, which causes the learning machine to collapse to a qualitatively equivalent system of the system behind the time series. Thus, the learning machine opens up a novel way to probe the global dynamical properties of a black-box system without artificially establish the equations of motion. The given illustrating examples include a representative model of low-dimensional nonlinear dynamical systems and a spatiotemporal model of reaction-diffusion systems.
Deep Learning System to Screen Coronavirus Disease 2019 Pneumonia
Feb 21, 2020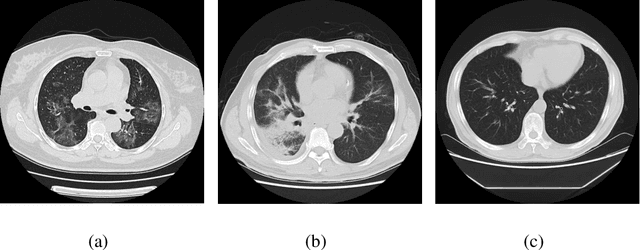
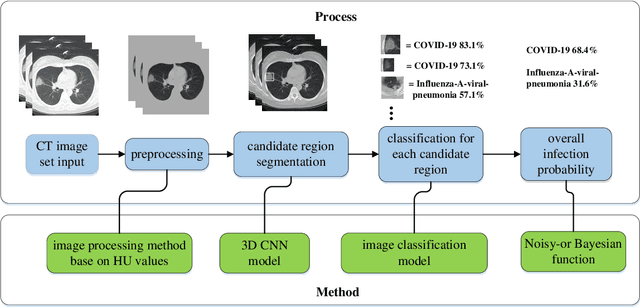

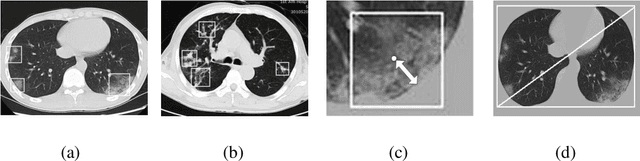
We found that the real time reverse transcription-polymerase chain reaction (RT-PCR) detection of viral RNA from sputum or nasopharyngeal swab has a relatively low positive rate in the early stage to determine COVID-19 (named by the World Health Organization). The manifestations of computed tomography (CT) imaging of COVID-19 had their own characteristics, which are different from other types of viral pneumonia, such as Influenza-A viral pneumonia. Therefore, clinical doctors call for another early diagnostic criteria for this new type of pneumonia as soon as possible.This study aimed to establish an early screening model to distinguish COVID-19 pneumonia from Influenza-A viral pneumonia and healthy cases with pulmonary CT images using deep learning techniques. The candidate infection regions were first segmented out using a 3-dimensional deep learning model from pulmonary CT image set. These separated images were then categorized into COVID-19, Influenza-A viral pneumonia and irrelevant to infection groups, together with the corresponding confidence scores using a location-attention classification model. Finally the infection type and total confidence score of this CT case were calculated with Noisy-or Bayesian function.The experiments result of benchmark dataset showed that the overall accuracy was 86.7 % from the perspective of CT cases as a whole.The deep learning models established in this study were effective for the early screening of COVID-19 patients and demonstrated to be a promising supplementary diagnostic method for frontline clinical doctors.