 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation
Dec 24, 2021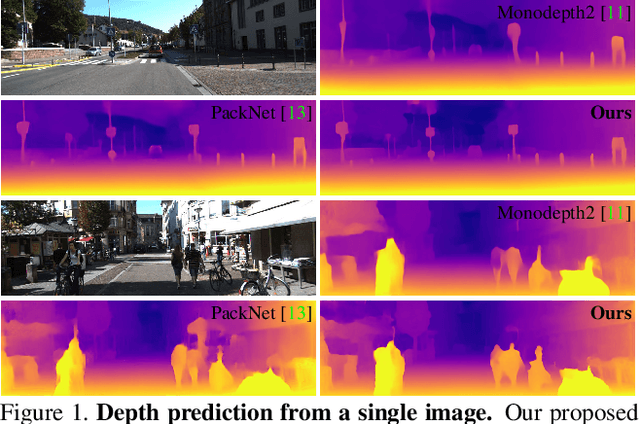
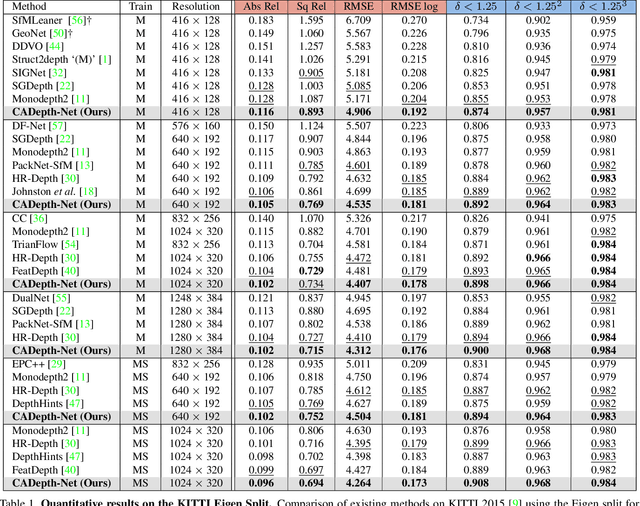
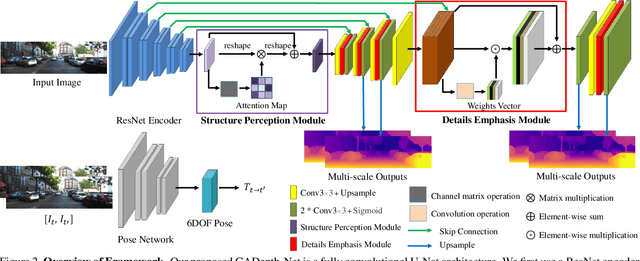
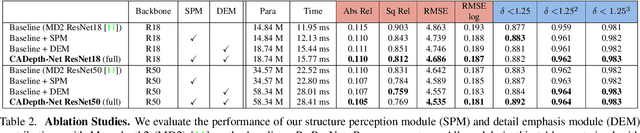
Self-supervised learning has shown very promising results for monocular depth estimation. Scene structure and local details both are significant clues for high-quality depth estimation. Recent works suffer from the lack of explicit modeling of scene structure and proper handling of details information, which leads to a performance bottleneck and blurry artefacts in predicted results. In this paper, we propose the Channel-wise Attention-based Depth Estimation Network (CADepth-Net) with two effective contributions: 1) The structure perception module employs the self-attention mechanism to capture long-range dependencies and aggregates discriminative features in channel dimensions, explicitly enhances the perception of scene structure, obtains the better scene understanding and rich feature representation. 2) The detail emphasis module re-calibrates channel-wise feature maps and selectively emphasizes the informative features, aiming to highlight crucial local details information and fuse different level features more efficiently, resulting in more precise and sharper depth prediction. Furthermore, the extensive experiments validate the effectiveness of our method and show that our model achieves the state-of-the-art results on the KITTI benchmark and Make3D datasets.
Unifying Unsupervised Domain Adaptation and Zero-Shot Visual Recognition
Mar 25, 2019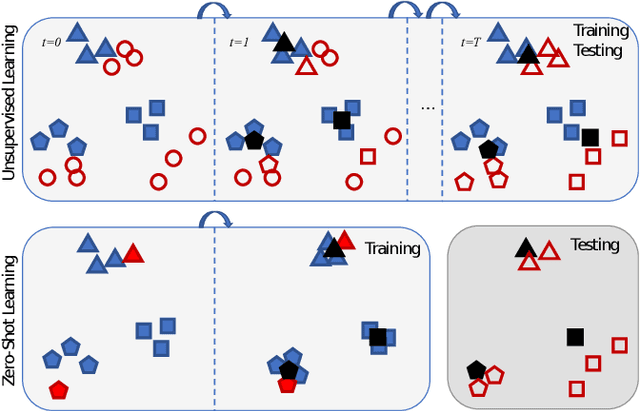

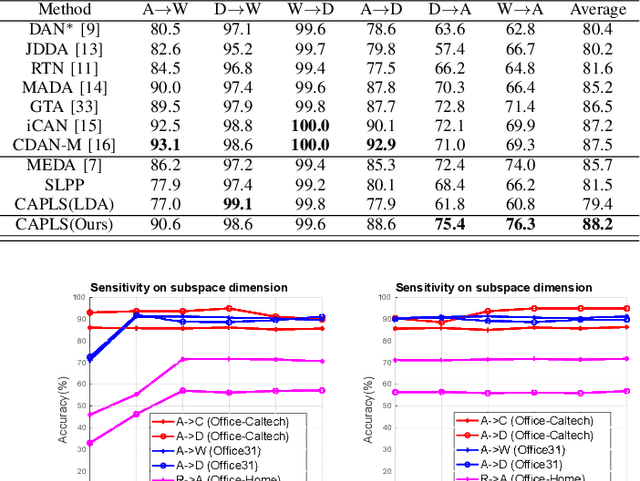

Unsupervised domain adaptation aims to transfer knowledge from a source domain to a target domain so that the target domain data can be recognized without any explicit labelling information for this domain. One limitation of the problem setting is that testing data, despite having no labels, from the target domain is needed during training, which prevents the trained model being directly applied to classify unseen test instances. We formulate a new cross-domain classification problem arising from real-world scenarios where labelled data is available for a subset of classes (known classes) in the target domain, and we expect to recognize new samples belonging to any class (known and unseen classes) once the model is learned. This is a generalized zero-shot learning problem where the side information comes from the source domain in the form of labelled samples instead of class-level semantic representations commonly used in traditional zero-shot learning. We present a unified domain adaptation framework for both unsupervised and zero-shot learning conditions. Our approach learns a joint subspace from source and target domains so that the projections of both data in the subspace can be domain invariant and easily separable. We use the supervised locality preserving projection (SLPP) as the enabling technique and conduct experiments under both unsupervised and zero-shot learning conditions, achieving state-of-the-art results on three domain adaptation benchmark datasets: Office-Caltech, Office31 and Office-Home.