 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Alternated Attention Transformer for Generalized Stereo Matching
Aug 06, 2023Recent stereo matching networks achieves dramatic performance by introducing epipolar line constraint to limit the matching range of dual-view. However, in complicated real-world scenarios, the feature information based on intra-epipolar line alone is too weak to facilitate stereo matching. In this paper, we present a simple but highly effective network called Alternated Attention U-shaped Transformer (AAUformer) to balance the impact of epipolar line in dual and single view respectively for excellent generalization performance. Compared to other models, our model has several main designs: 1) to better liberate the local semantic features of the single-view at pixel level, we introduce window self-attention to break the limits of intra-row self-attention and completely replace the convolutional network for denser features before cross-matching; 2) the multi-scale alternated attention backbone network was designed to extract invariant features in order to achieves the coarse-to-fine matching process for hard-to-discriminate regions. We performed a series of both comparative studies and ablation studies on several mainstream stereo matching datasets. The results demonstrate that our model achieves state-of-the-art on the Scene Flow dataset, and the fine-tuning performance is competitive on the KITTI 2015 dataset. In addition, for cross generalization experiments on synthetic and real-world datasets, our model outperforms several state-of-the-art works.
First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
Jun 23, 2023



Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.
$l_{1-2}$ GLasso: $L_{1-2}$ Regularized Multi-task Graphical Lasso for Joint Estimation of eQTL Mapping and Gene Network
Jan 04, 2023

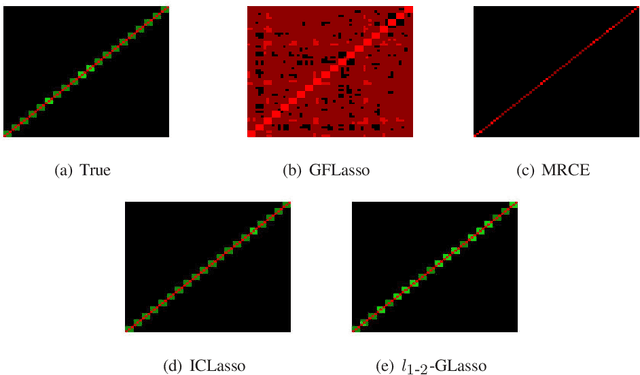

A critical problem in genetics is to discover how gene expression is regulated within cells. Two major tasks of regulatory association learning are : (i) identifying SNP-gene relationships, known as eQTL mapping, and (ii) determining gene-gene relationships, known as gene network estimation. To share information between these two tasks, we focus on the unified model for joint estimation of eQTL mapping and gene network, and propose a $L_{1-2}$ regularized multi-task graphical lasso, named $L_{1-2}$ GLasso. Numerical experiments on artificial datasets demonstrate the competitive performance of $L_{1-2}$ GLasso on capturing the true sparse structure of eQTL mapping and gene network. $L_{1-2}$ GLasso is further applied to real dataset of ADNI-1 and experimental results show that $L_{1 -2}$ GLasso can obtain sparser and more accurate solutions than other commonly-used methods.
Ensemble Recognition in Reproducing Kernel Hilbert Spaces through Aggregated Measurements
Dec 28, 2021

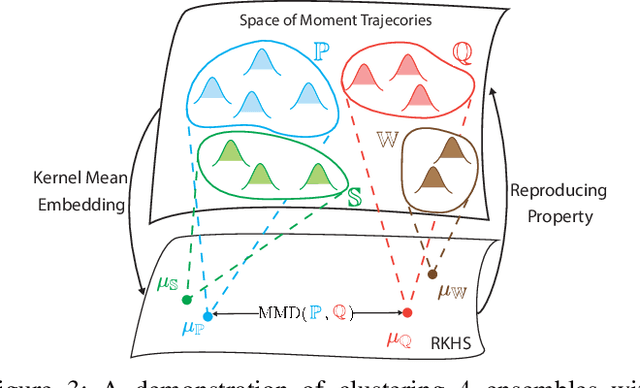

In this paper, we study the problem of learning dynamical properties of ensemble systems from their collective behaviors using statistical approaches in reproducing kernel Hilbert space (RKHS). Specifically, we provide a framework to identify and cluster multiple ensemble systems through computing the maximum mean discrepancy (MMD) between their aggregated measurements in an RKHS, without any prior knowledge of the system dynamics of ensembles. Then, leveraging on a gradient flow of the newly proposed notion of aggregated Markov parameters, we present a systematic framework to recognize and identify an ensemble systems using their linear approximations. Finally, we demonstrate that the proposed approaches can be extended to cluster multiple unknown ensembles in RKHS using their aggregated measurements. Numerical experiments show that our approach is reliable and robust to ensembles with different types of system dynamics.
Interpretable Design of Reservoir Computing Networks using Realization Theory
Dec 13, 2021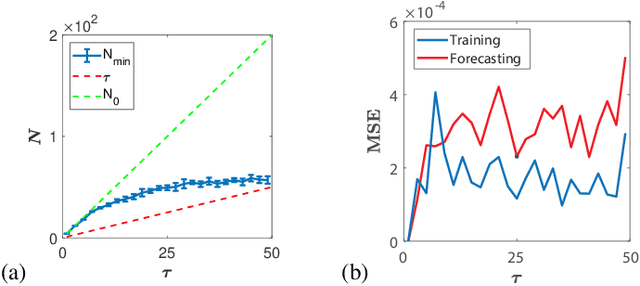


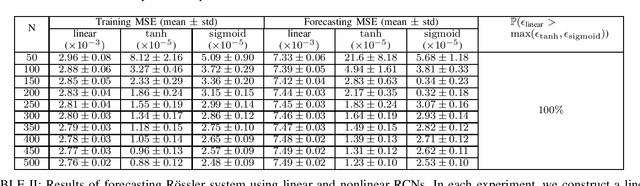
The reservoir computing networks (RCNs) have been successfully employed as a tool in learning and complex decision-making tasks. Despite their efficiency and low training cost, practical applications of RCNs rely heavily on empirical design. In this paper, we develop an algorithm to design RCNs using the realization theory of linear dynamical systems. In particular, we introduce the notion of $\alpha$-stable realization, and provide an efficient approach to prune the size of a linear RCN without deteriorating the training accuracy. Furthermore, we derive a necessary and sufficient condition on the irreducibility of number of hidden nodes in linear RCNs based on the concepts of controllability and observability matrices. Leveraging the linear RCN design, we provide a tractable procedure to realize RCNs with nonlinear activation functions. Finally, we present numerical experiments on forecasting time-delay systems and chaotic systems to validate the proposed RCN design methods and demonstrate their efficacy.